这个坑说大不大,说小遇到了也头疼。一般我们把dataframe直接写到Excel文件,直接 df.to_excel即可。不过如果想把多个表格写入同一个工作表呢,那就需要用openpyxl的dataframe_to_rows功能。看下面一段代码。
import pandas as pd
from openpyxl import Workbook
from openpyxl.utils.dataframe import dataframe_to_rows
df1=pd.DataFrame([[1,4],[2,5],[3,6]] ,index=['a','b','c'],columns=['a','b'])
df2=pd.DataFrame([[1,4],[2,5],[3,6],[7,8]] ,index=['d','e','f','g'],columns=['a','b'])
wb=Workbook()
ws=wb.active #打开工作表
#把df1写入工作表
for row in dataframe_to_rows(df1):
ws.append(row)
#换行
ws.append([])
#把df2写入工作表
for row in dataframe_to_rows(df2):
ws.append(row)
wb.save('text.xlsx')
这段代码就是把df1,df2都写入到一个工作表,但一看结果,傻了,怎么标题行和内容之间多了空行啊

看看空行是如何产生的呢
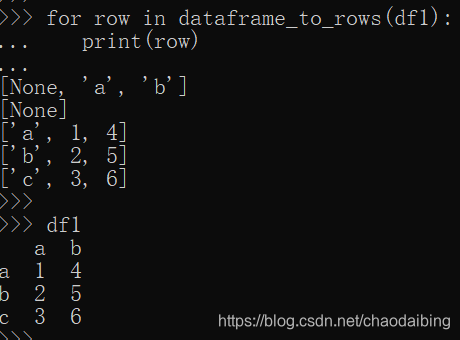
原来多了一个None啊,难怪是空行,目测None是index带来的,那就把index去掉呗

这回None是没有了,但是index的内容也想要显示,怎么办呢,这么办:

哈哈,这样就完美了。这里reset_index的意思就是把index列,变成普通列,比如:

如上图,如果直接reset_index,index列变成普通列,但是列头自动变成了index,这可不好,所以先给index列赋值,也就是df1.index.name=‘code’
最后代码如下
import pandas as pd
from openpyxl import Workbook
from openpyxl.utils.dataframe import dataframe_to_rows
df1=pd.DataFrame([[1,4],[2,5],[3,6]] ,index=['a','b','c'],columns=['a','b'])
df2=pd.DataFrame([[1,4],[2,5],[3,6],[7,8]] ,index=['d','e','f','g'],columns=['a','b'])
wb=Workbook()
ws=wb.active #打开工作表
df1.index.name='code1'
df2.index.name='code2'
#把df1写入工作表
for row in dataframe_to_rows(df1.reset_index(),index=False):
ws.append(row)
#换行
ws.append([])
#把df2写入工作表
for row in dataframe_to_rows(df2.reset_index(),index=False):
ws.append(row)
wb.save('text.xlsx')
结果,哈哈,完美

版权声明:本文为chaodaibing原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。