作者简介
Jay,携程高级算法经理,关注机器学习和深度学习领域在酒店场景可落地的相关技术。
引言
近年来,得益于深度学习的巨大发展,自然语言处理(NLP)领域也爆发了多个如 BERT 等state-of-the-art模型,供从业人员使用。但是这些开源的最先进的模型大多是在通用的基准数据集上训练得到的,当我们在具体工业场景中使用时往往还是需要在具体使用场景的数据集上进行微调。获得这些特定领域数据集的传统方式是人工标注。这些手工标注的数据集创建起来既昂贵又耗时,特别是对于一些比较难的任务往往人工标记的准确度也无法达到要求。
一、大量标注数据在深度学习任务中的重要性
1.1 训练数据瓶颈

即便深度学习的基石——神经网络早在1943年就被提出,但是深度学习在近十多年才获得了突飞猛进的发展。究其原因,深度学习的成功需要满足三大要素:先进的模型、大量的数据和高性能的硬件。对于深度学习领域的从业者来说,得益于大量的研究人员和开源社区,三大要素之一的最先进的深度学习模型也变得唾手可得。随着GPU和云计算的发展,高性能的硬件也不再遥不可及。然而,要收集足够多的标注数据,在这些硬件上训练这些开源模型,并不像看上去的这么简单。事实上,这个障碍已经成为大多数机器学习应用的主要瓶颈。所以说,当前深度学习项目的成功往往取决于一个隐性成本:庞大的、手工标注的训练数据集。
1.2 人工标注数据的劣势
手动标注训练数据非常昂贵,尤其是在需要专业知识和隐私的情况下。建立训练数据集通常需要大量的标注人员,这需要大量的成本和时间。例如,ImageNet是ML在图像领域获得爆炸性发展背后的基础项目之一,需要花费两年多的时间来创建。但是,给猫、狗、停车标志和行人打标是一回事;标记医学图像、法律和金融合同、政府文档、用户数据和网络数据等数据需要严格的隐私保护和主题专家标注。这意味着对于金融服务、政府、电信、保险、医疗保健等行业,人工创建训练数据是非常昂贵的,或者是无法实现的。
手动标注的数据不可能进行迭代开发。 从工程和数据科学的角度来看,手动标记的训练数据从根本上破坏了快速迭代的能力。这在输入数据、输出目标和注释模式始终在变化的现实环境中至关重要。从业务的角度看,训练数据是一项昂贵的资产。如果不能在各个项目中重复使用,那么由于条件或业务目标的变化,这些数据的价值通常会飞速地衰减。
正是由于人工标注的种种劣势,研究人员不得不思考其它能快速产出有效标注数据的方法。弱监督学习框架 Snorkel 便是其中一种。
二、Snorkel 框架介绍
Snorkel 是一种快速产出训练数据的弱监督系统,利用标签函数,可以快速产生、管理、建模训练数据。
在Snorkel中,不需要使用手工标记的训练数据,而是要求用户编写标记函数 (labeling functions, LF),即用于标记未标记数据子集的黑盒代码片段。
研究人员可以使用一组这样的标注函数来为机器学习模型标注训练数据。由于标记函数只是任意的代码片段,所以它们可以对任意信号进行编码:模式、启发式、外部数据资源、来自众包人员的带噪声的标签、弱分类器等等。还可以获得标注函数作为代码所特有的优点,比如模块化、可重用性和可调试性。例如,如果建模目标发生了变化,可以调整标注函数来快速适应这种变化。
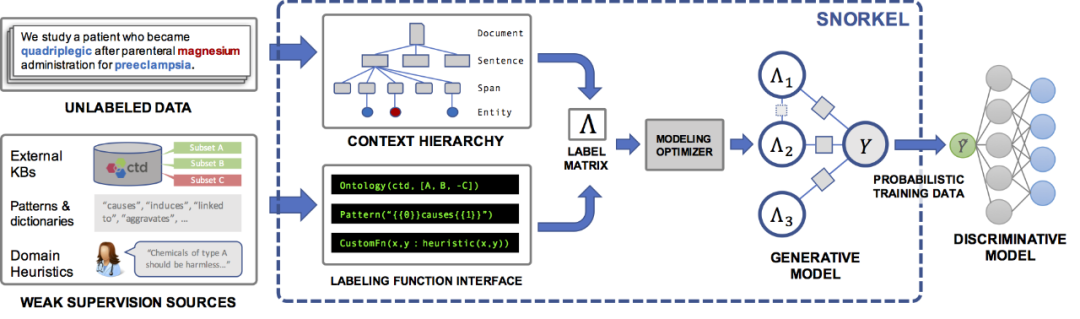
三、Snorkel 在携程客服“事件小结”场景的应用
随着OTA(在线旅游代理商)的快速发展,越来越多的用户选择在线预定酒店。客服中心作为公司和客户的连接枢纽,是整个服务链中的关键一环。对于携程而言,提高客服人员的服务效率,是降低公司成本和提高服务质量的重要工作。
携程酒店客服每天需要处理大量的用户进线来解答或处理用户的问题。通常需要一套复杂的工单系统来记录、流转和考核客服处理的用户事件。在工单系统中当客服需要协助、转移、升级、完成事件时,通常需要手工编写一个该事件的小结来告诉下一步的处理人员事件的关键信息,耗费客服大量的时间。而客服每日解决的用户进线量很大,这导致大量客服资源的占用;另外,手工撰写的事件小结质量参差不齐,错误或者不规范的小结会给接手客服人员的工作带来负面影响,降低效率。
作为算法开发人员,我们希望通过人工智能技术,通过客服和客人的会话内容再辅助一些其它系统信息,能够帮助客服人员自动生成准确的结构化事件小结,一方面能够节省客服撰写的时间,另一方面准确且结构化信息能够提高事件的流转效率。

下面以一个简单的场景详述一下 Snorkel 开发的大致流程:我们需要根据用户和客服的会话内容来识别出本事件最终的结果作为结构化事件小结的”结果回复”字段;在这里事件的结果主要可以分为两个类别,即酒店同意和酒店拒绝,所以我们需要训练一个分类模型以会话文本作为输入来预测出其对应的类别。
3.1 工作流

我们采用 Snorkel 框架进行数据标注开发的流程一般如上图所示:
1)首先会概览和分析收集到的待标注数据,寻找一些编写标注函数的思路;
2)编写标注函数,原则是对于一个标注函数应该在保证高准确率(高于50%)的前提下,再考虑覆盖率;
3)采用投票模型作为基准模型来筛选标注函数集;
4)对于准确率达不到阈值的标注函数可以返回到第1步来继续优化,直到准确率达标;对于无法优化的标注函数可以直接放弃;
5)在训练集上执行经过投票模型筛选的标注函数来训练标注模型,应当至少达到60%的覆盖率;
6)将所有待标注数据输入生成式模型,产出每个样本的最终标签;
7)用前面生成的带标签样本作为训练集来训练一个判别式模型,并最终线上部署使用该判别式模型。
3.2 数据概览
我们收集了客服和客人聊天的会话历史数据,它们一开始都是无标签的。选取一小部分数据先让较有经验的员工进行人工标注,需要尽量保证这部分标签的正确性,将这一小部分有标签数据作为测试集,用于测试 Snorkel 标注模型的效果。另外一大部分无标签的数据作为 Snorkel 训练集,训练集最终会输入训练好的标注模型来产出最终的标注数据。
首先需要概览无标签标注集中的样本,进行必要的分析,探索一些可以编写标注函数的思路。
3.3 编写标注函数

如上图所示,编写标注函数(Labeling Function)时首先需要定义标签,这里分别定义了酒店同意和酒店拒绝标签,其中 ABSTAIN=-1为所有标注函数的公共标签,表示该标注函数无法判断出样本的标签,对这个样本的判别弃权。
在Snorkel中,有如下这些常见类型的标注函数:
-
关键字搜索:在句子中查找特定的单词,通常使用正则表达式
-
模式匹配:寻找特定的句法模式,例如,使用spaCy的依存树
-
第三方模型:使用预先训练的模型(通常是用于与当前任务不同的任务的模型)
-
远程监督:使用外部知识库
-
有噪声人工标注:众包标注
由于我们任务的输入是文本,所以首先想到可以用正则的方式来编写标注函数。可以根据文本中的关键字来判定样本的标签,一般一个标注函数来提取一个标签,如果无法判断则返回-1。
除了使用正则来编写标注函数之外,还可以使用一个文本情感分析模型来编写标注函数,如果文本情感是正向的表示酒店同意,反之文本情感为负向的表示酒店拒绝。此外,还可以借助工单系统中的一些操作日志来辅助判断酒店是否同意来编写标注函数。
最后需要指出的是,在设计标注函数时,应该偏重于精确度而非召回率。
3.4 训练生成式模型
当编写完标注函数后,Snorkel将利用所有标注函数之间的预测结果与冲突来训练一个标注模型。当标注新的数据时,每个标注函数都会投票:正、负或弃权。基于这些投票以及标注函数的权重,标注模型能够为百万级数据点自动进行概率型标注。最终目标是训练一个可以超过标注函数性能的分类器。
可以这样理解,按照前面要求编写出的所有标注函数实际上就是一个个弱分类器,这些弱分类器有着一定的准确率和召回率,标注模型实际上是通过概率图模型的方式把这些弱分类器结合起来了,从而达到比单个弱分类器更好的效果。

在正式训练标注模型之前,我们可以采用投票模型 MajorityLabelVoter 作为基线模型进行测试,将该结果作为基线指标 。

标注模型训练好之后我们可以查看每个标注函数的相关指标:

如上图为一小部分标注函数,其中一些重要的指标含义如下:
-
Polarity:标注函数返回值的极性,即该标注函数返回的类别,弃权的除外。
-
Coverage:覆盖率,被成功标注(正或负)的样本占比。需要尽可能提高这个值,同时保持良好的准确率。
-
Overlaps & Conflicts:一个标注函数与其他标注函数的重叠与冲突情况。标注模型将使用这些信息来估算每个标注函数的准确率。
-
Accuracy:正确的标注函数预测比例。所有的标注函数都应当不低于0.5。

另外需要注意的一点,在标注模型训练时,某些数据点没有收到任何LF的标签。这些数据点没有传达任何监督信号,并且往往会损害性能,因此我们在使用
内置实用程序
进行训练之前将其过滤掉 。
3.5 训练判别式模型
有了前面标注模型产出的大量有标签数据,我们就可以利用这些数据训练一个判别式模型。但是我们不禁想问既然前面的标注模型已经可以准确的判定出样本的类别了,为什么还要再训练一个判别式模型呢?这个问题就需要从生成式模型和判别式模型的区别来说起。

生成式模型由数据学习联合概率分布 P(X,Y),然后求出条件概率分布 P(Y|X) 作为预测模型,即生成式模型为:
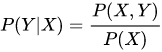
而判别式模型是由数据直接学习条件概率分布 P(Y|X) 作为预测的模型。
根据两者的区别我们可以看出,首先通过生成式模型产出的数据训练出的判别式模型可以提高模型的覆盖度。因为生成式模型需要学习联合概率分布 P(X,Y),但是对于那些所有标注函数都无法覆盖的数据显然是无法得到 P(X,Y) 的,相反判别式模型只需要 X 本身的特征就可以算出 P(Y|X),所以判别式模型可以覆盖那些生成式模型覆盖不到的数据点。
其次,相对于生成式模型训练时采用的概率图模型,判别式模型可以采用更加先进复杂的模型来训练,比如我们采用的 bert 模型,这样也可以提高模型的准确率。
3.6 模型效果对比

baseline 模型是我们在使用 Snorkel 之前采用纯规则实现的,可以看到覆盖度和准确率都是最低的。由于事件小结这个场景在现实中是类别不平衡的,我们将小类别商家拒绝作为正类,而商家同意为负类。因为商家拒绝产生的事件影响会更大,所以我们应该更关注正类的效果。baseline 模型中虽然正类的准确率达到了63.64%,但是正类的召回率只有15.22%,显然达不到要求。
在编写完所有的标注函数之后,我们通常会用 Snorkel 自带的投票模型来评估所有标注函数组合起来的效果,如果效果不好需要继续优化或者废弃相应的标注函数。经过多轮迭代之后,投票模型的效果得到了不错的提升,其中覆盖度提升了8.94%,准确率提升了11.85%。正负类的准确率和召回率也都有较大的提高。
经过投票模型校验过的标注函数集在训练集上进行训练得到一个生成式模型即 label model,相对于投票模型只是采用了简单投票机制,label model 使用概率图模型来学习各个 LF 之间的关系。最终 label model 相对投票模型在覆盖度上提升了1.2%,准确率提升0.25%。虽然在总的覆盖度和准确率上都稍有提升,但是正类的召回率依然不是太高,只有58.7%。
将所有无标签标注集样本采用 label model 进行打标,产出大量的标注数据来训练一个判别式模型。判别式模型我们采用了 bert 模型,最终各项指标都达到了令人满意的效果,特别是对于正类的准确率和召回率都比生成式模型有了很大的提升,分别是正类准确率提升了19.19%,正类召回率提升了21.73%。
四、下一步

除了可以通过编写标注函数(LF)来使用弱监督的方式生成标注训练集之外,Snorkel 还提供了以下两种可以提高模型性能的范式:
转换函数(TF),通过转换现有样本来启发式地生成新的样本,该策略通常称为数据增强。Snorkel 不需要用户手动调整这些数据增强策略,而是使用可以自动学习的数据增强策略。
切片函数(SF),为用户提供了一个接口,用于粗略地识别那些模型应为其提供额外表示能力的数据子集。以多任务学习的方式对切片进行建模,其中使用基于切片的「专家头部」来学习特定切片的表示。然后,通过为专家头部引入注意力机制,以确定何时以及如何在每个示例的基础上组合由这些切片头部学习到的表示。
通过在实际场景上落地 Snorkel 自动标注数据框架的实践,我们探索和验证了采用非人工标注文本数据的方式来建立训练数据集的可行性。为了能进一步提升模型在实际场景中的性能,我们下一步将继续探索 Snorkel 框架中的转换函数和切片函数这两种范式在实际项目中的效果。
团队招聘信息
我们是携程酒店研发团队,聚焦于通过技术创新提升酒店行业效率及全球用户的预订体验。
面对海量的全球酒店数据,我们打造了中台服务,提供高并发、高稳定性的微服务。通过数据驱动的方式,不断提升AI算法在场景上的优化,为用户创造价值。
期待你的加入,目前后端/前端/移动端/数据/算法等方向均有职位开放。简历投递邮箱:
tech@trip.com
,邮件标题:【姓名】-【携程酒店研发】- 【职位】
【推荐阅读】

“携程技术”公众号
分享,交流,成长