spark算子练习
参考文章
https://blog.csdn.net/a1043498776/article/details/77478151
transaction算子
Transformation 变换/转换:这种变换并不触发提交作业,完成作业中间过程处理。Transformation 操作是延迟计算的,也就是说从一个RDD 转换生成另一个 RDD 的转换操作不是马上执行,需要等到有 Action 操作的时候才会真正触发运算。
value型
transform里边的value算子
-
map
通过函数func传递源的每个元素,返回一个新的分布式数据集。

-
filter
返回一个新的数据集,该数据集由选择func返回true的源元素组成。

-
flatMap
类似于map,但是每个输入项可以映射到0个或更多的输出项(因此应该返回一个Seq而不是一个单独的项),类似于先map,然后再flatten。


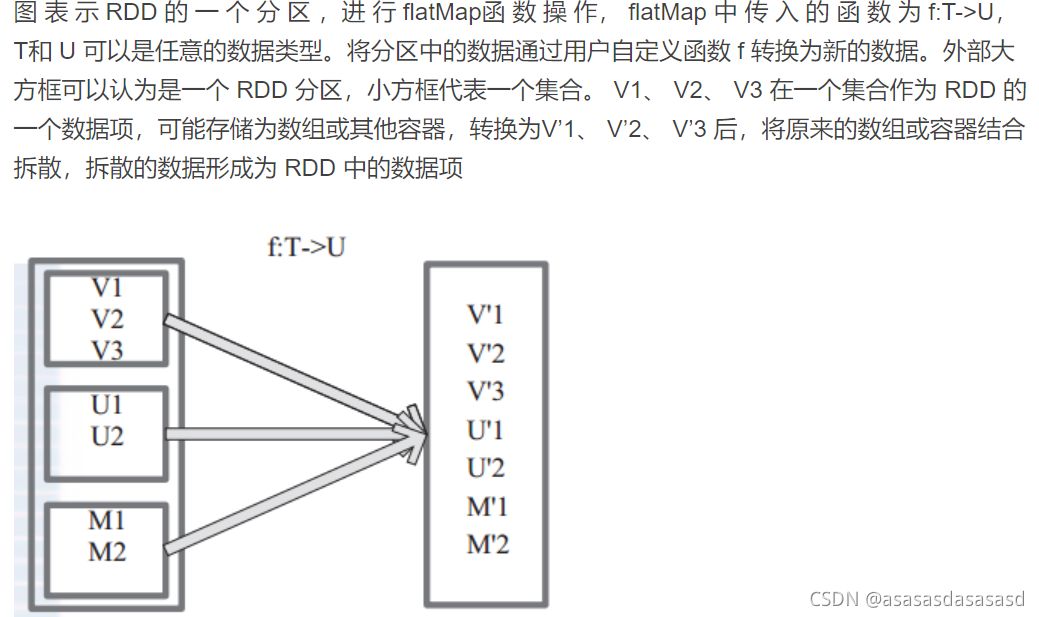
-
mapPartitions
mapPartitions 函 数 获 取 到 每 个 分 区 的 迭 代器,在 函 数 中 通 过 这 个 分 区 整 体 的 迭 代 器 对整 个 分 区 的 元 素 进 行 操 作。返回类型:MapPartitionsRDD
效果和map一样,只是操作的对象是一个迭代器。
map:对分区的每一条数据单独计算,有多少条数据计算多少次
mapPartitions:对整个分区的数据进行计算,一个task仅仅会执行一次function,function一次接收所有的partition数据。只要执行一次就可以了,性能比较高
如果在map过程中需要频繁创建额外的对象(例如将rdd中的数据通过jdbc写入数据库,map需要为每个元素创建一个链接而mapPartition为每个partition创建一个链接),则mapPartitions效率比map高的多。
SparkSql或DataFrame默认会对程序进行mapPartition的优化。
mapPartitions缺点:普通的map操作,一次function的执行就处理一条数据;那么如果内存不够用的情况下,比如处理了1千条数据了,那么这个时候内存不够了,那么就可以将已经处理完的1千条数据从内存里面垃圾回收掉,或者用其他方法,腾出空间,普通的map操作通常不会导致内存的OOM异常;
但是MapPartitions操作,对于大量数据来说,比如甚至一个partition,100万数据,一次传入一个function以后,那么可能一下子内存不够,但是又没有办法去腾出内存空间来,可能就OOM,内存溢出。
——https://blog.csdn.net/wuxintdrh/article/details/80278479

-
mapPartitionsWithIndex
与mapPartitions类似,也为func提供了一个表示分区索引的整数值,在类型为T的RDD上运行时,func格式必须是:

使用这个方法的话,还需要传入一个函数,参数一个int,一个迭代器,然后这个方法会将分区编号传给int,分区中的值传给迭代器,我们对这些数据操作后,同样应该返回一个迭代器。



-
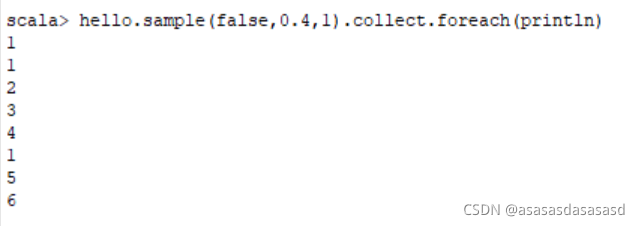
sample(withReplacement, fraction, seed)
使用给定随机数的种子生成器,抽样数据的一小部分,无论是否替换。
– withReplacement:表示抽出样本后是否在放回去,true表示会放回去,这也就意味着抽出的样本可能有重复
– fraction :抽出多少,这是一个double类型的参数,0-1之间,eg:0.3表示抽出30%
– seed:表示一个种子,根据这个seed随机抽取,一般情况下只用前两个参数就可以,那么这个参数是干嘛的呢,这个参数一般用于调试,有时候不知道是程序出问题还是数据出了问题,就可以将这个参数设置为定值

-
union(otherDataset)
返回一个新数据集,其中包含源数据集中的元素和参数的并集,不去重。注意类型要一致

-
intersection(otherDataset)
返回一个新的RDD,其中包含源数据集中元素和参数的交集。

-
distinct
对自身去重

Key-value类型
-
groupByKey
在一个(K,V)的RDD上调用,返回一个(K, Iterator[V])的RDD—-只针对数据是对偶元组的

数据为三个及以上键值对时


groupBy后指定以哪个分组 -
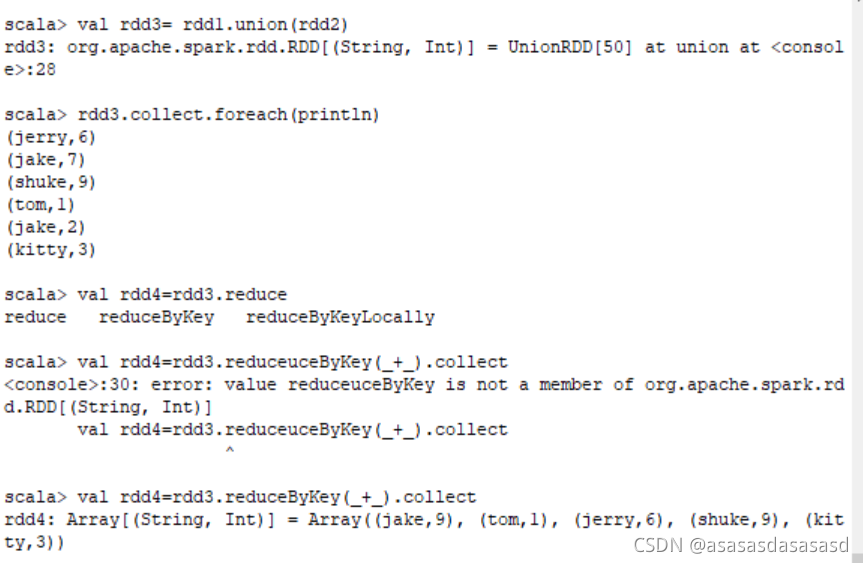
reduceByKey
在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,与groupByKey类似,reduce任务的个数可以通过第二个可选的参数来设置。
-
aggregateByKey
rdd.aggregateByKey(3, seqFunc, combFunc) 其中第一个函数是初始值
3代表每次分完组之后的每个组的初始值。
seqFunc代表combine的聚合逻辑
每一个mapTask的结果的聚合成为combine
combFunc reduce端大聚合的逻辑
ps:aggregateByKey默认分组
https://cloud.tencent.com/developer/article/1337646
https://www.codenong.com/cs105809539/ -
sortByKey
排序


-
join、leftOuterJoin、rightOuterJoin
当调用类型为(K, V)和(K, W)的数据集时,返回一个(K, (V, W))对的数据集



-
cogroup(otherDataset, [numTasks])
在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable,Iterable))类型的RDD

将多个RDD中同一个Key对应的Value组合到一起。
data1中不存在Key为3的元素(自然就不存在Value了),在组合的过程中将data1对应的位置设置为CompactBuffer()了,而不是去掉了。 -
cartesian(otherDataset )笛卡尔积
当调用类型为T和U的数据集时,返回由(T, U)对(所有元素对)组成的数据集。

-
pipe
外部程序调用
https://blog.csdn.net/hohojiang/article/details/74730606
https://blog.csdn.net/qq_29497387/article/details/99634384 -
coalesce
将RDD中的分区数量减少到numPartitions。用于过滤大数据集后更有效地运行操作。 -
repartition
重新分区
通过创建更过或更少的分区将数据随机的打散,让数据在不同分区之间相对均匀。这个操作经常是通过网络进行数打散。
使用repartition可以将数据进行打散,避免倾斜导致的执行耗时不均匀的问题
https://www.jianshu.com/p/391d42665a30 -
repartitionAndSortWithinPartitions
根据给定的分区程序重新划分RDD,并在每个产生的分区中,根据它们的键对记录进行排序。这比在每个分区中调用然后排序更有效,因为它可以将排序推入shuffle机制。
通过给定的分区器,将相同KEY的元素发送到指定分区,并根据KEY 进行排排序。 我们可以按照自定义的排序规则,进行二次排序。
此外,repartitionAndSortWithinPartitions 是一个高效的算子,比先调用 repartition , 再调用 sorting 在分组内排序效率要高,这是由于它的排序是在shuffle过程中进行,一边shuffle,一边排序
https://blog.csdn.net/u010003835/article/details/101000077