我们使用过ArrayList类的add方法,其add方法是可以任意添加元素的,而HashSet的add方法则会限制添加重复元素,那么它是如何做到的呢?这需要我们通过查看底层代码来研究。
import java.util.HashSet;
public class HashSetLearn {
public static void main(String[] args) {
HashSet<String> set = new HashSet<>();
set.add("Tom");
}
}
先写一段简单的代码,接着我们按住ctrl点击add就能查看add方法的底层代码。

可以看到add(E e)方法本身调用了map.put()方法,而我们再查看map可以发现map其实是一个全局变量

而这个全局变量指向的是HashSet里的HashMap对象,那么接下来我们来看看put方法的源代码

如同之前博客提到的,put方法传入的参数为key—K和value—-V,返回的又是一个新方法相关的值—–putVal
在putVal方法中,有一个返回值为hash(key),经过查看

我们发现hash方法中有一个hashCode方法,返回一个hashcode值,那么hashcode值是什么呢?首先我们判断对象一般根据地址是否相同,这个地址指的是其在内存中的位置,不同对象地址是肯定不同的,而hashcode值就是对象在hash表中的位置,通过hashCode方法给每一个存入其中的对象hashcode值,所以
相同的对象hashcode值肯定是相同的
,可是不同对象的hashcode值一定不相同吗?我们来看一段代码
import java.util.HashSet;
public class HashSetLearn {
public static void main(String[] args) {
String name1="Tom"; //创建对象name1赋值"Tom"
System.out.println(name1.hashCode()); //输出name1的hashcode
String name2=new String("Tom"); //创建对象name2赋值"Tom"
System.out.println(name2.hashCode()); //输出name2的hashcode
System.out.println(name1==name2); //判断name1和name2是否为同一对象
}
}
其结果为
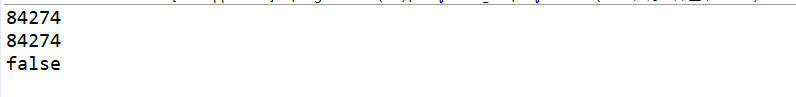
我们看到,明明两个不同的对象,其hashcode值却相同,这是为什么呢?

我们查看hashCode方法对于String类型数据的源码发现,其实际上是把数据存入数组后再遍历数组,并通过一种自定的算法生成hashcode再返回,而
这种算法就会导致两个值相同的不同对象hashcode值相等,无法被add方法重复添加,
那么就会导致一种情况:比如我们利用HashSet创建学生管理系统,要添加两个名字一样的同学,第二个人无法被添加进去。
因此,虽然hashcode判断两个对象是否相同十分简单快捷,但有其瑕疵,可能误判,所以我们的add方法并不会仅仅是通过简单的hashcode去判断
查看putVal方法的源码,我们发现其中还用了许多其他方法


我们假设有一段代码为set.add(“Tom”),那么这段代码的执行过程为: 调用add方法→调用map.put方法→调用putVal方法→table原来并不存在,被创建后由于是引用类型,初始化为null→符合if条件,执行下面代码→resize方法中创建了newTab,实际上是一个Node对象数组并且让table与其相等→返回newTab数组并且tab与其相等(所以tab和table指向同一个数组) 长度为16→通过hash方法给元素取hash值,再通过tab[i = (n – 1) & hash]确定if语句判断是否为空的位置,这里Tom给出的i,在tab数组中之前并不存在这个位置→tab[i] = newNode(hash, key, value, null)给tab上这个位置赋值,由于tab和table指向同一地址,因此table其实也被改变了→返回null使得put方法也返回null,最终使add方法返回true→元素添加成功。
但如果此时我们再次输入set.add(“Tom”)并且执行,过程就不一样了,在进入到putVal方法后,由于table已经存在,直接到了
if ((p = tab[i = (n – 1) & hash]) == null) tab[i] = newNode(hash, key, value, null)→p其实就是之前执行putVal方法时最后得出的tab[i](Node对象),因为刚刚的元素就是”Tom”,所以p不为null,走else路线→if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))),这里与刚刚的原因是相同的,都是Tom,所以hash相同,且key相等,于是e=p,并且直接到
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
由于e已经有值,老value被e.value替换,并且不为null,所以e.value被新value覆盖→返回被更新的e.value→最终add方法返回false,添加失败。
我们注意到,虽然第二个Tom覆盖了第一次添加的object常量,但实际上Node对象还是原来的,换句话说,虽然我们进行了本来应该导致改变的“覆盖”行为,但最终因为用于覆盖和被覆盖的是同样的对象,最终的结果是覆盖“未成功”(没有实际的变化)。
因此,我们总结的话,add方法的执行是如下原理
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//如果table数组尚未创建,则新建table数组
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
//如果table[i]中没有数据则新建
//tab与table所指向的地址相同,并且table[i]也是有值的,并且与tab[i]相同
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//如果p=table[i]的关键字与给定关键字key相同,则替换旧值
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
//判断p的类型,如果为TreeNode(Node的一个子类),就插入TreeNode节点
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//遍历链表,查找指定的关键字,没找到就创建新节点
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
//创建的新节点如果长度超过了阈值,就进行处理
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
//如果链表中下一个节点是要找的节点并且已经存在,停止循环
p = e;
//将p更新
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
//如果存在这个映射就覆盖原有的
if (!onlyIfAbsent || oldValue == null)
e.value = value;
//判断是否允许覆盖,以及映射是否为空,将新值赋值
afterNodeAccess(e);
return oldValue;
}
}
++modCount; //map结构的修改次数加1
if (++size > threshold)
resize();
afterNodeInsertion(evict);
//超过阙值后进行扩容
return null;
}通过这些操作,就能有效避免add添加重复对象。