DERT 目标检测

基于卷积神经网络的目标检测回顾
双阶段代表检测算法:faster rcnn
单阶段代表算法:yolo
上述单双阶段都是基于anchor
目标检测广泛的使用NMS(非极大值抑制算法)
DETR抛弃了上述算法思路。基于编码器和解码器来进行目标检测
DETR对比Swin Transformer
之前的Swin TransformerSwin Transformer 主要用于目标检测的编码器部分,而不是解码器部分。
在目标检测中,通常会使用两个主要组件:编码器和解码器。编码器负责提取输入图像的特征,而解码器则负责将这些特征转换为目标检测结果。Swin Transformer 主要用作编码器,它通过多层的 Transformer 模块来提取图像特征。
至于解码器部分,可以采用其他的方法来完成目标检测任务。常见的解码器包括使用卷积神经网络 (CNN) 或者其他的传统机器学习算法。具体选择哪种解码器取决于具体的任务和需求。
总结起来,Swin Transformer 在目标检测中主要用作编码器部分,而解码器部分可以根据需求选择其他方法来完成。
摘要

我们提出的新方法将物体检测视为一个直接的集合预测问题。我们的方法简化了检测流水线,有效地消除了对许多手工设计组件的需求,如非最大抑制程序或锚点生成,这些组件明确地编码了我们对任务的先验知识。新框架被称为 DEtection TRansformer 或 DETR,
其主要成分是基于集合的全局损失(通过两端匹配强制进行唯一预测)和变换器编码器-解码器架构
。DETR 给定了一小组固定的已学对象查询,通过推理对象之间的关系和全局图像上下文,直接并行输出最终的预测结果。与许多其他现代检测器不同,新模型概念简单,不需要专门的库。在极具挑战性的 COCO 物体检测数据集上,DETR 的准确性和运行时间性能与成熟且高度优化的 Faster RCNN 基准相当。此外,DETR 可以很容易地通用于以统一的方式进行全视角分割。我们的研究表明,DETR 的性能明显优于竞争基线。训练代码和预训练模型见 https://github.com/facebookresearch/detr。
检测网络流程
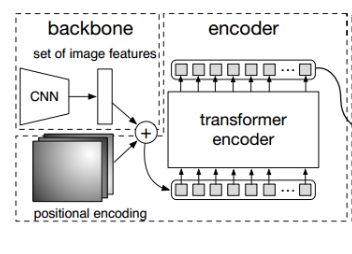
先使用CNN得到各个Patch作为输入,在套用Transformer做编码解码结构
编码和Vision Transformer一致,重点在于解码,直接预测100个坐标框
预测的100个框当中,包括物体和非物体。

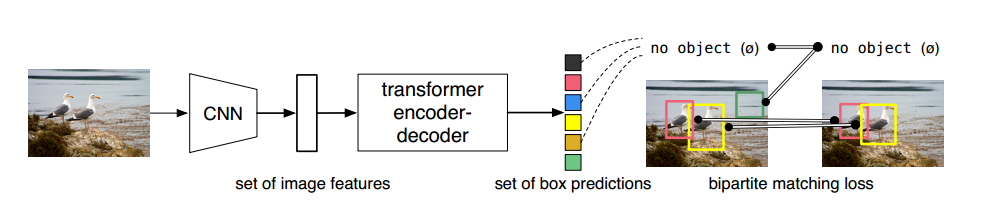
我们的 DEtection TRansformer(DETR,见图 1)可一次性预测所有物体,并使用集合损失函数进行端到端训练,在预测物体和地面实况物体之间进行双向匹配。DETR 通过放弃多个手工设计的、编码先验知识(如空间锚点或非最大抑制)的组件来简化检测管道。与现有的大多数检测方法不同,DETR 不需要任何定制层,因此可以在任何包含标准 CNN 和转换器类的框架中轻松复制1。
大致思路就是:在编码器部分输入的100个向量,通过解码器输出,完成100个检测框的预测
较NLP的区别是:词语之间是有前后的对应关系的,检测是100个向量同时输入
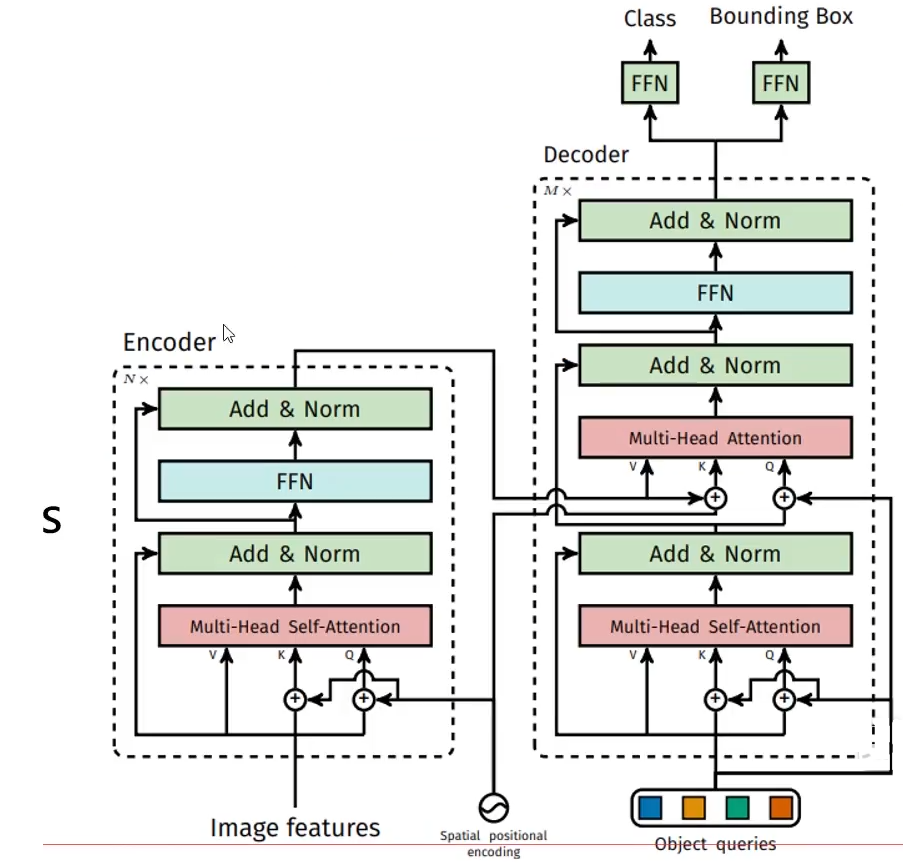
DERT网络架构
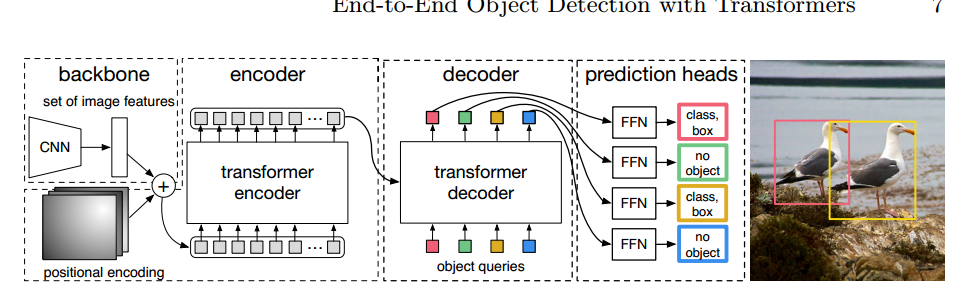

DETR 使用传统的 CNN 骨干来学习输入图像的二维表示。该模型将其扁平化,并辅以位置编码,然后将其传递给变换器编码器。然后,变换解码器将少量固定数量的已学位置嵌入(我们称之为对象查询)作为输入,并额外关注编码器的输出。我们将解码器的每个输出嵌入信息传递给一个共享前馈网络(FFN),该网络可以预测检测结果(类别和边界框)或 “无对象 “类别。
其实
就是和VIT一模一样的
编码器概述


编码器对一组参考点的自我关注。编码器能够分离单个实例。使用基准 DETR 模型对验证集图像进行预测。
得到各个目标的注意力结果,准备好特征,等解码器来匹配
解码器概述
解码器阶段首先初始化100个向量 (object queries)
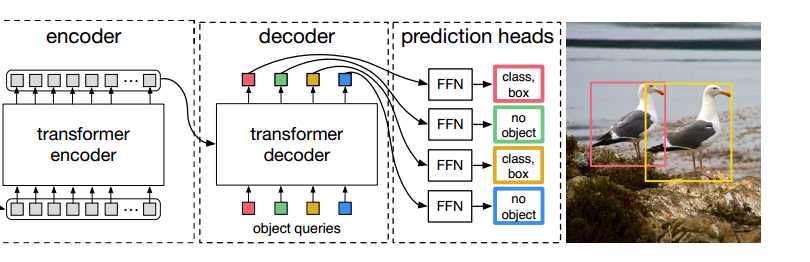
可以把encoder看成生产者,decoder看成消费者
encoder提供 k 和 v
decoder提供 q, 并使用q去查询匹配 k 和 v
在解码器中,所有的object queries同时去查询匹配编码器中每个位置的k和v
解码器输出的结果经过全连接层得到检测框的位置和目标得分
object queries是核心,让他学会从原始特征数据中找到物体的位置
整体结构
object queries的初始化
输出层就是100个 object queries 预测
编码器和Vision Transformer一样(减去了cls)
解码器首先随机初始化100个object queries (以0+位置编码进行的初始化的) 相当于就是
用位置编码进行的初始化
直接使用位置编码作为初始化的目的:使得不同的object queries 关注图像的不同区域。
通过多层让其学习如何利用输入特征
Decoder中的Muiti-Head Self-Attention
100个 object queries分别使用q,k,v完成自注意力机制
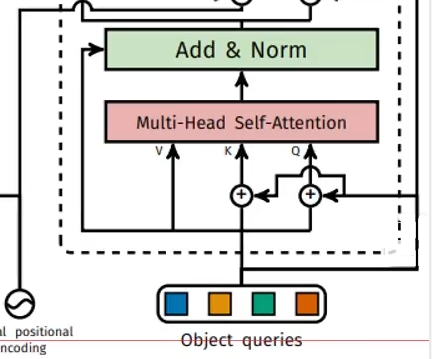
Decoder中的Muiti-Head Attention
由Encoder提供k和v,由Muiti-Head Self-Attention提供q
损失函数
匈牙利匹配
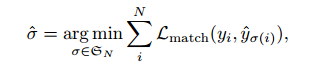

是地面实况 yi 与索引为 σ(i)的预测之间的成对匹配成本。根据之前的工作,匈牙利算法可以高效地计算出这一最优分配
匈牙利匹配:按照最小的loss进行匹配,使得选择的预测框和真实框的loss最小,其余剩下的预测框就是背景
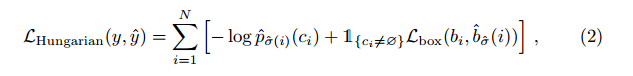

匹配成本既要考虑类别预测,也要考虑预测框和地面实况框的相似性
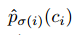
类别概率
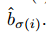
检测框位置

这种寻找匹配的过程与现代检测器中用于将建议[37]或锚点[22]与地面实况对象相匹配的启发式分配规则的作用相同。主要区别在于,我们需要找到一对一的匹配,以实现无重复的直接集合预测。第二步是计算损失函数,即上一步中所有匹配对的匈牙利损失。我们对损失的定义与常见物体检测器的损失类似,即类预测的负对数似然和稍后定义的盒损失的线性组合:
解决的问题
注意力起到的作用:可以识别出遮挡区域


可视化解码器对每个预测对象的注意力(图像来自 COCO val set)。使用 DETR-DC5 模型进行预测。不同物体的注意力分数用不同颜色表示。解码器通常会关注物体的四肢,如腿部和头部。最佳彩色视图