文章目录
参考链接:
https://github.com/selfteaching/the-craft-of-selfteaching
布尔运算
乔治·布尔(George Boole)的代数,克劳德·香农(Claude Elwood Shannon)的逻辑电路。
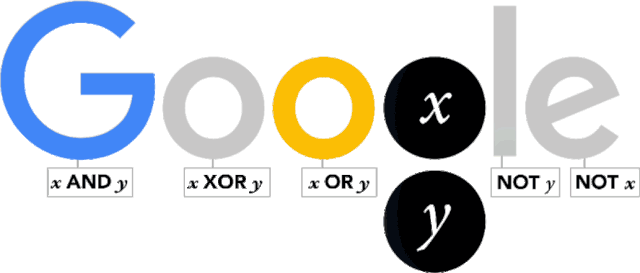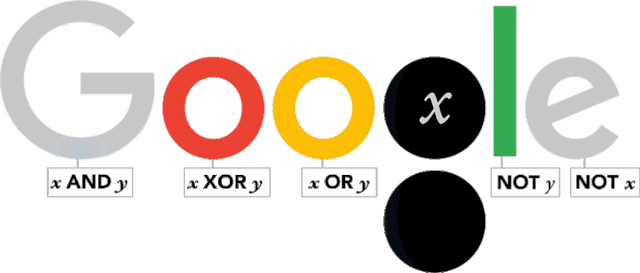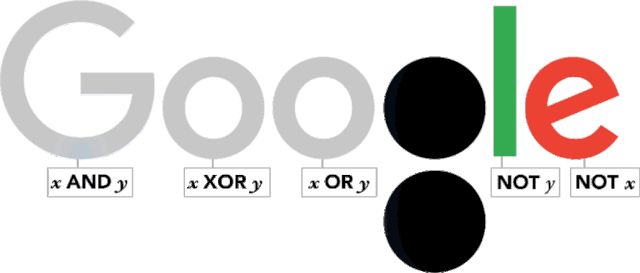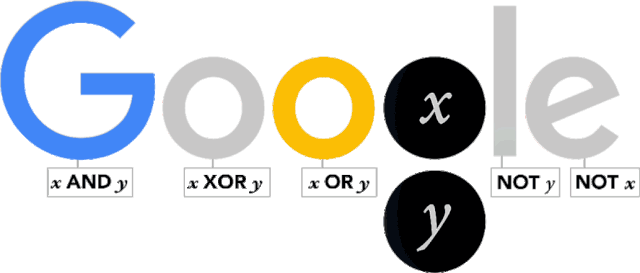
布尔值(Boolean Value)
True
False
逻辑操作符(Logical Operators)
| 逻辑操作符 | 意义 |
|---|---|
| == | 等于 |
| != | 不等于 |
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| in | 属于 |
布尔运算操作符
and
or
not
函数
定义函数
def do_nothing():
pass
变量的作用域
def increase_one(n):
n += 1
return n
n = 1
print(increase_one(n))
print(n)
输出:
2
1
变量有全局变量(Global Variables)和局域变量(Local Variables)之分。
首先,每次某个函数被调用的时候,这个函数会开辟一个新的区域,这个函数内部所有的变量,都是局域变量。也就是说,即便那个函数内部某个变量的名称与它外部的某个全局变量名称相同,它们也不是同一个变量 —— 只是名称相同而已。
其次,更为重要的是,当外部调用一个函数的时候,准确地讲,传递的不是变量,而是那个变量的
值
。也就是说,当
increase_one(n)
被调用的时候,被传递给那个恰好名称也叫
n
的局域变量的,是全局变量
n
的值,
1
。而后,
increase_one()
函数的代码开始执行,局域变量
n
经过
n += 1
之后,其中存储的值是
2
,而后这个值被
return
语句返回,所以,
print(increase(n))
所输出的值是函数被调用之后的返回值,即,
2
。然而,全局变量
n
的值并没有被改变,因为局部变量
n
(它的值是
2
) 和全局变量
n
(它的值还是
1
)只不过是名字相同而已,但它们并不是同一个变量。
化名(alias)
def _is_leap(year):
return year % 4 == 0 and (year % 100 != 0 or year % 400 == 0)
year_leap_bool = _is_leap
匿名(lambda)
lambda 的语法结构如下:
lambda_expr ::= "lambda" [parameter_list] ":" expression
以上使用的是 BNF 标注。
示例:
lambda x, y: x + y
先写上
lambda
这个关键字,其后分为两个部分,
:
之前是参数,之后是表达式;这个表达式的值,就是这个函数的返回值。
注意
:
lambda
语句中,
:
之后有且只能有一个表达式。
而这个函数呢,没有名字,所以被称为 “匿名函数”。
add = lambda x, y: x + y
就相当于是给一个没有名字的函数取了个名字。
递归(Recursion)
例如计算阶乘的程序:
def factorial(n):
if n == 1:
return 1
else:
return n * factorial(n-1)
print(factorial(5))
一个递归函数,之所以是一个有用、有效的递归函数,因为它要遵守递归三原则。正如,一个机器人之所以是个合格的机器人,因为它遵循
阿莫西夫三铁律
(Three Laws of Robotics)一样。(这一类比来自著名的 Python 教程,
Think Python: How to Think Like a Computer Scientist
)
- 根据定义,递归函数必须在内部调用自己;
- 必须设定一个退出条件;
- 递归过程中必须能够逐步达到退出条件……
普林斯顿大学的一个网页,有很多递归的例子
https://introcs.cs.princeton.edu/java/23recursion/
参数
1. 关键字参数(Keyword Arguments,在官方文档里常被缩写为 karg)
例如
sorted(iterable, *, key=None, reverse=False)
中的
key
和
reverse
,也就是有默认值的参数。
2. 位置参数(Positional Arguments,在官方文档里常被缩写为 arg)
例如
divmod(a, b)
中
a
和
b
。
3. 可选位置参数(Optional Positional Arguments)
例如
pow(x, y[, z])
,
exec(object[, globals[, locals]])
。
4. 可接收很多值的位置参数(Arbitrary Positional Argument)
例如
print(*object, sep=' ', end='\n', file=sys.stdout, flush=False)
中的
*object
,说明这个位置可以接收很多个参数(或者说,这个位置可以接收一个列表或者元组)。
def say_hi(*names):
for name in names:
print(f'Hi, {name}!')
say_hi() #无输入参数,不执行
say_hi('ann')
say_hi('mike', 'john', 'zeo')
在函数内部,是把
names
这个参数当作容器处理的 —— 否则也没办法用
for ... in ...
来处理。而在调用函数的时候,我们是可以将一个容器传递给函数的 Arbitrary Positional Arugments 的 —— 做法是,在调用函数的时候,在参数前面加上星号
*
:
def say_hi(*names):
for name in names:
print(f'Hi, {name}!')
names = ('mike', 'john', 'zeo')
say_hi(*names)
5. 可接收很多值的关键字参数(Arbitrary Keyword Argument)
def say_hi(**names_greetings):
for name, greeting in names_greetings.items():
print(f'{greeting}, {name}!')
say_hi(mike='Hello', ann='Oh, my darling', john='Hi')
既然在函数内部,我们在处理接收到的 Arbitrary Keyword Argument 时,用的是对字典的迭代方式,那么,在调用函数的时候,也可以直接使用字典的形式:
def say_hi(**names_greetings):
for name, greeting in names_greetings.items():
print(f'{greeting}, {name}!')
a_dictionary = {'mike':'Hello', 'ann':'Oh, my darling', 'john':'Hi'}
say_hi(**a_dictionary)
say_hi(**{'mike':'Hello', 'ann':'Oh, my darling', 'john':'Hi'})
5. Class也是一种特殊类型的函数
注意:
函数被调用时,面对许多参数,Python 需要按照既定的规则(即,顺序)判定每个参数究竟是哪一类型的参数:
Order of Arguments
- Positional
- Arbitrary Positional
- Keyword
- Arbitrary Keyword
函数的文档
在函数定义内部,我们可以加上
Docstring
;将来函数的 “用户” 就可以通过
help()
这个内建函数,或者
.__doc__
这个 Method 去查看这个 Docstring,即,该函数的 “产品说明书”。
def is_prime(n):
"""
Return a boolean value based upon
whether the argument n is a prime number.
"""
if n < 2:
return False
if n == 2:
return True
for m in range(2, int(n**0.5)+1):
if (n % m) == 0:
return False
else:
return True
help(is_prime)
print(is_prime.__doc__)
is_prime.__doc__
Docstring 如若存在,必须在函数定义的内部语句块的开头,也必须与其它语句一样保持相应的缩进(Indention),放在其它地方不起作用。
有必要认真阅读 Python
PEP 257
关于 Docstring 的规范。简要总结一下 PEP 257 中必须掌握的规范:
- 无论是单行还是多行的 Docstring,一概使用三个双引号扩起;
- 在 Docstring 内部,文字开始之前,以及文字结束之后,都不要有空行;
- 多行 Docstring,第一行是概要,随后空一行,再写其它部分;
- 完善的 Docstring,应该概括清楚以下内容:参数、返回值、可能触发的错误类型、可能的副作用,以及函数的使用限制等等;
- 每个参数的说明都使用单独的一行……
由于我们还没有开始研究 Class,所以,关于 Class 的 Docstring 应该遵守什么样的规范就暂时略过了。然而,这种规范你总是要反复去阅读参照的。关于 Docstring,有两个规范文件:
Sphinx
可以从 .py 文件里提取所有 Docstring,而后生成完整的 Documentation。
数值
| 名称 | 操作 | 结果 | 官方文档链接 |
|---|---|---|---|
| 加 |
|
3 | |
| 减 |
|
1 | |
| 乘 |
|
15 | |
| 除 |
|
3.0 | |
| 商 |
|
2 | |
| 余 |
|
1 | |
| 负 |
|
-6 | |
| 正 |
|
6 | |
| 绝对值 |
|
1 |
|
| 转换为整数 |
|
3 |
|
| 转换为浮点数 |
|
3.0 |
|
| 商余 |
|
2, 1 |
|
| 幂 |
|
1024 |
|
| 幂 |
|
9 |
Python 用来处理数值的内建函数:
abs(n)
函数返回参数
n
的_绝对值_;
int(n)
用来将_浮点数字_
n
换成_整数_;
float(n)
用来将_整数_
n
转换成_浮点数字_;
divmod(n, m)
用来计算
n
除以
m
, 返回两个整数,一个是
商
,另外一个是_余_;
pow(n, m)
用来做乘方运算,返回
n
的
m
次方
;
round(n)
返回离浮点数字
n
最近的那个_整数_。
Python 做更为复杂的数学计算的模块(Module)是 math module,参阅:
字符串
字符码表
ASCII容量为2
8
个字符;
Unicode容量为2
64
个字符。
ord()
:单个字符转码值;
chr()
:码值转单个字符。
可以用4种方法标示字符串:单引号、双引号、三个单引号、三个双引号。
字符串与数值之间的转换
如:
int()
、
float()
、
str()
input()
这个内建函数的功能是接收用户的键盘输入,而后将其作为字符串返回。它可以接收一个字符串作为参数,在接收用户键盘输入之前,会把这个参数输出到屏幕,作为给用户的提示语。这个参数是可选参数,直接写
input()
,即,没有提供参数,那么它在要求用户输入的时候,就没有提示语。
转义符(Escaping Character)
\
另:一个字符串,有两种形式,raw 和 presentation,在后者中,\t 被转换成制表符,\n 被转换成换行。
s = "He said, it's file." # raw
print(s) # presentation
字符串的操作
- 用空格或加号进行拼接;
- 用乘号进行复制;
-
用
in
或
not in
判断是否包含。
字符串的索引
字符串是一种有序容器,如字符串
Python
的正向和逆向索引为:
| 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| P | y | t | h | o | n |
| -6 | -5 | -4 | -3 | -2 | -1 |
切片(Slicing)
我们可以使用
索引操作符
根据
索引
提取
字符串中的
一个或多个元素
,即,其中的字符或字符串。这个 “提取” 的动作叫做 “Slicing”(切片)。索引操作符
[]
中可以有一个、两个或者三个整数参数,如果有两个参数,需要用
:
隔开。它最终可以写成以下的形式:
s[index]
—— 返回索引值为
index
的那个字符
s[start:]
—— 返回从索引值为
start
开始一直到字符串末尾的所有字符
s[start:stop]
—— 返回从索引值为
start
开始一直到索引值为
stop
的那个字符_之前_的所有字符
s[:stop]
—— 返回从字符串开头一直到索引值为
stop
的那个字符_之前_的所有字符
s[start:stop:step]
—— 返回从索引值为
start
开始一直到索引值为
stop
的那个字符_之前_的,以
step
为步长提取的所有字符
提醒:无论是
range(1,2)
,或者
random.randrange(100, 1000)
又或者
s[start:stop]
都有一个相似的规律,包含左侧的
1
,
100
,
start
,不包含右侧的
2
,
1000
,
stop
。
处理字符串的内建函数
ord()
(处理字符)、
input()
、
int()
、
float()
、
len()
、
print()
处理字符串的 Method
字符串是一个str 类(Class str)的对象,有很多可以调用 Methods。
str.upper()
str.lower()
str.swapcase()
:逐个字符更替大小写
str.casefold()
:也是转换成小写,但它能处理更多欧洲语言字符
str.capitalize()
:行(
or句?
)首字母大写
str.title()
:每个词的首字母大写
str.encode()
在处理非英文字符串(比如中文)的时候,经常会用到
str.count()
:搜寻子字符串出现次数
str.find()
:返回最先 sub 出现的那次的位置
str.rfind()
:返回最后 sub 出现的那次的位置
str.index()
:作用与 find() 相同,但如果没找到的话,会触发 ValueError 异常
str.startswith()
和
str.endswith()
是用来判断一个
字符串
是否以某个
子字符串
起始或者结束的
str.replace()
str.expandtabs( tabsize=8)
:专门替换 TAB(
\t
)
str.strip([chars])
:去除子字符,最常用的场景是去除一个字符串首尾的所有空白,包括空格、TAB、换行符等等。但是,如果给定了一个字符串作为参数,那么参数字符串中的所有字母都会被当做需要从首尾剔除的对象
str.lstrip()
:只对左侧处理
str.rstrip()
:只对右侧处理
str.splitlines()
、
str.split()
、
str.partition()
:拆分字符串
str.join()
:拼接字符串
str.center(width[, fillchar])
:将字符串居中放置 —— 前提是设定整行的长度
str.ljust(width)
:将字符串靠左对齐
str.rjust(width)
:将字符串靠右对齐
str.format()
f-string
:与
str.format()
的功用差不多,只是写法简洁一些

容器(Container)
可迭代性?(Iterable)

range()
生成的等差数列就是一个元组。
列表(List)

元组(Tuple)
a = 1, 2, 3 # 不建议这种写法
b = (1, 2, 3) # 在创建元组的时候建议永远不省略圆括号……
注意
:创建单个元素的元组,无论是否使用圆括号,在那唯一的元素后面一定要
补上一个逗号
,
元组是不可变序列,所以,你没办法从里面删除元素。
但是,你可以在末尾追加元素。所以,严格意义上,对元组来讲,“不可变” 的意思是说,“
当前已有部分不可变
”……
集合(Set)
集合不包含重合元素。
注意
:创建空集合的时候,必须用
set()
,而不能用
{}
。
将序列数据转换(Casting) 为Set,就等于去重。
copy()
、
len()
、
max()
、
min()
、
remove(elem)
可用;
del
不可用。
集合运算操作符
- 并集:
|
- 交集:
&
- 差集:
-
- 对称差集:
^
也可用Set类的方法实现:
意义 操作符 方法 方法相当于 并集
\|
set.union(*others)
set \| other \| ...
交集
&
set.intersection(*others)
set & other & ...
差集
-
set.difference(*others)
set - other - ...
对称差集
^
set.symmetric_difference(other)
set ^ other
注意
,并集、交集、差集的方法,可以接收多个集合作为参数
(*other)
,但对称差集方法只接收一个参数
(other)
。
字典(Dictionary)
映射
(Map)容器。
字典里的每个元素,由两部分组成,
key
(键)和
value
(值),二者由一个冒号连接。
迭代各种容器中元素
for i in range(3):
print(i)
输出:
0
1
2
同时得到有序容器中的元素及其索引:
enumerate()
s = 'Python'
for i, c in enumerate(s):
print(i, c)
输出:
0 P
1 y
2 t
3 h
4 o
5 n
迭代前排序:
sorted()
、
reversed()
?
t = ('bob', 'ann', 'john', 'mike', 'joe')
for i, t in enumerate(reversed(t)):
print(i, t)
输出:
0 joe
1 mike
2 john
3 ann
4 bob
同时迭代多个容器:
zip()
(这样做的前提是,多个容器中的元素数量最好相同)
chars='abcdefghijklmnopqrstuvwxyz'
nums=range(1, 27)
for c, n in zip(chars, nums):
print(f"Let's assume {c} represents {n}.")
输出:
Let's assume a represents 1.
Let's assume b represents 2.
Let's assume c represents 3.
Let's assume d represents 4.
Let's assume e represents 5.
Let's assume f represents 6.
Let's assume g represents 7.
Let's assume h represents 8.
Let's assume i represents 9.
Let's assume j represents 10.
Let's assume k represents 11.
Let's assume l represents 12.
Let's assume m represents 13.
Let's assume n represents 14.
Let's assume o represents 15.
Let's assume p represents 16.
Let's assume q represents 17.
Let's assume r represents 18.
Let's assume s represents 19.
Let's assume t represents 20.
Let's assume u represents 21.
Let's assume v represents 22.
Let's assume w represents 23.
Let's assume x represents 24.
Let's assume y represents 25.
Let's assume z represents 26.
迭代字典中的元素:
phonebook1 = {'ann':6575, 'bob':8982, 'joe':2598, 'zoe':1225, 'ann':6585}
for key in phonebook1:
print(key, phonebook1[key])
或:
for key, value in phonebook1.items():
print(key, value)
输出都是:
ann 6585
bob 8982
joe 2598
zoe 1225
文件(文本)
open(file, mode='r')
第二个参数,
mode
,默认值是
'r'
,可用的
mode
有以下几种:
| 参数字符 | 意义 |
|---|---|
|
只读模式 |
|
写入模式(重建) |
|
排他模式 —— 如果文件已存在则打开失败 |
|
追加模式 —— 在已有文件末尾追加 |
|
二进制文件模式 |
|
文本文件模式 (默认) |
|
读写模式(更新) |
一般把这个函数的返回值,一个所谓的
file object
,保存到一个变量中,以便后面调用这个 file object 的各种方法,比如获取文件名
file.name
删除文件,就得调用
os
模块了。删除文件之前,要先确认文件是否存在,否则删除命令会失败。
import os
f = open('test-file.txt', 'w')
print(f.name)
if os.path.exists(f.name):
os.remove(f.name)
print(f'{f.name} deleted.')
else:
print(f'{f.name} does not exist')
创建文件之后,我们可以用
f.write()
方法把数据写入文件,也可以用
f.read()
方法读取文件。
文件有很多行的时候,我们可以用
file.readline()
操作,这个方法每次调用,都会返回文件中的新一行。
file.readlines()
返回的是一个列表。
与之相对的,我们也可以用
file.writelines()
把一个列表写入到一个文件中,按顺序每一行写入列表的对应元素。
with语句块
with open(...) as f:
f.write(...)
...
用
with
语句块的另外一个附加好处就是不用写
file.close()
了
模块
我们可以将以下内容保存到一个名为
mycode.py
的文件中 —— 这样可以被外部调用的
.py
文件,有个专门的称呼,
模块
(Module)—— 于是,其实任何一个
.py
文件都可以被称为模块,比如这个
模块
(
Module
)的名称,就是
mycode
。
当你向 Python 说
import ...
的时候,它要去寻找你所指定的文件,那个文件应该是
import
语句后面引用的名称,再加上
.py
构成的名字的文件。Python 会按照以下顺序去寻找:
- 先去看看内建模块里有没有你所指定的名称;
- 如果没有,那么就按照
sys.path
所返回的目录列表顺序去找。
有时,你需要指定检索目录,因为你知道你要用的模块文件在什么位置,那么可以用
sys.path.append()
添加一个搜索位置:
import sys
sys.path.append("/My/Path/To/Module/Directory")
import my_module
获取系统内建模块的列表:
sys.builtin_module_names
当你使用
import mycode
的时候,你向当前工作空间引入了
mycode
文件中定义的所有函数,相当于:
from mycode import *
只引入
mycode
中的
is_prime()
:
from mycode import is_prime
这种情况下,你就不必使用
mycode.is_prime()
了;而是就好像这个函数就写在当前工作空间一样,直接写
is_prime()
。
注意
,如果当前目录中并没有
mycode.py
这个文件,那么,
mycode
会被当作目录名再被尝试一次,如果当前目录内,有个叫做
mycode
的目录(或称文件夹),那么,
from mycode import *
的作用就是把
mycode
这个文件夹中的所有
.py
文件全部导入……
如果我们想要导入
foo
这个目录中的
bar.py
这个模块文件,那么,可以这么写:
import foo.bar
或者
from foo import bar
有的时候,或者为了避免混淆,或者为了避免输入太多字符,我们可以为引入的函数设定
化名
(alias),而后使用化名调用函数。比如:
from mycode import is_prime as isp
import mycode as m
你的函数,保存在模块里之后,这个函数的用户(当然也包括你),可以用
dir()
函数查看模块中可触达的变量名称和函数名称。
附
:一个模块文件中,不一定只包含函数;它也可以包含函数之外的可执行代码。只不过,在
import
语句执行的时候,模块中的非函数部分的可执行代码,只执行一次。有一个 Python 的彩蛋,恰好是可以用在此处的最佳例子 —— 这个模块是
this
,它的文件名是
this.py
。
try
在 Python 中,我们可以用
try
语句块去执行那些可能出现 “意外” 的语句,
try
也可以配合
except
、
else
、
finally
使用。从另外一个角度看,
try
语句块也是一种特殊的流程控制,专注于 “当意外发生时应该怎么办?”
try:
do_something()
except built_in_error as name_of_error:
do_something()
else:
do_something()
finally:
do_something()
可执行的Python文件
当一个模块(其实就是存有 Python 代码的
.py
文件)被导入,或者被执行的时候,这个模块的
__name__
被设定为
__main__
。
把一个程序整个封装到
main()
之中,而后在模块代码里加上:
if __name__ == '__main__':
main()
这么做的结果是:
- 当 Python 文件被当作模块,被
import
语句导入时,
main()
函数不被直接运行;- 当 Python 文件被
python (-m)
执行的时候,
main()
才被执行。(有
-m
参数,就不要写文件尾缀
.py
)
资料链接
操作符优先级:
Operator precedence