一. Operator state 使用建议
慎重使用长 list
下图展示的是当前版本中 task 端 operator state 在执行完 checkpoint 返回给 job master 端的 StateMetaInfo 的代码片段。
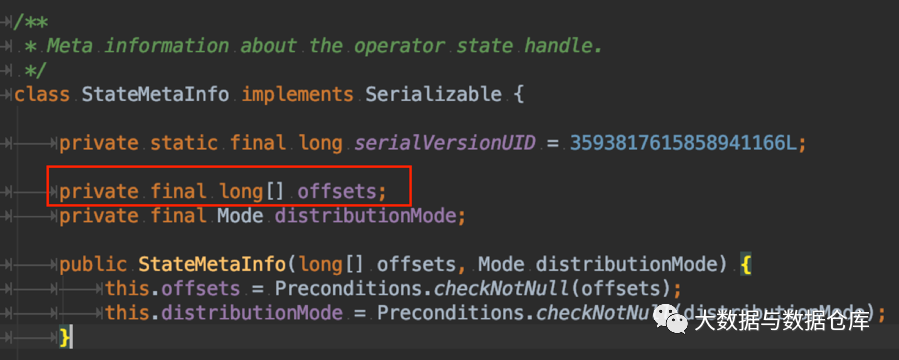
由于 operator state 没有 key group 的概念,所以在修改任务并发度进行恢复时,需要将operator state中的每一个序列后的元素存储一个位置偏移量(offset),如上图红框中的offsets数组所示。
另外如果你定义的operator state很大时,上面所说的offset数组的规则就可能达到数十MB,重要的是这个状态数组是会上报给job manager的,如果算子(operator)的并发数目很大,那么意味着该算子的多个并发任务都将上报数十MB的状态,这很容易导致job manager 发生OOM。
我们之前有同事用operator state存储某个业务的id-mapping数据,结果这个id-mapping数据的规模越来越大,后面导致一开始执行checkpoint, job manager就会因为收到task返回的超大的offset数组导致占用内存量越来越大,无法正常相应甚至OOM。
正确使用 UnionListState
union list state 目前被广泛使用在 kafka connector 中,不过可能用户日常开发中较少遇到,他的语义是从检查点恢复之后每个并发 task 内拿到的是原先所有operator 上的 state,如下图所示:
kafka connector 使用了上述功能,主要目的的是当checkpoint恢复时,可以获取到之前的全局信息,如果用户需要使用该类型状态,需要切记恢复的 task 只取其中的一部分进行处理和用于下一次 snapshot,否则有可能随着作业不断的重启而导致 state 规模不断增长。
![]()
二. Keyed state 的使用
如何正确清空当前的 state
state.clear() 实际上只能清理当前 key 对应的 value 值,如果想要清空整个 state,需要使用 applyToAllKeys 方法,具体代码片段如下:

如果你的需求中只是对 state 有过期需求,借助于 state TTL 功能来清理性能会更好,如下所示:
// 定义State (一个去重场景)
new ValueStateDescriptor<>("KeyedStateDeduplication",
TypeInformation.of(new TypeHint<Boolean>() {}));
// 状态 TTL 相关配置,过期时间设定为 36 小时
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.hours(36))
.setUpdateType(
StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(
StateTtlConfig.StateVisibility.NeverReturnExpired)
.cleanupInRocksdbCompactFilter(50000000L)
.build();
// 开启 TTL
keyedStateDuplicated.enableTimeToLive(ttlConfig); RocksDB中考虑value值非常大的场景
受限于 JNI bridge API 的限制,单个 value 只支持 2^31 bytes 大小,如果存在很极限的情况,可以考虑使用 MapState 来替代 ListState 或者 ValueState,因为RocksDB 的 map state 并不是将整个 map 作为 value 进行存储,而是将 map 中的一个条目作为键值对进行存储。
猜您喜欢
往期精选▼
Flink中Checkpoint和Savepoint 的 3 个不同点
3种Flink State Backend | 你该用哪个?
