今天的博客主要参考了以下资料:
1 2019年SIGIR会议的《Lifelong Sequential Modeling with Personalized Memorization for User Response Prediction》
2 2018年WSDM会议的《Sequential Recommendation with User Memory Networks》
3 2020年SIGIR会议的《User Behavior Retrieval for Click-Through Rate Prediction》
4 美团到店广告内部的一些分享。
5
https://blog.csdn.net/guoyuhaoaaa/article/details/103270113?spm=1001.2014.3001.5501
众所周知目前在搜广推领域越来越注重用户的个性化建模,目的是使用户在使用系统的时候达到千人前面的效果。而既然要体现出用户的个性化,就必然需要从用户维度提取更多的特征,而用户的行为序列特征作为用户的个性化特征,对其兴趣的刻画有着很大的作用。而且目前工业界的普遍认知是:越长的行为序列对于兴趣的迁移刻画有着更加重要的影响。更加长的行为序列往往意味着更加复杂的序列编码结构,意味着更高的模型复杂度,这样的特性给序列抽取的落地带来了很大的挑战。
目前世面上主流的长序列行为建模有2种处理范式:
1 预压缩编码范式;往往通过近线系统将每个用户行为序列压缩在n 个slot空间中,在线计算用户兴趣的时候,直接取target poi和这n个slot向量计算相似度进行聚合。这其中的代表有memory network,胶囊网络等。
2 检索子序列范式;根据业务特点,利用某一个特定的检索条件从用户的长历史行为序列中检索抽取出一个子序列,其假前提是用户的历史行为序列并不都对当前场景的推荐有影响,而只有其中符合检索条件的子序列才有较大的影响。如何指定合理的检索条件,这就要求对业务有着较深的理解了。
要实现第一种范式,其中深度学习里的memory network框架是一个不错的工具。下面先来简单介绍一下memory network应用在用户行为序列建模上的经典工作原理:
每一个用户都对应了一个矩阵
M
u
∈
K
∗
D
M^u\in K*D
M
u
∈
K
∗
D
,其中K代表了slot的个数,D代表了每个slot中向量的维度。
memory network框架下的基础操作分为读操作和写操作。当用户在线点击了一个又一个item的时候,这些商品就会在写操作的控制逻辑下写入到每个用户对应的memory network中去;而当用户向搜索推荐系统发起新的请求的时候,这时整个搜索推荐系统会使用读操作从memory network中取出和用户相关的表征向量,用于后阶段的交互操作。
下面来详细讲解一下具体的操作细节。假设有一个全局的潜在语义矩阵
F
=
{
f
1
,
f
2
.
.
.
f
K
}
F=\{f_1,f_2…f_K\}
F
=
{
f
1
,
f
2
.
.
.
f
K
}
,其中每一个f向量的维度也是
D
D
D
,假设这时候有一个目标商品
q
i
q_i
q
i
(在读取阶段,目标商品就代表当前待预测的商品;在写入阶段,目标商品就代表当前用户点击的商品),会和全局的潜在语义矩阵中的每一个slot中的元素计算相似度,并使用softmax归一化得到一个相似度分数:
w
i
k
=
q
i
T
w_{ik}=q_i^T
w
i
k
=
q
i
T
,
z
i
k
=
e
x
p
(
β
w
i
k
)
∑
j
e
x
p
(
β
w
i
j
)
z_{ik}=\frac{exp(\beta w_{ik})}{\sum_j exp(\beta w_{ij})}
z
i
k
=
∑
j
e
x
p
(
β
w
i
j
)
e
x
p
(
β
w
i
k
)
上述公式里得到的
z
i
k
z_{ik}
z
i
k
作为商品和每一个slot的相似性,会在写入和读取阶段都发挥较为重要的作用。
写操作流程:假设
q
i
q_i
q
i
为当前用户点击的商品,那么对于该用户又会分别有一个erase操作和一个add操作,即根据目标商品信息将用户各个slot无关的信息擦除,然后再根据目标为每个slot定向增加信息:
e
r
a
s
e
i
=
σ
(
E
T
q
i
+
b
e
)
erase_i=\sigma(E^Tq_i+b_e)
e
r
a
s
e
i
=
σ
(
E
T
q
i
+
b
e
)
//擦除参数
m
k
u
=
m
k
u
⨀
(
1
−
z
i
k
.
e
r
a
s
e
i
)
m_k^u=m_k^u \bigodot(1-z_{ik}.erase_i)
m
k
u
=
m
k
u
⨀
(
1
−
z
i
k
.
e
r
a
s
e
i
)
//对每一个slot进行擦除
a
d
d
i
=
t
a
n
h
(
A
T
q
i
+
b
a
)
add_i=tanh(A^Tq_i+b_a)
a
d
d
i
=
t
a
n
h
(
A
T
q
i
+
b
a
)
// 相加参数
m
k
u
=
m
k
u
+
z
i
k
.
a
d
d
i
m_k^u=m_k^u+z_{ik}.add_i
m
k
u
=
m
k
u
+
z
i
k
.
a
d
d
i
// 对每一个slot添加信息
读操作流程:这时
q
i
q_i
q
i
代表了待预测的目标商品信息,然后直接根据和全局潜在语义矩阵计算出的相似度
z
i
k
z_{ik}
z
i
k
,用其对用户矩阵slot进行加权求和得到最终的用户表征:
p
u
m
=
∑
k
=
1
K
z
i
k
.
m
K
u
p_u^m=\sum_{k=1}^Kz_{ik}.m_K^u
p
u
m
=
∑
k
=
1
K
z
i
k
.
m
K
u
最终得到的用户表征,就作为长序列用户行为的聚合结果,和其他特征拼接后输入到后续的MLP网络中去。
其实
阿里的MIMN
就是在memory network的基础上扩展而来的,感兴趣的同学可以看我之前的博客。
下面来讲解一篇阿里和上海交通大学合作的paper《Lifelong Sequential Modeling with Personalized Memorization for User Response Prediction》,同样目标是把用户行为序列压缩到固定参数矩阵的方法。所不同的是,这里底层的实现框架不再是基于memory network框架,而是使用了多层的GRU。
按照作者的说法,用户的行为序列体现了用户的多种兴趣偏好,具有多层次、跨周期、多维度的特点。因为用户购买不同商品的周期是不一样的,用户的兴趣变化的周期也是不一样的,如果使用单层的GRU则无法完成对于用户复杂行为范式的刻画,因为并不是所有的偏好是在同一个范式周期下进行演化和递进,故采用了”多层次化的“ GRU模式:
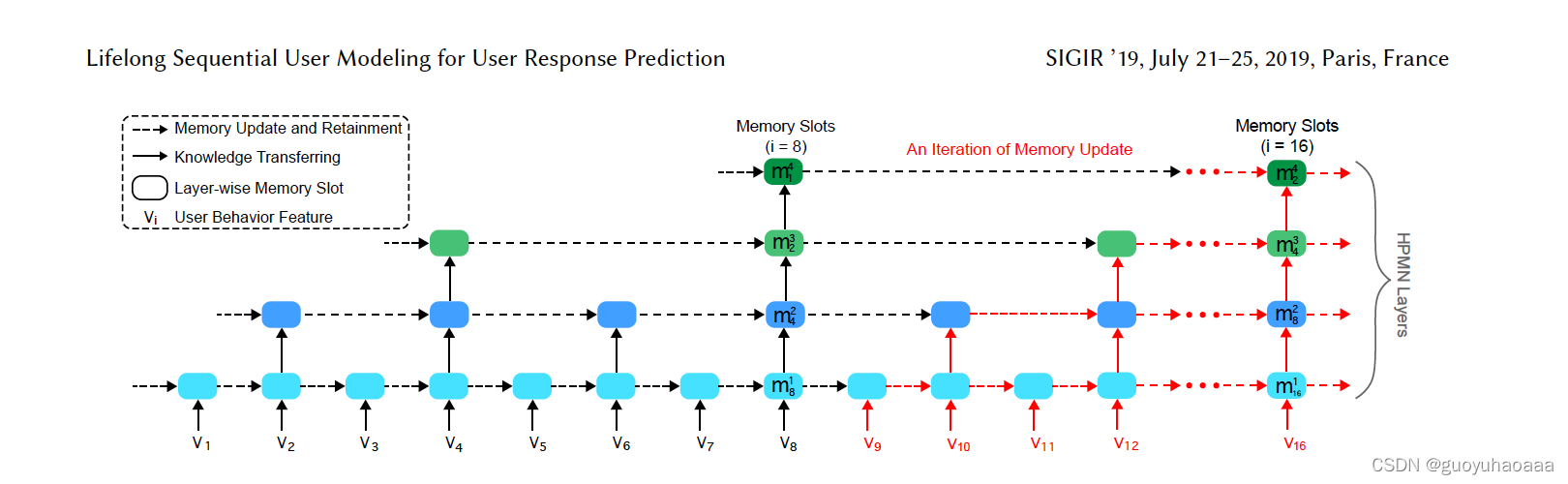
这里使用”层次化“GRU对行为序列的编码结果形式也是一个由多个slot组成的参数矩阵,slot的数量代表了周期的数量,同样也对应了GRU的数量。每一层GRU针对了不同周期下的用户行为的建模,
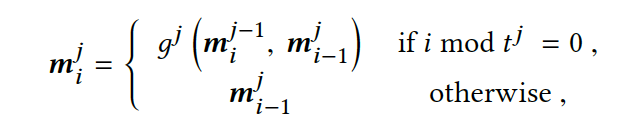
上述公式中,j代表了层次数,i代表了第i个时刻的行为,
t
j
t^j
t
j
代表了第j层GRU的建模周期。
这样不同周期的GRU最后时刻的隐藏层输出就代表了不同行为周期视角下的用户行为偏好。
同时为了使得不同周期下提取特征具有一定差异性,又加入了一个辅助loss,即将每一个slot看成是一个特征,然后最小化slot和slot之间的协方差:
C
=
1
P
(
M
−
M
−
)
(
M
−
M
−
)
T
C=\frac{1}{P}(M-M^{-})(M-M^{-})^T
C
=
P
1
(
M
−
M
−
)
(
M
−
M
−
)
T
,其中
M
M
M
代表了用户的压测的行为序列参数矩阵。
L
c
=
1
2
(
∣
∣
C
∣
∣
F
2
−
∣
∣
d
i
a
g
(
C
)
∣
∣
2
2
)
L_c=\frac{1}{2}(||C||_F^2-||diag(C)||_2^2)
L
c
=
2
1
(
∣
∣
C
∣
∣
F
2
−
∣
∣
d
i
a
g
(
C
)
∣
∣
2
2
)
这样使得提取的不同周期下的用户兴趣向量之间的相关性是最小的。
目前基于multi-head + self_attention 的transformer在NLP领域比较火,特别是在大模型预训练领域取得了不错的效果。很快同时也有很多工作将transformer引入到了推荐搜索领域中的用户行为序列建模中来。美团的到店广告团队,利用transformer作为底层的编码工具,从原始训练中抽取不同业务维度的序列,然后利用self-attention + mean-pooling的方法得不同业务视角下子序列的聚合结果。如何划分定义抽取子序列的业务维度,有赖于对业务的高度熟悉。相比于上面的两种方法,这种方法得到的用户预压缩编码向量更具有业务上的可解释性(能够清楚的知道,抽取得到的用户行为参数矩阵的每一个向量都代表反应了用户哪些维度方面的属性信息)。
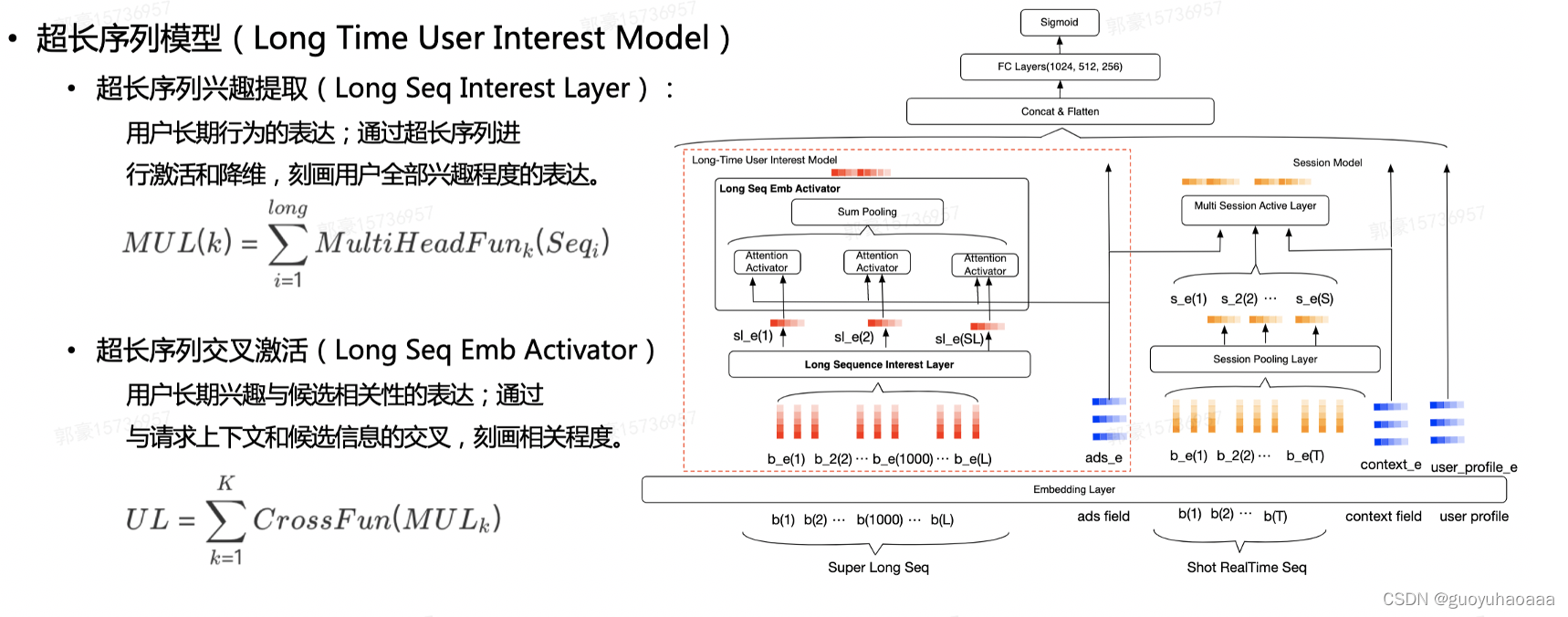
总之,预压缩编码方式都是将用户的原始行为序列压缩的固定的矩阵参数
M
∈
K
∗
D
M\in K*D
M
∈
K
∗
D
中去,
K
K
K
的数量代表了描述用户的不同维度。在《Lifelong Sequential Modeling with Personalized Memorization for User Response Prediction》中代表了用户不同跨度周期下的兴趣,而阿里的MIMN代表了用户不同维度的兴趣偏好(感觉可解释性不太强)。而美团的这个内部工作,我觉得业务可解释性是最强,你抽取的是什么业务视角下的序列。
很明显看出,预压缩编码有在使用的时候有一个最大的问题。那就是在压缩用户行为向量的过程中,缺乏了待预测候选poi和压缩前的原始序列里poi的细粒度交互信息,而上层模型利用的只能是待预测候选poi和压缩后的向量的交互,很多更加细节的交互信息模型是很那感知的。而这个缺点,是所有预压缩编码范式都有的,而且是无法避免的。
上面讲解了预压缩编码范式的处理方法,接下来介绍一下基于检索字序列范式下的用户长周期序列建模工作。其中比较有代表性的有
阿里的SIM
。具体细节可以看超链接里的内容,这里介绍另一种基于检索思路的paper《User Behavior Retrieval for Click-Through Rate Prediction》,这也是上海交通大学张伟楠老师团队又一工作。整个模型分为2大模块:
User Behavior Retrieval Module
和
Prediction Module
。
下面分别来讲解这两大模块:
User Behavior Retrieval Module
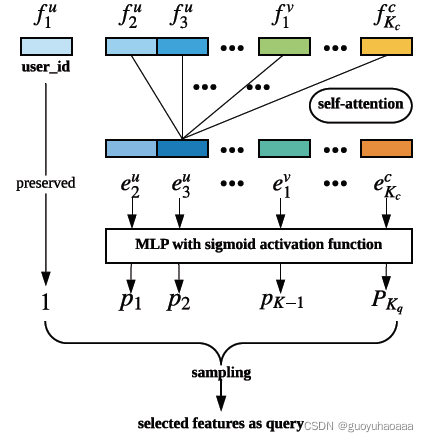
从上往下看,输入域的向量
[
f
1
u
,
.
.
.
.
f
K
u
u
,
f
1
v
,
.
.
.
f
K
V
v
,
f
1
c
,
.
.
.
.
f
K
c
c
]
[f_1^u,….f_{K_u}^u,f_1^v,…f_{K_V}^v,f_1^c,….f_{K_c}^c]
[
f
1
u
,
.
.
.
.
f
K
u
u
,
f
1
v
,
.
.
.
f
K
V
v
,
f
1
c
,
.
.
.
.
f
K
c
c
]
,分别代表了模型输入域的用户特征,上下文特征和item特征。然后经过一层self-attention来建模不同特征域之间的交互信息,最后通过MLP+Sigmoid范式得到每一个域的概率值。最后按照这个概率值对原来的特征域的每个特征进行抽样,得到一个原始特征域的子集。
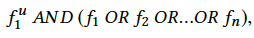
这里的
f
1
u
f_1^u
f
1
u
代表了用户的id信息。然后按照上述条件去用户的历史点击行为序列里进行检索匹配,需要注意的是这里的用户历史行为序列不仅仅是点击的poi的id序列,这里定义的序列信息
H
u
=
{
b
1
u
,
b
2
u
,
.
.
.
b
t
u
}
H_u=\{ b_1^u,b_2^u,…b_t^u\}
H
u
=
{
b
1
u
,
b
2
u
,
.
.
.
b
t
u
}
会更加的丰富,其中
b
i
u
=
[
u
,
v
i
,
c
i
]
b_i^u=[u,v_i,c_i]
b
i
u
=
[
u
,
v
i
,
c
i
]
,即点击时刻的用户属性,item属性和点击时刻的上下文属性。
这样根据挖掘出的特征子集去较为丰富的用户行为序列中进行检索匹配,得到一个序列的子集。然后输入到后续的Prediction Module模块中去:
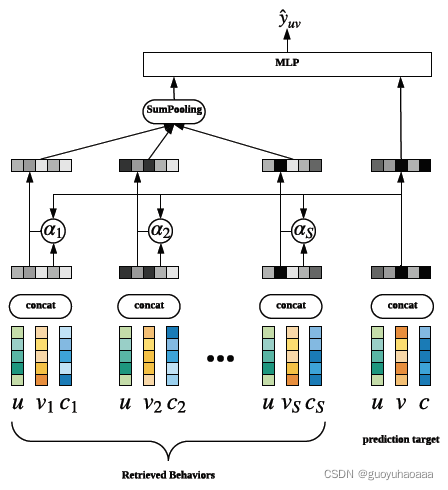
这里的Prediction Module结构比较清晰明了,和DIN的处理思路几乎是一模一样的。
最后需要说明一点的是,这里的
User Behavior Retrieval Module
和
Prediction Module
并不是传统意义上的端到端的模式,是无法利用梯度传播算法进行训练的。特别是
User Behavior Retrieval Module
部分的参数的学习借鉴了强化学习训练的思想。
我理解这里
User Behavior Retrieval Module
和
Prediction Module
2个模块的训练利用了bootStrap的思想,即迭代的训练,固定住一部分参数训练另一部分。
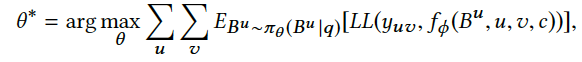
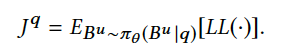
上述公式中
L
L
(
.
)
LL(.)
L
L
(
.
)
代表了
Prediction Module
阶段计算出的损失函数。
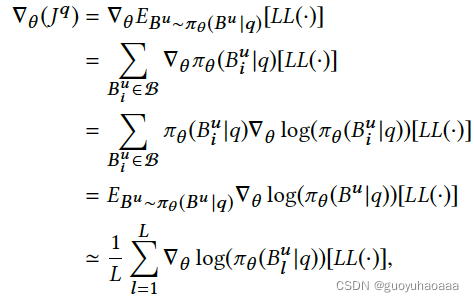
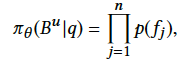
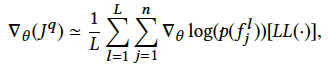
在训练
User Behavior Retrieval Module
的时候,
Prediction Module
阶段的模型参数是固定住的。
最后来讲解一下美团到店广告团队在子序列检索范式下的实践:
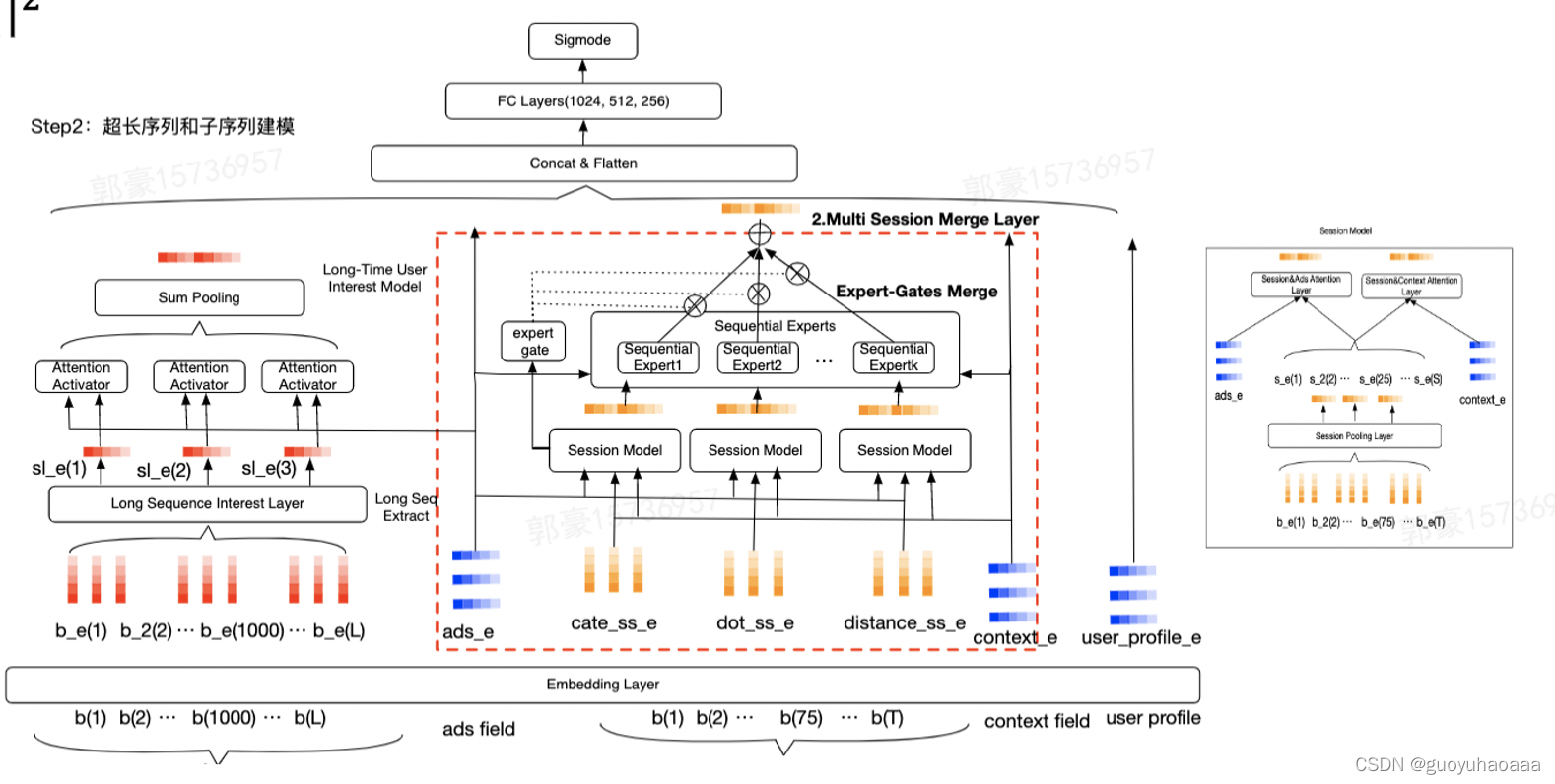
整体检索思路和阿里的SIM是非常相似的,不过这里加入了多个条件对原始的用户超长行为序列进行检索。这样可以得到关于用户原始行为序列不同维度的特性,然后对编码后的结果利用多expert的模式进行融合。可以看成是SIM版本的复杂化、多样化的扩展。
上述工作大致汇总了一下目前工业级针对超长行为用户行为序列建模的工作。感兴趣的小伙伴可以多多交流。个人结合工作上的看法,还是认为用户行为序列是对用户个性化的最好表达。