文心Ernie技术原理
一、背景技术
Ernie是基于Bert模型进行改进,基本模型是Transformer,Bert完成的预训练任务是:完形填空(通过基本语言单元掩码);上下句预测。
Bert模型的缺陷是:只能捕获局部的语言信号,缺乏对句子全局的建模,从而难以学习到词、短语、实体的完整语义。

Bert模型的训练任务之一是掩码语言模型,它将单个的字(中文)、词(英文)进行随机mask标记后,去预测被mask的值。掩码语言模型使得Bert具有良好的效果,但同时巨大的缺陷是将句子的字与字或词与词之间的关系拆散了。在上图中,将哈尔滨的尔字mask后,就拆散了原本的词语内部关系。
二、Ernie1.0的改进之处
针对Bert模型的缺陷,Ernie使用的掩码语言模型mask的不是单个的字或词,而是完整的词语、短语、命名实体。遮盖住后预测整体,从而使得语言模型能够训练出较好的全局信息,能够学习到非常先验的结果。
百度经过大量的训练,训练出效果较好的分词模型、短语拼接模型以及命名实体识别的模型,提前将语料中的词语进行标记。(在论文中这个思想称为:知识融合)
三、Ernie1.0的效果

四、Ernie2.0的改进之处
持续学习语义理解框架
主要思想: 不断学习预料中的不同层次的任务和知识,从而去增强Ernie模型语义表示的建模能力。
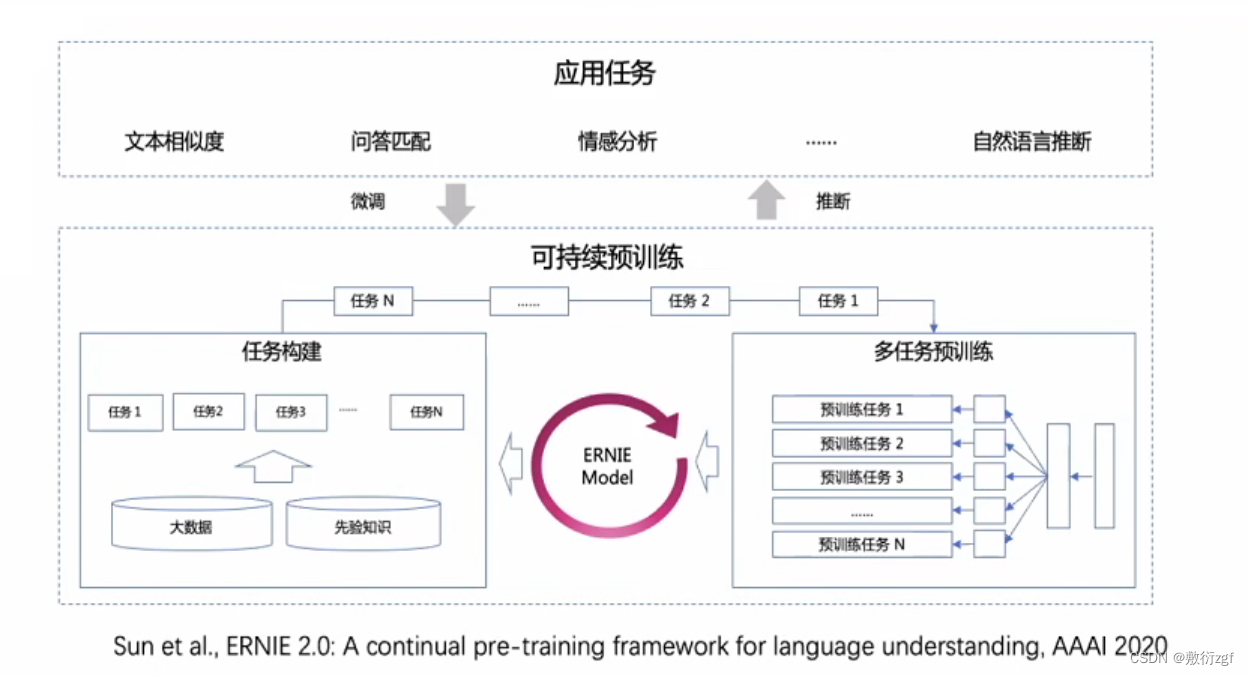
首先从大数据和先验知识中随机的构建不同的预训练任务,接下来将任务逐渐加入到多任务训练器中进行多任务预训练,从而加强Ernie模型的能力。得到预训练模型后,利用多任务预训练数据去针对不同的应用任务微调即可。
五、Ernie2.0的模型结构
Ernie模型将四大部分作为输入,分别为:
1.Token embedding:词向量本身的embedding
2.Sentence embedding:句子类型的embedding
3.Position embedding:位置信息的embedding
4.Task embedding:任务embedding建模不同的任务
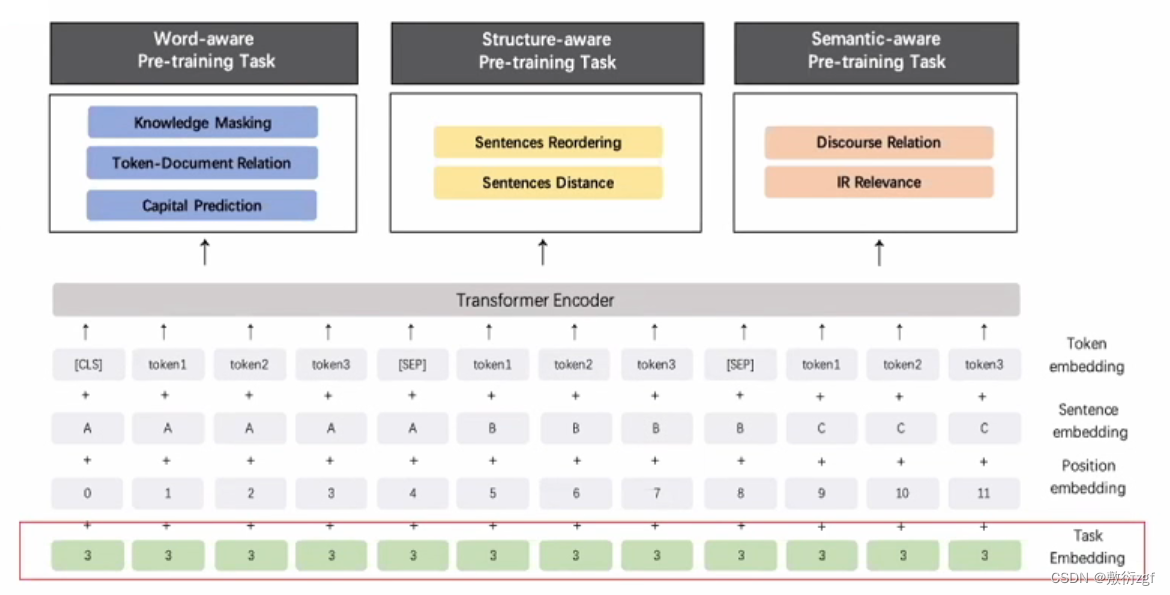
将四大embedding相加,最终的结果作为Transformer的输入,训练不同的子任务。子任务分为三类,分别为:
1.Word-aware Pre-training Task 词法层面的预训练任务;
2.Structure-aware Pre-training Task 结构层面的预训练任务;
3.Semantic-aware Pre-training Task 语义层面的预训练任务。
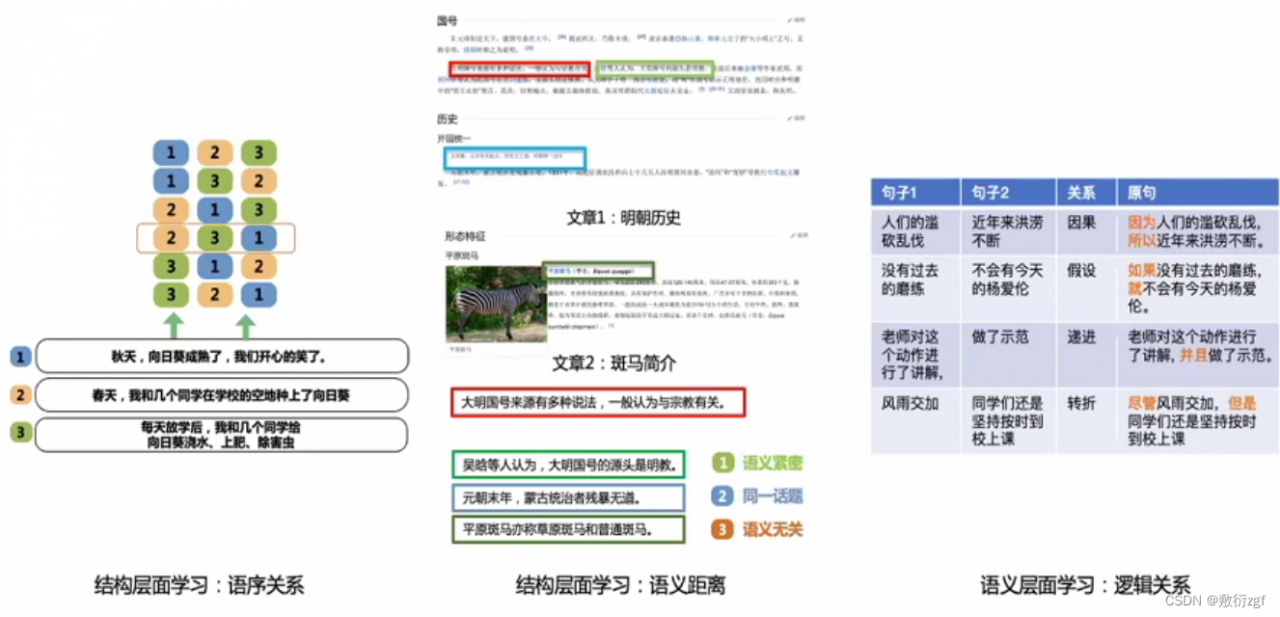
列举了Ernie2.0中几个具有特色的任务:
1.语序关系:判断几段文本的语序;
2.语义距离:判断语义远近关系;
3.逻辑关系:判断文本之间的逻辑关系。
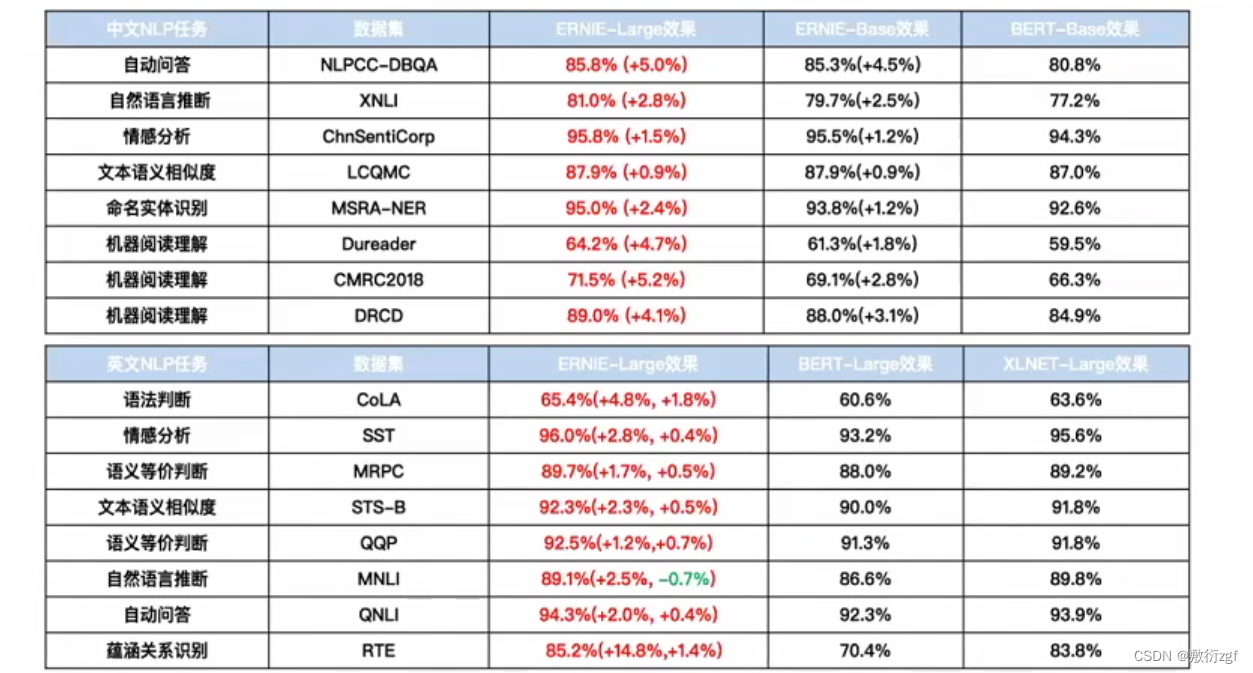
六、Ernie3.0的模型效果
七、Ernie Tiny模型
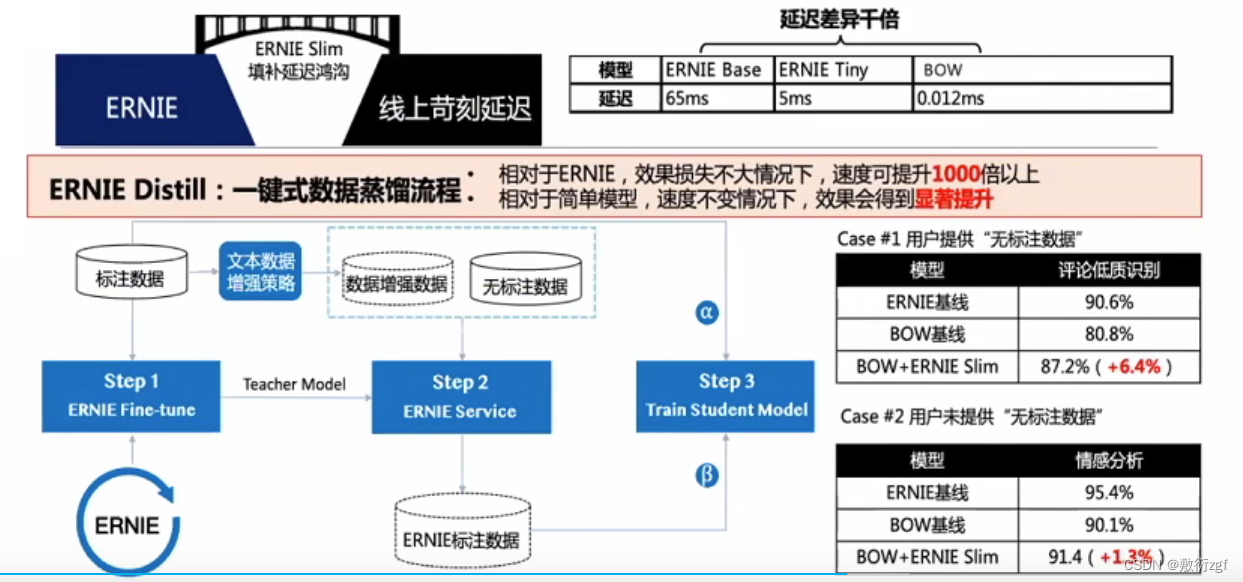
效果很显著,但速度提升较少。
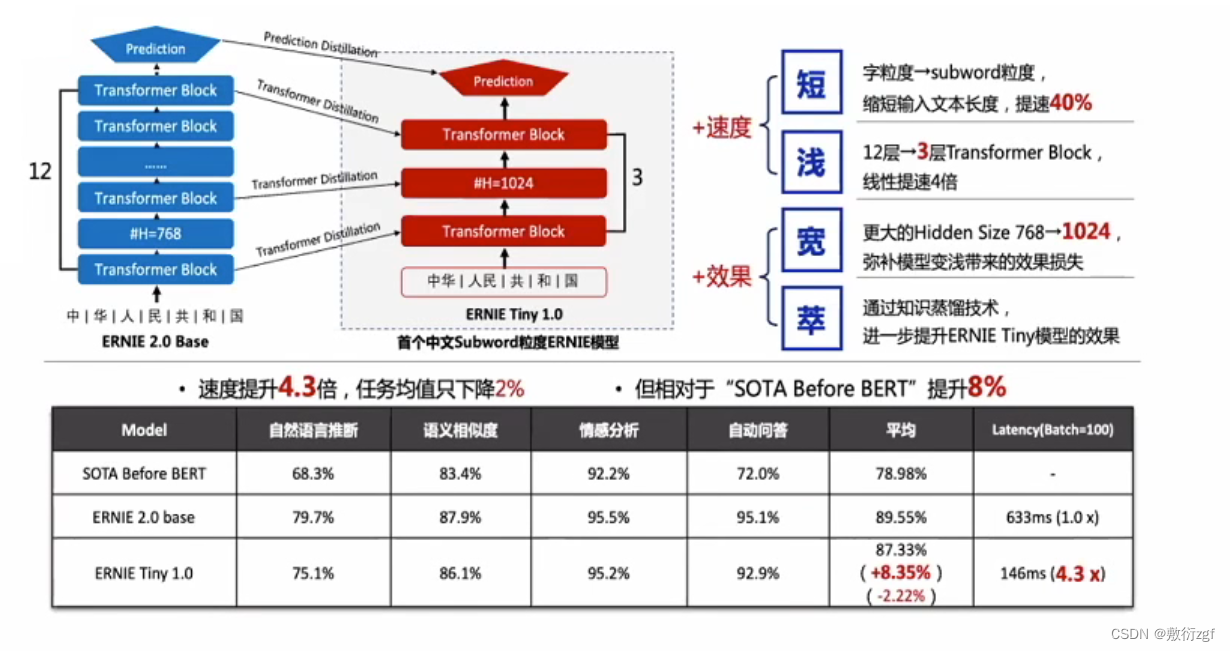
Ernie Distill 提速千倍,降低应用资源开销