指代消解
指代消解技术主要用于解决多个指称对应同一实体对象的问题。在一次会话中,
多个指称可能指向的是同一实体对象。利用共指消解技术,可以将这些指称项关联(合并)到正确的实体对象,共指消解还有一些其他的名字,比如对象对齐、实体匹配和实体同义。指代理解可以看成是对文本的压缩。
书中给出了一个自然语言处理的java包,并没有说明指代消解原理,查阅资料得到如下指代消解原理
指代消解中的Hobbs算法和向心理论
基于自然语言处理的共指消解是以句法分析为基础的,代表方法是Hobbs算法和向心理论(centering theory)。
Hobbs算法是最早的代词消解算法之一,主要思路是基于句法分析树进行搜索,因此适用于实体与代词出现在同一句子中的场景,有一定的局限性。
向心理论的基本思想是:将表达模式(utterance)视为语篇(discourse)的基本组成单元,通过识别表达式中的实体,可以获得当前和后续语篇中的关注中心(实体),根据语义的局部连贯性和显著性,就可以在语篇中跟踪受关注的实体。
在机器学习中,指代算法常常被看成是分类与聚类问题。聚类法的基本思想是以实体指称项为中心,通过实体聚类实现指称项与实体对象的匹配。基于统计机器学习的共指消解方法通常受限于2个问题:训练数据的(特征)稀疏性和难以在不同的概念上下文中建立实体关联。
中文关键词提取;
中文关键词提取分以下几个步骤
- 文本、系统参数输入
- 分词、过滤停用词
- 单个词的权重计算、排序
-
文本关键词
不同位置、词性的词语重要程度不同,可根据以下规则:
· 标题出现的词更重要
· 利用词性信息:关键词往往是名词或者名词结尾的词
· 利用词或字的互信息,互信息大的单子有可能是关键词
· 利用标点符号:《》和“”之间的字
· 构建文本词网络
· 把出现的名词词语按语义聚类,提取有概括性的词作为关键词
HITS算法提取关键字
词汇权重计算可采用HITS算法,Pangrank算法,TF-IDF算法等。后两者我们比较熟悉,书中详细介绍了HITS算法
HITS(HITS(Hyperlink – Induced Topic Search) )是信息检索中计算网页排序的常用算法。
Hub页面(枢纽页面)和Authority页面(权威页面)是HITS算法最基本的两个定义:
- “Authority”页面,是指与某个领域或者某个话题相关的高质量网页,比如搜索引擎领域,Google和百度首页即该领域的高质量网页,比如视频领域,优酷和土豆首页即该领域的高质量网页。
-
“Hub”页面,指的是包含了很多指向高质量“Authority”页面链接的网页,比如hao123首页可以认为是一个典型的高质量“Hub”网页。
将网页看成节点,计算Aut值和Hub值:
1.开始设置每个节点的Hub值和Authority值为1
2.执行Authority更新规则
3.执行Hub值更新规则
4.对Hub值和Authority值归一化
5.重复步骤2直到达到指定迭代次数,或Hub值和Authority值变化很小时停止迭代。
重复迭代过程直到满足条件,就构造了一个有向带权图,根据图可以算出最重要的节点,即关键字。
信息提取
信息抽取的定义为:从自然语言文本中抽取指定类型的实体、关系、事件等事实信息,并形成结构化数据输出的文本处理技术
信息抽取是从文本数据中抽取特定信息的一种技术。文本数据是由一些具体的单位构成的,例如句子、段落、篇章,文本信息正是由一些小的具体的单位构成的,例如字、词、词组、句子、段落或是这些具体的单位的组合。抽取文本数据中的名词短语、人名、地名等都是文本信息抽取。
信息提取遵循以下流程:
1.根据利用信息的方式定义词的类别
2.定义专业词库并根据词库对输入文档做全切分
3.最大概率动态规划求解
4.HMM词性标注
5.基于规则的未登录词识别
6.根据切分和标注的结果提取信息
提取联系方式
提取联系方式采用基于规则的提取:先建立相关字典,储存所要抓取对象的必要的特征信息(如前缀信息、后缀信息等),再根据所要提取的信息特征定义一些规则,用于提取用户所要定义的对象。
从互联网提取信息
Web内容高度冗余,利用实体间得关系和描述这些关系得模式之间得对应关系,从一个种子关系集合出发,从Web网页中发现这些种子出现得上下文,然后从这些上下文中产生对应的模式,进而利用这些模式从Web网页中发现更多得关系实例,然后从这些关系实例中选择新的种子集合,重复上述过程,迭代得从Web上得到相应得关系和模板。
拼写纠错;
拼写纠错也成查询纠错,对输入的错误文本进行纠错。纠错的流程为:
1.输出查询
2.在词典中进行模糊匹配
3.返回词典中匹配词语
4.给出纠错建议。
它的通用公式如下:
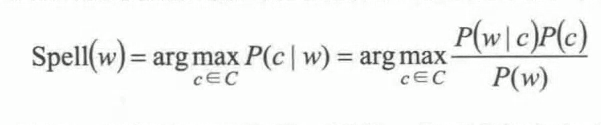
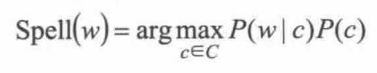
P(c)是正确单词先验概率,P(w|c)是单词c误拼为w的概率,argmaxP(w|c) P(c) 即为输出是w的情况下所有可能单词中概率最大的一个,将这个单词c视为纠错建议。