过账:单一分类账运行时间过长
近期业务反馈”增加/删除汇总账户”程序运行时间长达十几个小时,”过账:单一分类账”时间有时候运行时间长达半个小时。主要的原因是近期新增了很多账套和汇总模板,系统会重新收集各个账套汇总模板和明细账户之间的关系。
通过PLSQL的session查看,程序主要卡在一下两个SQL;
第一个耗费时间的SQL
SELECT 2021, 8,
sc.code_combination_id,
dc.code_combination_id,
dc.SEGMENT4,
0, sysdate
FROM
gl_summary_interim_0 si0,
gl_code_combinations sc,
gl_code_combinations dc
WHERE dc.chart_of_accounts_id = 50388
AND dc.template_id IS NULL
AND dc.account_type in ('A','L','O','R','E')
AND (dc.code_combination_id BETWEEN 1504966 AND 1515448)
AND si0.source_flex_value = dc.SEGMENT1
AND sc.chart_of_accounts_id = 50388
AND sc.template_id = 8
AND sc.SEGMENT1 = si0.target_flex_value
AND sc.SEGMENT2 = dc.SEGMENT2
AND sc.SEGMENT3 = 'T'
AND sc.SEGMENT4 = dc.SEGMENT4
AND sc.SEGMENT5 = 'T'
AND sc.SEGMENT6 = dc.SEGMENT6
AND sc.SEGMENT7 = 'T'
AND sc.SEGMENT8 = 'T'
AND sc.SEGMENT9 = 'T'
AND NOT EXISTS
(SELECT 1
FROM gl_account_hierarchies ah2
WHERE ah2.summary_code_combination_id = sc.code_combination_id
AND ah2.detail_code_combination_id = dc.code_combination_id)```
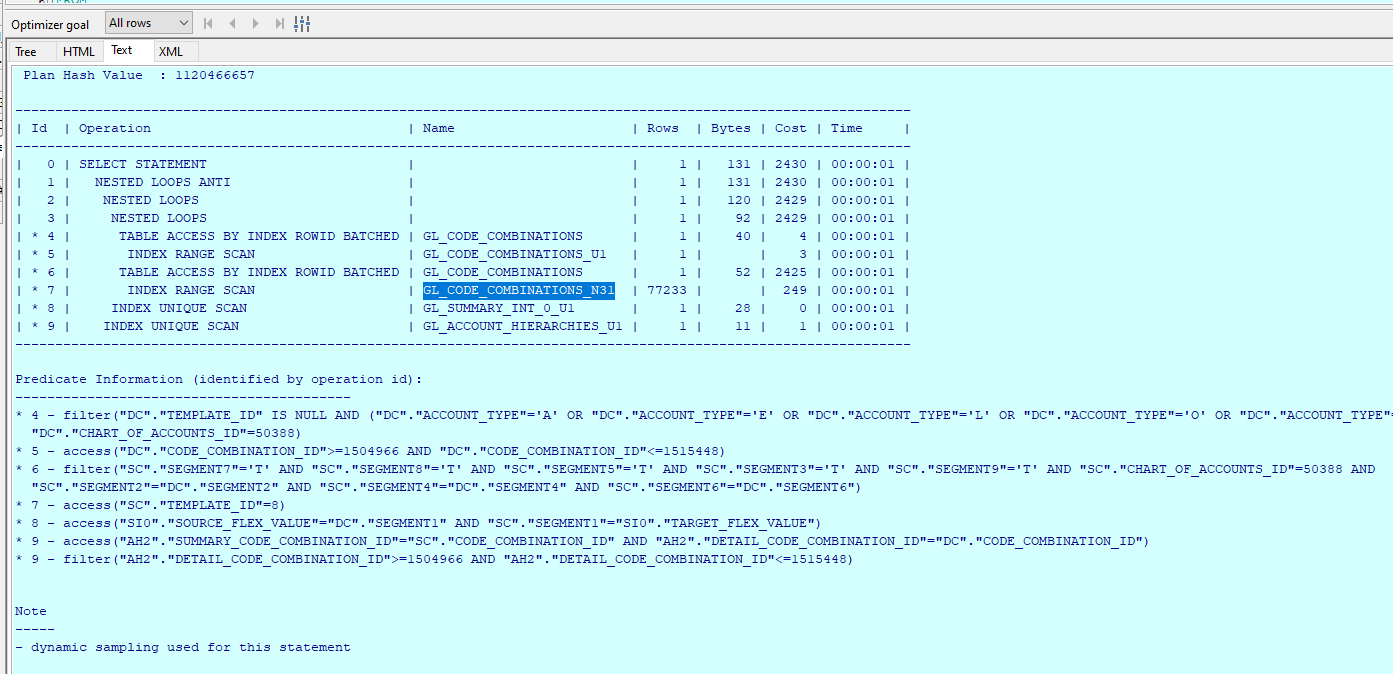
其实EBS系统GL_CODE_COMBINATIONS的索引是比较奇怪了,仅有GL_CODE_COMBINATIONS_U1唯一性索引和GL_CODE_COMBINATIONS_N31关于模板ID的索引。
这里针对上面SQL出现的两个数字1504966、1515448做一下解释,无论是逐级增删模板还是凭证过账,都会对各个汇总模板的账户关系(汇总账户和明细账户)进行归集,1504966是GL_SUMMARY_TEMPLATES表MAX_CODE_COMBINATION_ID的值,它表示已经归集账户的最大值,1515448表示当前GL_CODE_COMBINATIONS最大的CODE_COMBINATION_ID,系统需要归集这个范围之内的账户。注意明细账户是不区分账套的,汇总账户区分账套的。如果系统新增很多维度比较细的汇总账户,很容易在GL_CODE_COMBINATIONS增加大量账户。上面两个数字差会变大,这是影响上面SQL执行一个因素。
当然最主要的因素还是第六步走GL_CODE_COMBINATIONS_N31,这个索引抓去了7W多条数据,系统又花费了大量时间对这7W条数据其他条件过滤。
结论有两点:
汇总模板的增加会大量增加GL_CODE_COMBINATIONS数据条数,汇总维度越细加的越多。
现有的GL_CODE_COMBINATIONS仅有两个索引,不合理,需要增加合适的索引。
第二个会耗费时间的SQL:
UPDATE gl_temporary_combinations tc1
SET tc1.code_combination_id =
(select nvl(cc.code_combination_id, -1)
from gl_code_combinations cc, gl_temporary_combinations tc2
where (cc.template_id(+) + 0) = :out_template_id
and tc2.chart_of_accounts_id = cc.chart_of_accounts_id(+)
and tc2.SEGMENT1 = cc.SEGMENT1(+)
and tc2.SEGMENT2 = cc.SEGMENT2(+)
and tc2.SEGMENT3 = cc.SEGMENT3(+)
and tc2.SEGMENT4 = cc.SEGMENT4(+)
and tc2.SEGMENT5 = cc.SEGMENT5(+)
and tc2.SEGMENT6 = cc.SEGMENT6(+)
and tc2.SEGMENT7 = cc.SEGMENT7(+)
and tc2.SEGMENT8 = cc.SEGMENT8(+)
and tc2.SEGMENT9 = cc.SEGMENT9(+)
and tc2.rowid = tc1.rowid)
where request_id = :req_id
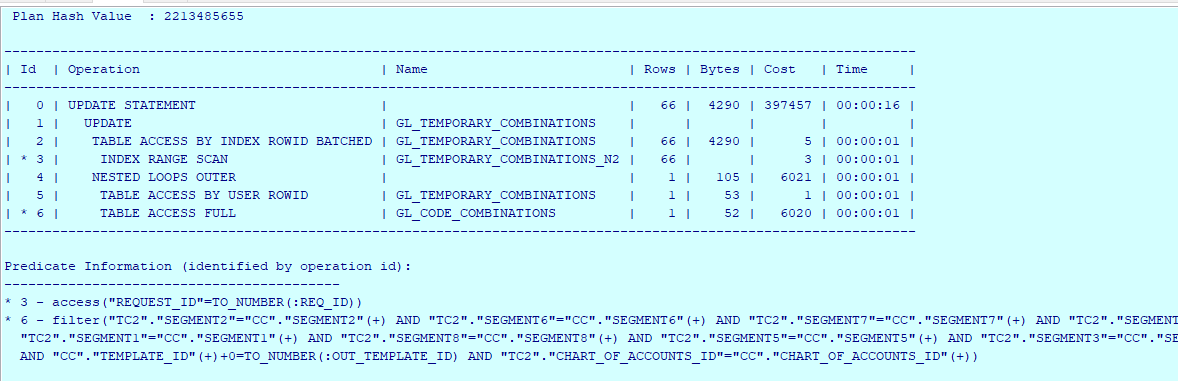
这个SQL执行路径就有点过分了,对GL_CODE_COMBINATIONS全表扫描,然后在按字段过滤。耗费了大量的时间。
在metlink上参考Doc 858725.1,对GL_CODE_COMBINATIONS增加合适的索引,过程如下:
DECLARE
v_SegNum VARCHAR2(9);
v_FreqCount NUMBER;
BEGIN
FOR i IN 1..30
LOOP
EXECUTE IMMEDIATE
'SELECT COUNT(DISTINCT SEGMENT'||TO_CHAR(i)||')
FROM gl_code_combinations'
INTO v_FreqCount ;
IF v_freqCount <> 0 THEN
DBMS_OUTPUT.PUT_LINE(
'SEGMENT'||TO_CHAR(i)||' Frequency = '||TO_CHAR(v_FreqCount));
END IF;
END LOOP;
END;
查询结果假如如下:
SEGMENT1 Frequency = 4
SEGMENT2 Frequency = 37
SEGMENT3 Frequency = 76
SEGMENT4 Frequency = 3221
SEGMENT5 Frequency = 21
SEGMENT6 Frequency = 22
从细到粗建组合索引:
CREATE INDEX GL_CODE_COMBINATIONS_CAT ON gl_code_combinations
(segment4,
segment3,
segment2,
segment6,
segment5,
segment1)
PCTFREE 0
INITRANS 2
MAXTRANS 255
TABLESPACE user_index
STORAGE (INITIAL 1048576
NEXT 16384
PCTINCREASE 0
MINEXTENTS 1
MAXEXTENTS 20);
按照上诉步骤执行后,执行统计数据收集表请求或执行以下SQL收集表:
BEGIN
fnd_stats.gather_table_stats('GL'
,'GL_CODE_COMBINATIONS'
,dbms_stats.auto_sample_size);
END;
增加/删除汇总账户原本运行时间十几个小时,限制只需要运行40s;查看第二个SQL执行计划如下图,发现耗费时间巨大缩短:
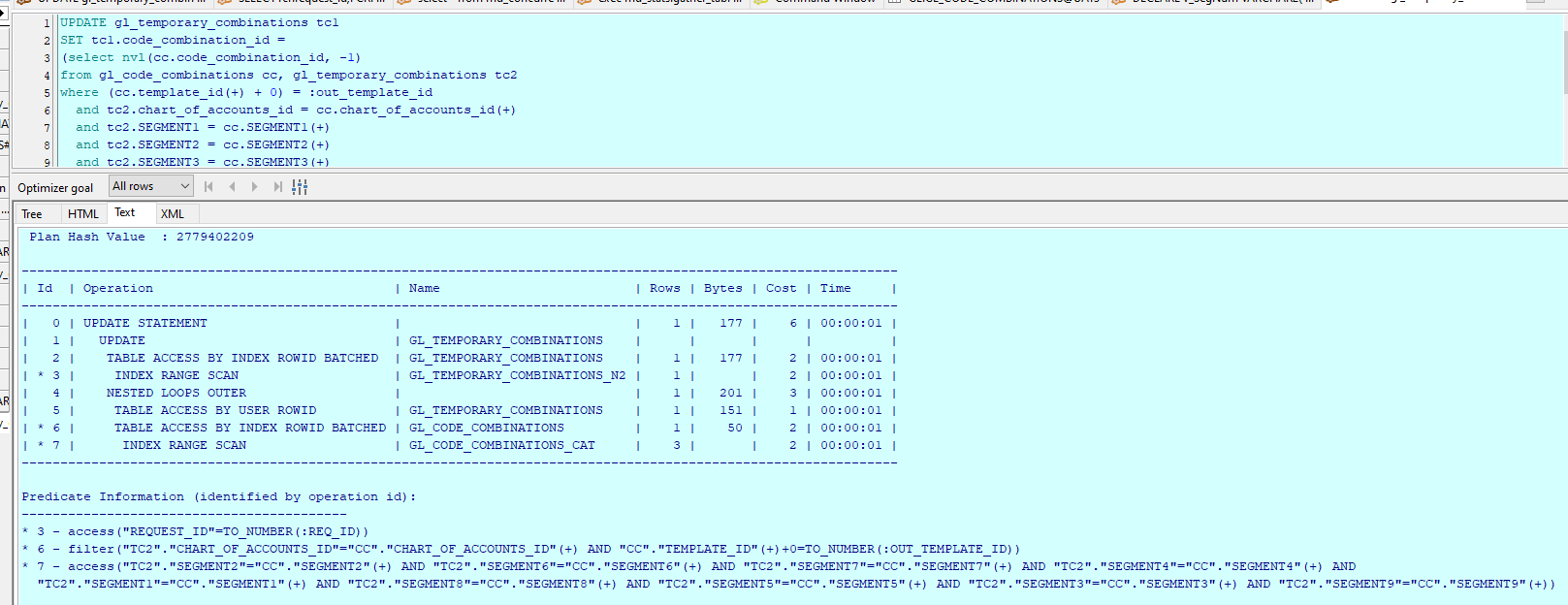
其实最后发现解决问题的办法很简单,只是增加了一个索引哈。但个人觉得处理问题的思路还是可以借鉴一下。