↑↑↑关注后”星标”Datawhale
每日干货 & 每月组队学习,不错过
Datawhale干货
作者:知乎King James,伦敦国王大学
知乎 | https://www.zhihu.com/people/xu-xiu-jian-33
前言:本篇文章主要面向产品、业务、运营人员等任何非技术人员通俗易懂地讲解什么是深度学习和神经网络,二者的联系和区别是什么。无需技术背景也可以有一个比较全面清晰的认识。同时也为为大家讲解TensorFlow、Caffe、Pytorch等深度学习框架和目前工业界深度学习应用比较广的领域。
01 人工智能、机器学习、深度学习
1.1 人工智能是什么
在介绍深度学习之前,先和大家介绍一下AI和Machine Learning,才能理清AI、Machine Learning、Deep Learning三者之间的关系。
1956年8月,在美国汉诺斯小镇的达特茅斯学院中,几位科学家在会议上正式提出“人工智能”这一概念,这一年也被称为人工智能元年。在此之前,人类已经制造出各类各样的机器如汽车、飞机等,但这些机器都需要经过人来操作使用,无法自己具备操作的能力。科学家探讨能不能制造出一个可以像人类大脑的一样思考的机器,拥有人类的智慧,这就是人工智能。
同时科学家们也对AI未来的发展畅想了三个阶段:
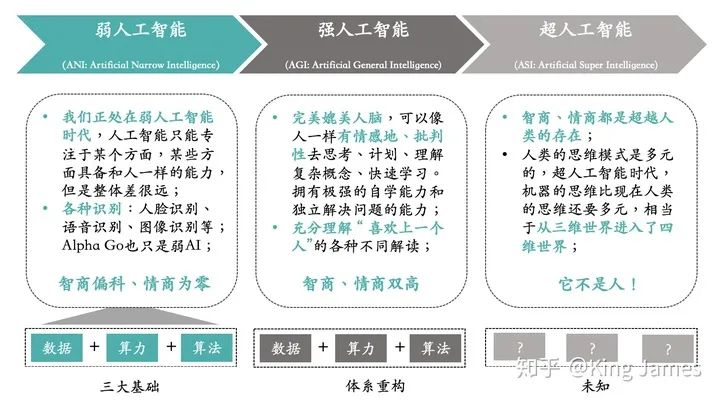
大家在电影上看到的各种AI都是强人工智能,但目前我们仍处在弱人工智能阶段,什么时候进入强人工智能阶段未知。强人工智能阶段,机器可以完美媲美人脑,像人类一样有情感地、批判性地去思考。同时可以快速学习,拥有极强的自学能力。
那么如何实现人工智能,实现人工智能的方法是什么?
1.2 机器学习是什么
实现人工智能的方法我们统称为“机器学习”。同样是1956年的美国达特茅斯会议上,IBM的工程师Arthur Samuel正式提出“Machine Learning”这个概念,1956年真的是特殊的一年。
机器学习既是一种实现AI的方法,又是一门研究如何实现AI的学科,你可以理解为和数学、物理一样的学科。机器学习,简单来说就是从历史数据中学习规律,然后将规律应用到未来中。国内大家一致推荐的,南京大学周志华教授的机器学习教材西瓜书里面如此介绍机器学习。
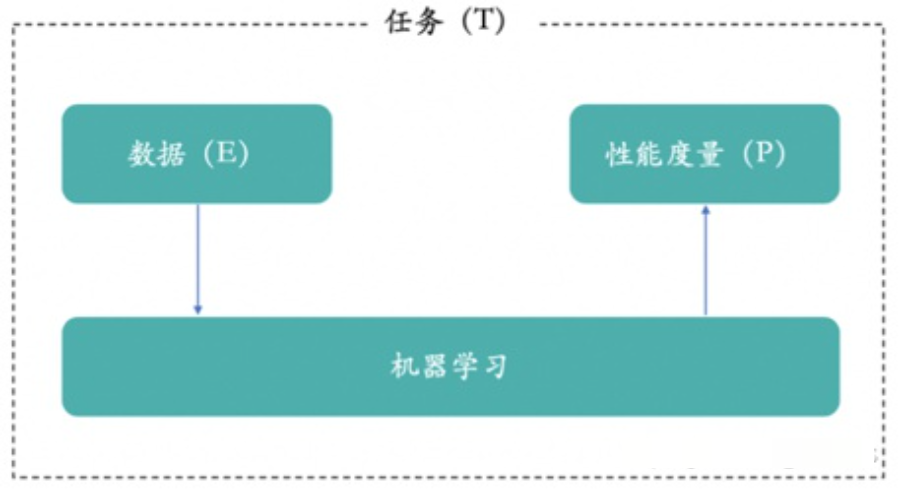
机器学习是机器从历史数据中学习规律,来提升系统的某个性能度量。其实人类的行为也是通过学习和模仿得来的,所以我们就希望计算机和人类的学习行为一样,从历史数据和行为中学习和模仿,从而实现AI。
简单点讲,大家从小到大都学习过数学,刷过大量的题库。老师和我们强调什么?要学会去总结,从之前做过的题目中,总结经验和方法。总结的经验和方法,可以理解为就是机器学习产出的模型,然后我们再做数学题利用之前总结的经验和方法就可以考更高的分。有些人总结完可以考很高的分,说明他总结的经验和方法是对的,他产出的的模型是一个好模型。
既然有了机器学习这一方法论,科学家们基于这一方法论,慢慢开始提出各类各样的算法和去解决各种“智能”问题。就像在物理学领域,物理学家们提出各种各样的定理和公式,不断地推动着物理学的进步。牛顿的三大定律奠定了经典力学的基础。而传统机器学习的决策树、贝叶斯、聚类算法等奠定了传统机器学习的基础。
1.3 深度学习是什么
但是随着研究的不断深入,传统机器学习算法在很多“智能”问题上效果不佳,无法实现真正的“智能”。就像牛顿三大定律,无法解释一些天文现象。在1905年,爱因斯坦提出“相对论”,解释了之前牛顿三大定律无法解释的天文现象。同样2006年,加拿大多伦多大学教授Geoffrey Hinton对传统的神经网络算法进行优化,在此基础上提出了Deep Neural Network的概念,他们在《Science》上发表了一篇Paper,引起Deep Learning在学术界研究的热潮。(paper原文:http://www.cs.toronto.edu/~hinton/science.pdf)
2012年Geoffrey Hinton老爷子的课题组,在参加业界知名的ImageNet图像识别大赛中,构建的CNN网络AlexNet一举夺得冠军,且碾压第二名(SVM方法)。也正是因为该比赛,Deep Learning引起了工业界的关注,迅速将Deep Learning引进到工业界的应用上。深度学习技术解决了很多传统机器学习算法效果不佳的“智能”问题,尤其是图片识别、语音识别和语义理解等。某种程度上,深度学习就是机器学习领域的相对论。
将人工智能和机器学习带到一个新高度的技术就是:Deep Learning。深度学习是一种机器学习的技术。
同时大家应该听到过一大堆的“学习”名词:机器学习、深度学习、强化学习等等。在这里面机器学习是“爸爸”,是父节点;其他都是它“儿子”,是子节点。AI、Machine Learning和Deep Learning的关系可以通过下图进行描述。
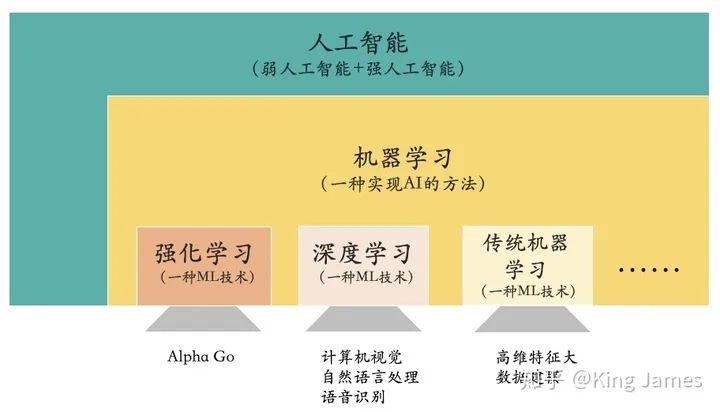
让机器实现人工智能是人类的一个美好愿景,而机器学习是实现AI的一种方法论,深度学习是该方法论下一种新的技术,在图像识别、语义理解和语音识别等领域具有优秀的效果。(对强化学习感兴趣的读者可以参考:https://zhuanlan.zhihu.com/p/150451604)
那么深度学习到底是一门什么技术?“深度”到底代表什么?
02 深度学习与神经网络
2.1 生物神经网络
介绍深度学习就必须要介绍神经网络,因为深度学习是基于神经网络算法的,其实最开始只有神经网络算法,上文也提到2006年Geoffrey Hinton老爷子提出Deep Learning,核心还是人工神经网络算法,换了一个新的叫法,最基本的算法没有变。学过生物的都知道神经网络是什么?下图是生物神经网络及神经元的基本组成部分。
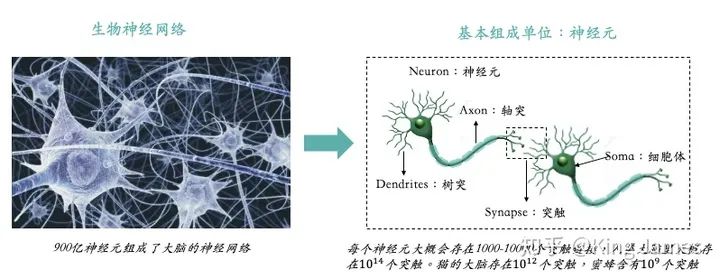
人类的大脑可以实现如此复杂的计算和记忆,就完全靠900亿神经元组成的神经网络。那么生物神经网络是如何运作的?可以参照下图:
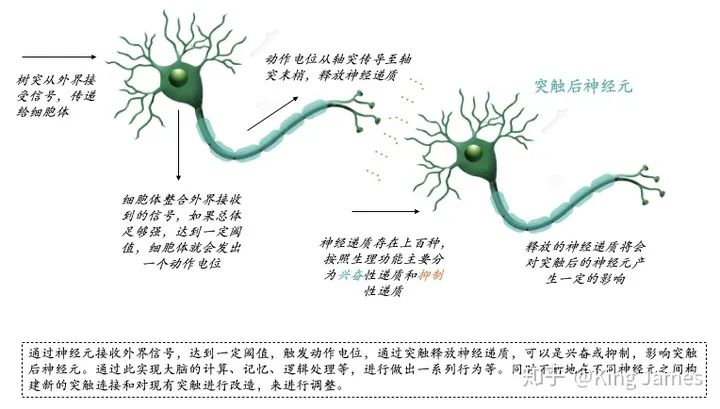
通过神经元接收外界信号,达到一定阈值,触发动作电位,通过突触释放神经递质,可以是兴奋或抑制,影响突触后神经元。通过此实现大脑的计算、记忆、逻辑处理等,进行做出一系列行为等。同时不断地在不同神经元之间构建新的突触连接和对现有突触进行改造,来进行调整。有时候不得不感叹大自然的鬼斧神工,900亿神经元组成的神经网络可以让大脑实现如此复杂的计算和逻辑处理。
2.2 人工神经网络
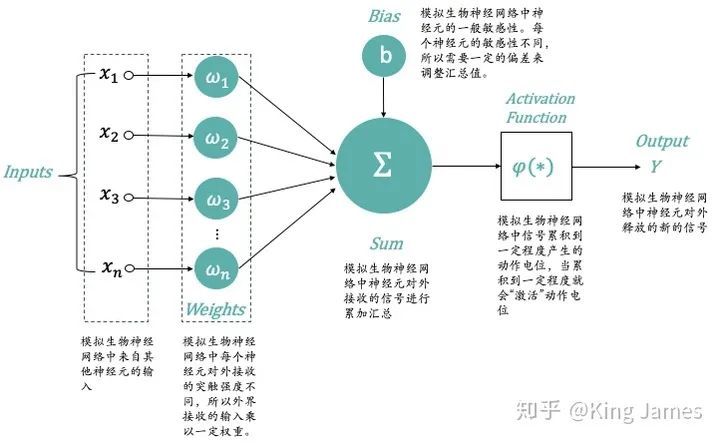
科学家们从生物神经网络的运作机制得到启发,构建了人工神经网络。其实人类很多的发明都是从自然界模仿得来的,比如飞机和潜艇等。下图是最经典的MP神经元模型,是1943年由科学家McCulloch和Pitts提出的,他们将神经元的整个工作过程抽象为下述的模型。
-
x_1,x_2,x_3,x_n:模拟生物神经网络中来自其他神经元的输入;
-
ω_1,ω_2,ω_3,ω_n:模拟生物神经网络中每个神经元对外接收的突触强度不同,所以外界接收的输入乘以一定权重;
-
Σ-Sum:模拟生物神经网络中神经元对外接收的信号进行累加汇总;
-
Bias:模拟生物神经网络中神经元的一般敏感性。每个神经元的敏感性不同,所以需要一定的偏差来调整汇总值;
-
Activation Function:模拟生物神经网络中信号累积到一定程度产生的动作电位,当累积到一定程度就会“激活”动作电位。实际使用时我们一般使用Sigmoid函数;
-
Output:模拟生物神经网络中神经元对外释放的新的信号;
现在我们知道了最简单的神经元模型,我们该如何使用该模型从历史数据中进行学习,推导出相关模型?我们使用上述MP模型学习一个最简单的二分类模型。
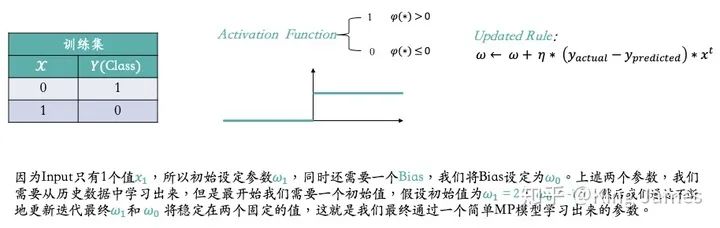
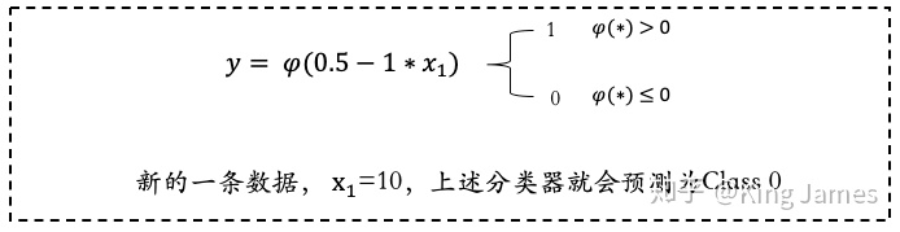
如上图,为了训练简单,我们训练集里面只有两条数据。同时激活函数,我们也是最简单的激活函数,当φ(∗) > 0时输出为1,当φ(∗) ≤ 0时输出为0。然后对于参数的更新规则Updated Rule,我们使用的Sequential Delta learning rule和Back Propagation算法,该规则和算法不详细介绍了,可以理解为就像物理、数学领域一些科学家发现的普适性定理和公式,已经得到证明,用就完事了。因为Input只有1个值x_1,所以初始设定参数ω_1,同时还需要一个Bias,我们将Bias设定为ω_0。上述两个参数,我们需要从历史数据中学习出来,但是最开始我们需要一个初始值,假设初始值为ω_1 = 2, ω_0 = 1.5 ;然后我们通过不断地更新迭代最终ω_1和 ω_0 将稳定在两个固定的值,这就是我们最终通过一个简单MP模型学习出来的参数。下图是整个更新迭代学习的过程:
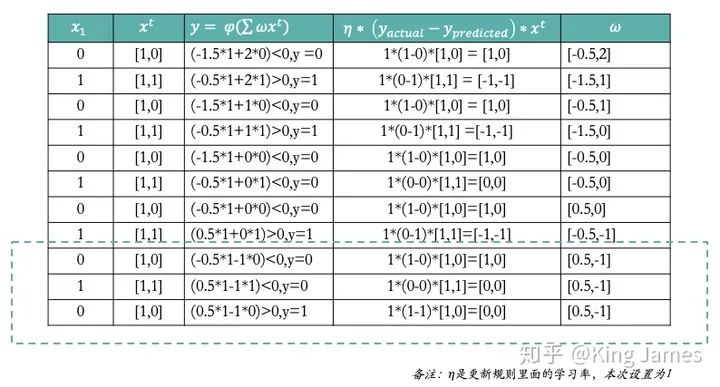
大家可以看到上图最后一次循环ω已经不再发生变化,说明[0.5,-1]就是最终我们学习出来的固定参数。那么上述整个过程就是一个通过神经网络MP模型学习的全过程。下图是最终学习出来的Classifier分类器,我们带入一个新的数据,就可以进行Class预测了。
2.3 何为”深度“
上文我们已经介绍了人工神经网络经典的MP模型,那么在深度学习里面我们使用的是什么样的神经网络,这个”深度“到底指的是什么?其实就是如下图所示的,输入层和输出层之间加更多的”Hidden Layer“隐藏层,加的越多越”深“。
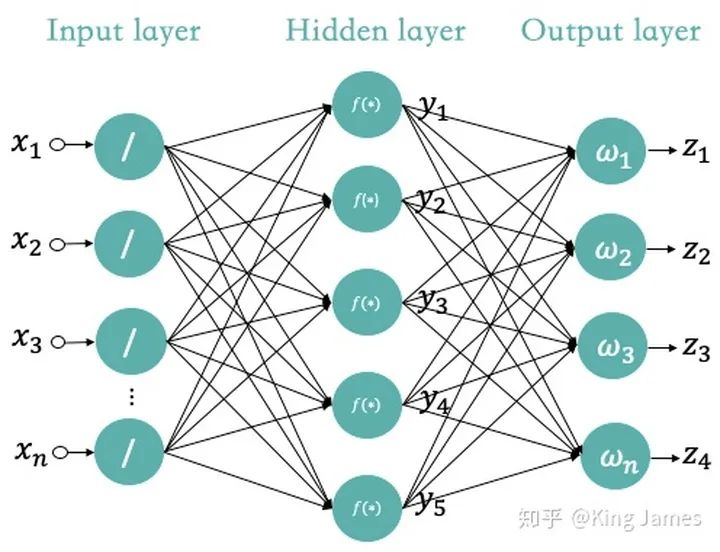
最早的MP神经网络实际应用的时候因为训练速度慢、容易过拟合、经常出现梯度消失以及在网络层次比较少的情况下效果并不比其他算法更优等原因,实际应用的很少。中间很长一段时间神经网络算法的研究一直处于停滞状态。人们也尝试模拟人脑结构,中间加入更多的层”Hidden Layer“隐藏层,和人脑一样,输入到输出中间要经历很多层的突触才会产生最终的Output。加入更多层的网络可以实现更加复杂的运算和逻辑处理,效果也会更好。
但是传统的训练方式也就是我Part 2.2里面介绍的:随机设定参数的初始值,计算当前网络的输出,再根据当前输出和实际Label的差异去更新之前设定的参数,直到收敛。这种训练方式也叫做Back Propagation方式。Back Propagation方式在层数较多的神经网络训练上不适用,经常会收敛到局部最优上,而不是整体最优。同时Back Propagation对训练数据必须要有Label,但实际应用时很多数据都是不存在标签的,比如人脸。
当人们加入更多的”Hidden Layer“时,如果对所有层同时训练,计算量太大,根本无法训练;如果每次训练一层,偏差就会逐层传递,最终训练出来的结果会严重欠拟合(因为深度网络的神经元和参数太多了)。
所以一直到2006年,Geoffrey Hinton老爷子提出了一种新的解决方案:无监督预训练对权值进行初始化+有监督训练微调。
归纳一下Deep Learning与传统的神经网络算法最大的三点不同就是:
-
训练数据:传统的神经网络算法必须使用有Label的数据,但是Deep Learning下不需要;
-
训练方式不同:传统使用的是Back Propagation算法,但是Deep Learning使用自下上升非监督学习,再结合自顶向下的监督学习的方式。对于监督学习和非监督学习概念不清楚的读者可以阅读我上文引用的强化学习文章,里面有详细介绍。
-
层数不同:传统的神经网络算法只有2-3层,再多层训练效果可能就不会再有比较大的提升,甚至会衰减。同时训练时间更长,甚至无法完成训练。但是Deep Learning可以有非常多层的“Hidden Layer”,并且效果很好。
(想了解更多细节的可以阅读:https://blog.csdn.net/zouxy09/article/details/8775518)
不管怎么样Deep Learning也还是在传统神经网络算法基础上演变而来的,它还是一种基于神经网络的算法。今天已经是2021年了,深度学习在很多领域得到了广泛的应用,而且和很多其他学习也结合起来一起使用,比如深度强化学习,有种物理化学专业的赶脚。
MIT讲解了Deep Learning最新的一些研究和应用,详情可以关注这个B站视频:https://www.bilibili.com/video/BV1vg4y1B7Nz?from=search&seid=6689440565680809808。知乎上也有作者解读过这个视频@套牌神仙。
3. 深度学习框架
大家了解深度学习和神经网络以后,相信大家也经常听到如下的英文单词:Tensorflow、Caffe、Pytorch等,这些都是做什么的了。Tensorflow是Google旗下的开源软件库,里面含有深度学习的各类标准算法API和数据集等,Pytorch是Facebook旗下的开源机器学习库,也包含了大量的深度学习标准算法API和数据集等。Caffe是贾扬清大神在UC Berkeley读博士时开发的深度学习框架,2018年时并入到了Pytorch中。
因为深度学习发展至今,很多算法都已经是通用的,而且得到过验证的。那么有些公司就希望将一些标准算法一次性开发好,封装起来,后面再使用时直接调用引入即可,不需要再写一遍。就像大家小时候学习英文一样,英文字典有牛津版本的,也有朗文版本的。对于收录的英文单词,英文单词如何使用,如何造句等,已经有了标准的用法。我们只需要查阅这些字典即可,而Tensorflow、Caffe、Pytorch做的其实也就是计算机届的牛津、朗文英文大词典。国内百度目前也有自己的深度学习框架Paddle-Paddle。
目前一般是学术界用Pytorch较多,Pytorch更适合新手入门,上手快。工业界用Tensorflow较多,更适合工业界的落地和部署等。
4. 深度学习在工业界主要应用领域
目前深度学习应用最广泛的就是传统机器学习算法解决不了的领域或者是效果不佳的领域:视觉、自然语言和语音识别领域。当样本数量少的时候,传统机器学习算法还可以通过一些结构化特征组合在一起然后区分出来。比如区分汽车和摩托车,可以通过轮子数量。但对于人脸,千万张人脸相似的太多,已经完全无法通过鼻子、头发、眼睛这些简单的特征组合进行区分。需要探索更多更复杂的特征,组合在一起才能将千万张人脸区分开来。

所以这时候就需要Deep Learning构建多层神经网络,探索组合更多的特征,才能识别区分千万级别甚至亿万级别的人脸。这在传统神经网络算法和机器学习算法是完全实现不了的。当然实现上述功能,也是因为现阶段有了更多的数据可以进行训练,同时有了更好的算力可以快速完成训练。传统的CPU进行训练,可能训练几个月都训练不出来结果。GPU的出现和改进加速了上述训练过程。
目前应用最广的一些领域:
-
CV:计算机视觉领域。随处可见的人脸识别、物体识别和文字识别OCR。广泛应用于安防领域,同时零售行业也在通过CV技术实现线下门店的数字化。目前国内头部公司就是CV四小龙:商汤、旷视、云从、依图;
-
NLP:自然语言处理领域。目前整体的NLP技术还是不够成熟,无法实现人们设想的机器人可以完全智能对话,机器人目前只能做一些简单的信息提取和检索整合的事情。NLP目前也是最难做的,同样一句话可能会有不同种意思。人有时都很难理解,更何况机器。目前国内头部公司主要是百度和达观;
-
ASR:语音识别领域。目前国内独一档就是科大讯飞,尤其是能够做到很多地方方言的精准识别。语音识别目前主要主要用在语音客服上,有时候大家接到的推销电话其实背后都是电话机器人打的。电话机器人能够完全和用户进行对话,一定程度上也需要NLP的技术,因为它需要理解用户的意思。
-
Autopilot:自动驾驶其实也是CV的衍生领域,目前世界上做自动驾驶最好的其实还是汽车公司比如特斯拉。因为没有车,自动驾驶想获得训练数据都很困难。没有车,自动驾驶技术想实验都跑不通。目前国内百度差不多算第一档。
-
推荐:传统的推荐都是用GBDT+LR模型来做的,目前深度学习在推荐领域也得到了广泛的应用,下面是深度学习在美团点评里搜索推荐的应用可以阅读一下。
以上就是站在一个PM角度来和大家通俗易懂的介绍深度学习和神经网络,欢迎大家沟通交流指正。

整理不易,点赞三连↓