Scala
基础
- 变量声明:
val str="abc"
val str:String = "abc"
- 列表:
val list: List[Any] = List("abc",1,true)
-
数据类型转换顺序:
byte–>short–>int–>long–>float–>double
char–>int - 条件语句:
val x = if(i>0) 100 else 0
- 块表达式:
val result={
val a=1
val b=2
a+b
}
- for循环:
for(i<-1 to 5) println(i) //1,2,3,4,5
for(i<-1 until 5) println(i) //1,2,3,4
//嵌套for
for(i<-1 to 5;j<-1 to 4) println(j)
while循环:
while(i<5){
println(i)
i=i+1
}
- 方法
def method(a:Int,b:Int) : Int={
return a+b //return可省略
}
def method(a:Int,b:Int) : Unit={
println(100)
}
//传入多个类型相同参数
def method(a:String,b:Int*)={
println(b)
var res=0
for(i<-b) res=res+i
a+res
}
method("abc",1,2,3) //array[1,2,3] 结果:abc6
method("abc",arr:_*) //传入的本身就是数组
- 函数
(a:Int,b:Int) => a+b
val f1=(a:Int,b:Int) => {a+b}
f1(1,2)
*函数可以作为参数传入方法
方法–>函数:
def m2(x:Int,y:Int) = x+y //定义方法2
def m1(f:(Int,Int)=>Int):Int={
f(2,6)
} //定义方法1
val res=m1(m2) //传入的参数为方法m2,此时m2自动变为函数
val f=m2 _ //手动转换
数组
val arr=Array(1,2,3)
val arr=new Array[Int](3) //定长数组
val arr = new ArrayBuffer[Int]() //变长数组,需要import scala.collection.mutable.ArrayBuffer
数组基本操作:
遍历数组:for(i<-arr)
添加元素:arr+=1
删除值元素:arr-=1 //一次删除一个,从前向后
合并数组:arr1++=arr2
插入元素:arr.insert(0,1,2) //第一个参数为index
删除位置元素:arr.remove(1,2) //第二个参数为删除的元素个数
常用方法:sum, max, min, sorted, sorted.reverse
列表
(默认使用不可变)
val nums: List[Int] = List(1,2,3,4)
头部添加:val nums1=nums.+:(1)
尾部添加:val nums2=nums:+1
合并:val nums3 = nums1++:nums2
Map
类似字典、哈希表
val mp = Map(
"key1" -> "value1",
"key2" -> "value2"
}
或者
val mp = Map(
("key1" , "value1"),
("key2" , "value2")
}
mp.keys.foreach{i=> ...} //迭代
for((k,v)<-mp) //简易迭代
元组
val t=(1,"abc",2.1) //数据类型可以不同
取数:t._1
迭代:t.productIterator.foreach{i=> ...}
转换为字符串:t.toString()
元组最大长度22
集合
val set = Set(1,2,3)
增加元素:val set1 = set+1
删除元素:val set2 = set-1
连接:set1++set2
常用方法:set.head(头元素),set.tail(除头元素),set.isEmpty,set.max,min,set.&或intersect(set1) (交集)
类
class User{
private var age=10
def count(){
age+=1
}
}
new User()
//单例对象
object Person{
private var name="abc"
def showInfo():Unit={
println(name)
}
}
//方法调用
Person.showInfo()
*当类和单例对象名字相同时,称为伴生,可以互相访问私有成员
Spark RDD
创建
- 从对象集合创建:
//通过列表创建
val rdd=sc.parallelize(List(1,2,3))
sc.makeRDD(List(1,2,3))
- 从文件创建(按行拆分)
val rdd=sc.textFile("/home/word.txt")
*查看rdd:rdd.collect
转化算子
map:接受函数作为参数,应用于rdd每个元素,返回每个元素的值
val rdd2=rdd1.map(x=>x+1)
val rdd2=rdd1.map(_+1)
filter:对rdd每个元素进行过滤
val rdd2=rdd1.filter(>3)
flatMap:同map,返回的元素可变
val rdd2=rdd1.flatMap(_.split(" "))
reduceByKey:元组形式RDD,把相同的key通过传入的函数进行合并成一个值
val rdd2=rdd1.reduceByKey((x,y)=>x+y)
groupByKey:元组形式RDD,把相同的key通过传入的函数进行合并成一起
val rdd2=rdd1.groupByKey()
union:合并两个RDD
val rdd3=rdd1.union(rdd2)
sortBy:按照某个规则排序,第一个参数是按某个属性,第二个参数是升降序
val rdd2=rdd1.sortBy(x=>x._2,false) //降序
sortByKey:元组形式RDD按照key排序,默认升序
val rdd2 = rdd1.sortByKey(False)
join:元组形式RDD按照key连接,左外连接leftOuterJoin()左边rdd必定存在,连接的数据为(key, (v, Some(w))),未连接的数据为(key, (v, None)),右外连接同,全外连接fullOuterJoin()rdd1和rdd2记录全部存在,全部为Some类型
val rdd3 = rdd1.join(rdd2) //rdd1和rdd2顺序改变有区别
intersection:交集
val rdd3 = rdd1.intersection(rdd2)
distinct:去重
val rdd2 = rdd1.distinct
cogroup:元组形式RDD,根据key进行并集,(key,(iterable1,iterable2))
val rdd3 = rdd1.cogroup(rdd2)
*
所有转化算子并非立即运算,直到遇到行动算子才会执行
行动算子
reduce:通过传入的函数对rdd聚合
rdd1.reduce(_+_) //使用例子
count:统计rdd元素量
countByKey:元组形式RDD,统计相同key的数量,返回map
collect:返回元素
first:返回第一个元素
take:返回前n个元素数组
foreach:给每个元素执行传入的函数
RDD持久化
cache或persist
检查点
sc.setCheckpointDir("...")
rdd.checkpoint()
*
检查点之前也建议先持久化
import项
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
val conf = new SparkConf()
val sc = new SparkContext(conf)
Spark结构化数据(DataFrame)
SparkSession:SparkContext的封装,允许用户调用DataFrame和Dataset
//创建sparksession
val spark = SparkSession.builder().appName("...").master("...").getOrCreate()
DataFrame是元素类型为row的Dataset
*查看dataframe数据:d1.show(n)
Spark SQL 内部数据
RDD转DataFrame
- 元组法
val rdd2: RDD[(String,Int)] = rdd1.map(line => {
val arr = line.split(",")
(arr(0), arr(1).toInt)
})
import spark.implicits._
val df = rdd.toDF("name","age")
- 样例法
val rdd2: RDD[User] = rdd1.map(line => {
val arr = line.split(",")
User(arr(0), arr(1).toInt)
})
import spark.implicits._
val df = rdd.toDF()
//位于伴生对象外建立样例
case class User(name: String, age: Int)
- 函数法
val rdd2: RDD[Row] = rdd1.map(line => {
val arr = line.split(",")
Row(arr(0), arr(1).toInt)
})
val schema = StructType{
List(
StructField("name", DataTypes.StringType),
StructField("age", DataTypes.IntegerType)
)
}
val df = spark.createDataFrame(rdd2,schema)
Dataset转DataFrame(同RDD)
val d1 = spark.read.textFile("...") //首先读取Dataset
val d2 = d1.map(line=>{
val fields = line.split(",")
val row1 = fields(0).toInt
val row2 = fields(1)
....
Person(row1,row2,...)
})
case class Person(row1:Int, row2:String, ... )
import spark.implicits._
val pdf = d2.toDF()
通过执行SQL语句生成DataFrame
pdf.createTempView("v_person") //临时视图
val res = spark.sql("select * from v_person") //使用sql语句
Spark SQL 外部文件
加载外部文件(通用)
val df = spark.read.load("...")
//保存
df.write.save("...")
读取parquet文件
val DF = spark.read.parquet("...")
//schema合并操作(如需要)
val mergedDF = spark.read.option("mergeSchema","true").parquet("...")
读取json
//json内容:{"name":"zhangsan","age":32}
// {"name":"lisi","age":20}
// ......
val DF = spark.read.json("...")
写入Hive表
//开启hive
val spark = SparkSession.builder()
.appName("Spark Hive Demo")
.enableHiveSupport()
.getOrCreate()
//使用sparksql创建hive表
spark.sql("CREATE TABLE IF NOT EXISTS students (name STRING, age INT)"+"ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'")
//使用sparksql导入数据入hive表
spark.sql("LOAD DATA LOCAL INPATH '...'"+"INTO TABLE students")
//将DataFrame转hive表
val DF = spark.table("students")
DF.write.mode(SaveMode.Overwrite).saveAsTable("...")
加载JDBC(mysql)
val DF = spark.read.format("jdbc")
.option("url","jdbc:mysql://.....")
.option("driver","com.mysql.jdbc.Driver")
.option("dbtable","select *from student")
.option("user","root")
.option("password","1234")
.load()
Spark SQL 函数
(只列举一些常用函数)
lower, select, where, filter, count, countDistinct, distinct, avg, max, min
groupBy:按类别分组,返回一个组关联dataset,通常可以和count或聚合函数一起使用,返回dataframe
agg:聚合函数,参数是新列生成方式
withColumn:添加列
自定义函数
val func = (:)=>{}
spark.udf.register("function_name",func)
开窗函数row_number()
row_number() over (partition by column_name order by column_name desc) new_column_name
SQL 相关(补)
-
COALESCE(expression1,expression2,…)
返回参数中第一个不是空值的expression -
TRIM(string)
删除字符串头尾空格
import 项
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.functions.{...,udf}
val spark = SparkSession.builder().appName("...").master("...").getOrCreate()
import spark.implicits._ //数据转DataFrame格式需要
val df = spark.sql(...) //从hive表中直接导入DataFrame
Kafka
基本概念
数据单元:消息
独立的服务器节点:Broker
消息的类别:主题,通常分成多个分区,消息均匀分配(类似队列),允许消息超出一台服务器
生产者:前端产生的页面、服务器日志
消费者:hadoop集群、实时监控程序、数仓
zookeeper集群:管理协调broker
*
kafka的broker是生产者和消费者的中间件,生产者push,消费者pull(需要偏移值offset),消息通常保留新信息,当某个broker宕机时,其他broker会接替,生产者和消费者重新连接新broker
副本
领导者副本:只有一个,生产者和消费者都向领导者发请求
跟随者副本:复制领导者副本,保持一致(向领导者pull)
领导者崩溃,跟随者接替
领导者副本维护同步副本列表:ISR(在zookeeper中),如果跟随者没有跟上,会被移出ISR
消息写入时需要ISR所有副本同步完毕,才算写完,消费者才能读取数据
对于生产者来说,可以通过调节acks参数,如为1时领导者写入成功,生产者就认为写入成功
消费者组
同一消费组内不允许多个消费者消费同一分区,不同消费者组可以同时消费同一分区
在组内为队列模式,组间是广播模式
数据存储
每个分区一个文件夹,每个分区多个segment(包含多个消息,kafka数据存储最小单位)
segment分为索引文件和数据文件,索引文件指向数据文件消息的物理偏移地址(实际取内容用)
segment文件名字由20位数字组成,每个分区第一个文件为0,下一个文件为上一个文件最后一个消息的offset(定位消息用)
Spark Streaming
基本概念
接收实时输入数据流,以时间片为单位拆分成批数据(多个RDD,DStream),交给spark处理生成批结果(RDD序列)
输入DStream:输入数据流,会与一个Receiver对象关联,一个receiver占一个cpu内核
Executor进程:执行任务,所分配的cpu内核数必须大于receive
代码一般流程
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
//1. 创建StreamingContext
val conf = new SparkConf().setMaster("local[2]")
.setAppName("...")
val ssc = new StreamingContext(conf, Seconds(1)) //批处理间隔1秒
//2. 创建DStream
val lines = ssc.socketTextStream("localhost", 9999) //lines每条记录都是一行文本
//3. 算子操作(同RDD)
val words = lines.flatMap(_.split(" "))
//4. 启动
ssc.start() //开始计算
ssc.awaitTermination()
数据源
- 文件
ssc.fileStream[keyclass, valueclass, formatclass]("...")
ssc.textFileStream("...")
-
socket
同上节 - RDD队列
val rddQueue = new mutable.Queue[RDD[int]]()
rddQueue += ssc.sparkContext.makeRDD(1 to 10)
rddQueue += ssc.sparkContext.makeRDD(20 to 30)
val inputDStream = ssc.queueStream(rddQueue)
-
kafka等高级数据源
在maven引入spark streaming依赖库、kafka第三方依赖库
import org.apache.spark.streaming.kafka._
val kafkaStream = KafkaUtils.createStream(streamingContext, [ZK quorum], [consumer group id], [per-topic number of Kafka partitions to consume])
操作
-
无状态操作
只计算当前时间批次:map, flatMap, filter, union, reduce, countByValue, join, reduceByKey, cogroup等 -
状态操作
当前时间批次和历史时间批次累加计算:updateStateByKey -
窗口操作
在滑动窗口内进行操作:window(length, interval) 取滑动窗口所覆盖的DStream
countByWindow(length, interval) 计算窗口内元素数量
reduceByWindow(func, length, interval) -
输出操作
将DStream输出到外部
print(), saveAsTextFiles, foreachRDD(func)
持久化和检查点
-
持久化
同RDD -
检查点:
1)元数据检查点:定义流计算的信息,包括配置信息、DStream操作、未完成批次
2)数据检查点:使用updateStateByKey等状态转换函数,必须提供检查点,定期将RDD存入可靠系统;driver从故障中恢复,也必须提供检查点
*
检查点默认时间间隔是批处理时间间隔倍数(5-10倍),至少10s
dstream.checkpoint(interval)
ssc.checkpoint("...") //创建检查点
//从故障中恢复时,重新创建StreamContext
def func():StreamingContext={
......
ssc.checkpoint("...")
ssc
}
val context = StreamingContext.getOrCreate("...",func())
linux指令
文件属性
d:目录
-:文件
l:链接文件
rwx:可读可写可执行
第一组rwx:属主权限,文件所有者
第二组rwx:属组权限,文件所有者同组用户
第三组rwx:其他用户权限
例:drwxr-xr–
文件管理
ls:列出文件 -a全部包括隐藏文件,-d全部目录,-l详细属性
cd:切换目录 /根目录,./当前目录,…/相对路径,…上一个目录,~家目录
pwd:当前路径 [-P]确实路径
mkdir:创建目录 -p递归创建,-m配置权限(711:rwx–x–x)
rmdir:删除空目录 -p递归删除
cp:复制文件 -i询问覆盖,-p同时复制属性,-d复制连结,-r递归复制,-a同-pdr
rm:删除文件(谨慎) -i询问删除,-r递归删除,-f强制删除
mv:移动或更名文件 -i询问移动,-u更新,-f强制移动直接覆盖
man:help
ln:硬链接 -s软链接
cat:显示内容 -b显示行号不包括空行,-n显示行号包括空行
nl:显示内容与行号
more:翻页显示 space翻一页,enter滚动一行,/查找,q退出,b往回翻
rz:放入新文件
sz:提取文件
scp:与服务器互传文件(可用rz和sz)
*hadoop fs:hadoop文件管理命令
shell脚本相关
基本命令
vim filename:进入vim一般模式
一般中i:输入模式
esc:返回一般模式
一般中冒号:底线模式
底线中w:保存
底线中q:退出
编写内容
#!/bin/bash或#!/bin/sh开头
-
test命令
用途:检查语句成立,通常可以与if语句一起使用
数值比较:等于-eq,不等于-ne,大于-gt,小于-lt
字符串比较:等于=,不等于!=,长度为零-z,长度不为零-n
文件检查:存在-e,存在且内容不为空-s,存在且为目录-d
echo命令:输出字符串
read:输入 - 条件语句
if condition
then
command
else
command
fi
#elseif语句相同写法
如果else中没有command就不写else
- 循环语句
#for循环
for ... in ... ... ...
do
command
done
#while循环
while condition
do
command
done
- case语句
case ... in ... ... ...
...)
command
...
;;
...)
command
...
;;
esac
- 函数
func(){
command
return ...
}
Git指令
-
本地指令(工作区到本地仓库)
git init:初始化仓库
git clone:拷贝仓库
git add:添加文件至暂存区
git status:查看仓库状态
git commit:提交
git reset:回退
git rm:删除暂存区和工作区中的文件
git mv:移动工作区的文件
git log:查看历史提交 -
远程操作(远程仓库)
git remote:操作
git fetch:获取代码库
git pull:下载远程代码
git push:上传代码
常用git流程:
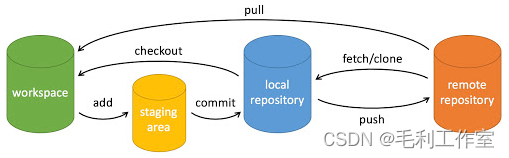
(转自菜鸟教程)
*
一般提交流程:git add …—> git commit -m “…”—> git push
一般下载流程:git fetch
-
分支
git branch:列出分支 -a列出本地和远程分支
git merge:合并分支