首先要区分与js的数据类型。
基本数据类型:Number, String, Boolean, Null, Undefined。
引用数据类型:Array, Object, Function等
那么这两类数据类型有什么不一样呢?
基本数据类型是指存放在
栈
中的
简单数据段,数据大小确定,内存空间大小可以分配,
它们是直接按值存放的,所以可以直接
按值访问。
引用类型是存放在
堆
内存中的对象,变量其实是保存的在栈内存中的一个指针(保存的是堆内存中的引用地址),这个指针指向堆内存。引用数据类型数据创建的时候大小不确定。

接下来就介绍浅拷贝与深拷贝
浅拷贝,深拷贝是相对于引用数据类型来说的。
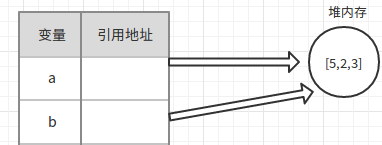
在定义一个对象或数组时,变量存放的往往只是一个地址。
浅拷贝
:简单来说就是把a的值赋给b, a改变的时候b也改变了。

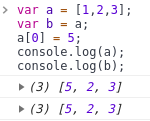
从上图可以看到,第一次的时候,a改变了b却没有改变,是因为赋值a=[4,5]把a重新指到了另外一个地址。
而第二次的时候,b随着a改变了,是因为a进入到引用的地址把[0]修改了,b与a指向同一个地址,所以b=[5,2,3];
(补充一点,
Array.form()
方法也可以实现浅拷贝,
Array.from()
方法从一个类似数组或可迭代对象中创建一个新的,浅拷贝的数组实例。)
深拷贝:
创建一个新的对象和数组,将原对象的各项属性的“值”(数组的所有元素)拷贝过来,是“值”而不是“引用”
(
就是a的值改变与不会对b产生影响)
我们在使用深拷贝的时候,一定要弄清楚我们对深拷贝的要求程度:
是仅“深”拷贝第一层级的对象属性或数组元素
,
还是递归拷贝所有层级的对象属性和数组元素?
那如何实现深拷贝,拷贝的方式及其分类呢
1. array.slice()

2. array.concat()

这两种方式都会返回数组的副本,是第一层拷贝,只对数组元素是基本类型变量(如number,String,boolean)的简单数组有效。
对第一级数组元素是对象或者数组等引用类型变量的数组无效。

如上图,a进入内存地址修改[0]中的String类型值的时候,b中的[0]没有被改变,
但是修改a[1]中的对象时,b[2]也被改变了,就是无效。
3.Object.assign()
, 这个方法是对对象的复制
(1)先看看只有一层的情况
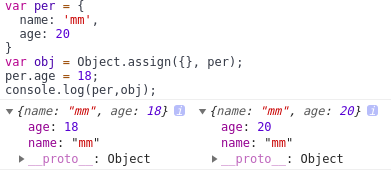
结果如上所示,object.assign()对第一层是深拷贝,改变per.age并不会影响obj.age;
(2)再来看看有两层的情况
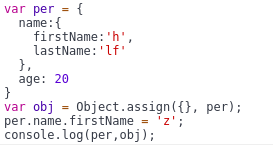
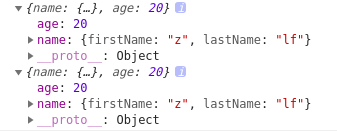
结果如上所示,第二层就失效了。
那有哪些可以拷贝所有层级对象和属性的方法呢?
1. JSON.parse(JSON.stringify( ));

那为什么它可以拷贝每次层的对象和属性呢?
利用JSON.stringify将对象序列化(JSON字符串),再使用JSON.parse来反序列化还原js对象。序列化的作用是存储和传输。
(不拷贝引用对象,拷贝一个字符串会新辟一个新的存储地址,这样就切断了引用对象的指针联系。)
这样进行拷贝也是有其局限性。当值为
undefined
、
function
、
symbol
会在转换过程中被忽略。
2.递归
function deepCopy(obj) {
var result = Array.isArray(obj) ? [] : {};
for (var key in obj) {
if (obj.hasOwnProperty(key)) {
if (typeof obj[key] === 'object' && obj[key]!==null) {
result[key] = deepCopy(obj[key]); //递归复制
} else {
result[key] = obj[key]; //普通类型直接赋值
}
}
}
return result;
}
存在大量深拷贝需求的代码——immutable提供的解决方案
实际上,即使我们知道了如何在各种情况下进行深拷贝,我们也仍然面临一些问题: 深拷贝实际上是很消耗性能的
。(我们可能只是希望改变新数组里的其中一个元素的时候不影响原数组,但却被迫要把整个原数组都拷贝一遍,这不是一种浪费吗?)
所以,当你的项目里有大量深拷贝需求的时候,性能就可能形成了一个制约的瓶颈了。
immutable的作用
:
通过immutable引入的一套API,实现:
1.在改变新的数组(对象)的时候,不改变原数组(对象)
2.在大量深拷贝操作中显著地减少性能消耗
const { Map } = require('immutable')
const map1 = Map({ a: 1, b: 2, c: 3 })
const map2 = map1.set('b', 50)
map1.get('b') // 2
map2.get('b') // 50查阅了很多资料与文章,如有侵权请联系。