一、算法简介
TextRank算法
是一种
基于图
的
排序算法
,由谷歌的网页
重要性排序算法
PageRank算法改进而来,主要应用有关键词提取、文本摘要抽取等。该算法的
主要思想
是:把文档中的词(句)看成一个网络,词(句)之间的语义关系为网络之间的链接。通过
迭代计算获得权重值
(
依旧依赖词频,
通常词频越高计算的权重值越高,一般需要进行
停用词处理
)公式如下:
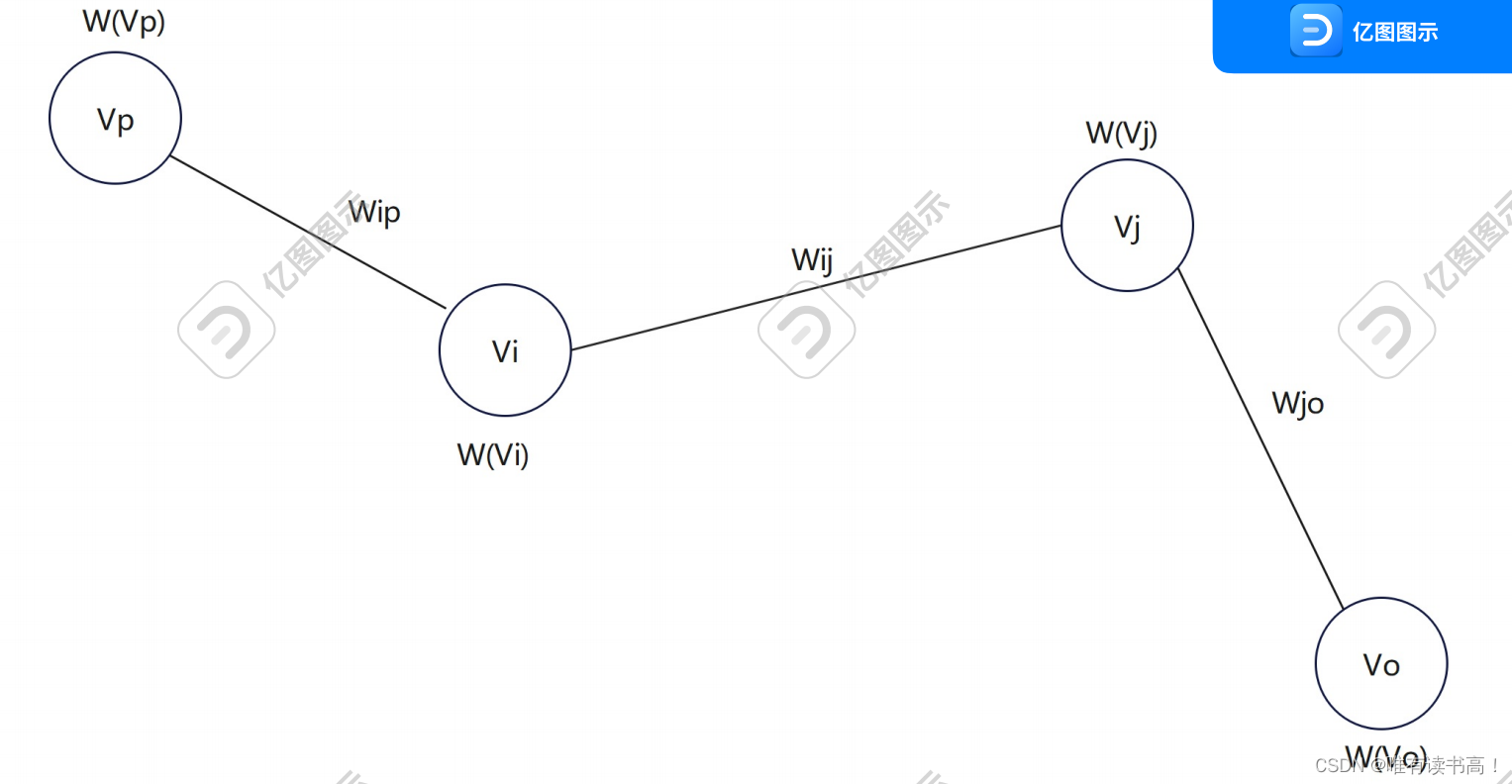
其中,
为节点
的权重值、
为学习率(一般为0.85)、
,
分别表示节点
和节点
、
表示所有指向节点
的节点、
表示节点
和节点
的链接的权重值。
也可以理解成无向图的形式:
为两节点的边权重值,
为节点,
为节点权重值、
为所有与节点
连接的边权值之和(主要是为了归一化操作,不理解的通过以下代码的运行去解读)。如下图所示:
优缺点:
优:
- textrank只依赖文章本身,它认为一开始每个词的重要程度是一样的。
- 继承了PageRank的思想,效果相对较好,相对于TF-IDF方法,可以更充分的利用文本元 素之间的关系。
- 无监督方式,无需构造数据集训练。
缺:
- 结果受分词、文本清洗影响较大,即对于某些停用词的保留与否,直接影响最终结果。
- 虽然与TF-IDF比,不止利用了词频,但是仍然受高频词的影响,因此需要结合词性和词频进行筛选,以达到更好效果,但词性标注显然又是一个问题。
二、TextRank关键词提取步骤及实现
其实
摘要抽取
与
关键词提取
的
原理
是
一样
的,无非就是文本细粒度的不同,通过句子的词权值相加(或者取平均值,记不清了,个人觉得取平均值比较靠谱)的结果为句子权重,再根据句子权重从大到小提取一定数量的句子为摘要。
关键词提取具体步骤如下:
1、把给定的文本T按照完整句子进行分割,即T=[
,
,…,
]
2、对于每个句子S; ∈T,进行分词和词性标注处理,并过滤掉停用词,只保留指定词性的单词,如名词、动词、形容词,即S =[
,
,…,
],其中
是保留后的候选关键词。
3、构建候选关键词图G=(V,E),其中V为节点集,由上步生成的候选关键词组成,然后采用共现关系构造任两点之间的边,两个节点之间存在边仅当它们对应的词汇在长度为k的窗口中共现,k表示窗口大小,即最多共现k个单词。
4、根据上面的公式,迭代传播各节点的权重,直至收敛。
5、对节点权重进行倒序排列,从而得到最重要的T个单词,作为候选关键词。
6、由上步得到最重要的T个单词,在原始文本中进行标记,若形成相邻词组,则组合成多词关键词
import numpy as np
import jieba.posseg as pseg
class TextRank(object):
def __init__(self, sentence, window, learn_rate, iterations):
self.sentence = sentence
self.window = window
self.learn_rate = learn_rate
self.edge_dict = {} # 记录节点的边连接字典
self.iterations = iterations # 迭代次数
def createNodes(self):
# 对句子进行分词
# jieba.load_userdict('user_dict.txt')
# 这里进行了停用词处理,只保留的规定词性的词
tag_filter = ['a', 'd', 'n', 'v']
seg_result = pseg.cut(self.sentence)
self.word_list = [s.word for s in seg_result if s.flag in tag_filter]
print(self.word_list)
# 根据窗口,构建每个节点的相邻节点,返回边的集合
tmp_list = []
word_list_len = len(self.word_list)
for index, word in enumerate(self.word_list): #遍历句子的词
if word not in self.edge_dict.keys(): #判断该词(中心词)是否处理过
tmp_list.append(word)
tmp_set = set()
left = index - self.window + 1 # 窗口左边界
right = index + self.window # 窗口右边界
# 规范窗口边界
if left < 0: left = 0
if right >= word_list_len: right = word_list_len
#查找窗口内除中心点意外的点
for i in range(left, right):
if i == index: #判断该点是不是中心点,是就跳过
continue
else:
tmp_set.add(self.word_list[i]) #记录非中心点,集合可以去重
self.edge_dict[word] = tmp_set #记录中心点周围点{'中心点1':{'周围点1','周围点2',...},'中心点2':{'周围点1','周围点2',...}}
# 根据边的相连关系,构建矩阵
def createMatrix(self):
self.matrix = np.zeros([len(set(self.word_list)), len(set(self.word_list))])
self.word_index = {} # 记录词的index
self.index_dict = {} # 记录节点index对应的词
#构建点和边的双向索引
for i, v in enumerate(set(self.word_list)):
self.word_index[v] = i
self.index_dict[i] = v
#构建无向图
for key in self.edge_dict.keys(): #查找中心点
for w in self.edge_dict[key]: #查找中心点对应的周围点
self.matrix[self.word_index[key]][self.word_index[w]] = 1 #建立无向便,有边为1,反之为0
self.matrix[self.word_index[w]][self.word_index[key]] = 1 #无相边的矩阵为对角矩阵
# 根据textrank公式计算权重并输出结果
def call(self):
# 归一化(按公式里对j节点归一化)
sum = np.sum(self.matrix, axis=0) # 按列求和
for j in range(self.matrix.shape[1]):
for i in range(self.matrix.shape[0]):
self.matrix[i][j] /= sum[j] # 按列归一化
self.nodeI = np.ones([len(set(self.word_list))])
for i in range(self.iterations): #公式
self.nodeI = (1 - self.learn_rate) + self.learn_rate * np.dot(self.matrix, self.nodeI)
# 输出词和相应的权重
word_pr = {}
for i in range(len(self.nodeI)):
word_pr[self.index_dict[i]] = self.nodeI[i]
#items()函数返回列表里嵌套(键,值)元组
res = sorted(word_pr.items(), key=lambda x: x[1], reverse=True) #对列表进行临时排序,reverse选择降序
print(res)
if __name__ == '__main__':
s = '情感分析又称倾向性分析或观点挖掘,是一种重要的信息分析处理技术,其研究目的是自动挖掘文本中的立场、观点、看法、情绪和喜恶等。在情感状态的理论研究中,情感状态的主要表示方法有两种:离散类别型表示方法和维度连续型表示方法。'
TextRank = TextRank(s, 3, 0.85, 700)
TextRank.createNodes()
TextRank.createMatrix()
TextRank.call()