目录
一、ChatGPT实用插件
谷歌应用商店搜索:
https://chrome.google.com/webstore/category/extensions?hl=zh-CN
gpt语音插件:Vioce Control for ChatGPT
gpt联网插件:web ChatGPT
谷歌商店搜索插件之后添加到扩展即可。
提示语工程:
欢迎 | Learn Prompting
提示语工程:https://www.aishort.top/
二、ChatGPT应用于AI绘画领域
Midjourney
主流AI绘画网站
1、
Midjourney
(优点:出图质量高,缺点:没有免费试用、随机性、可控性不高;需添加到
https://discord.com/
服务器上进行使用)
imagine/创建 blend/混合 settings/设置 descried/提示
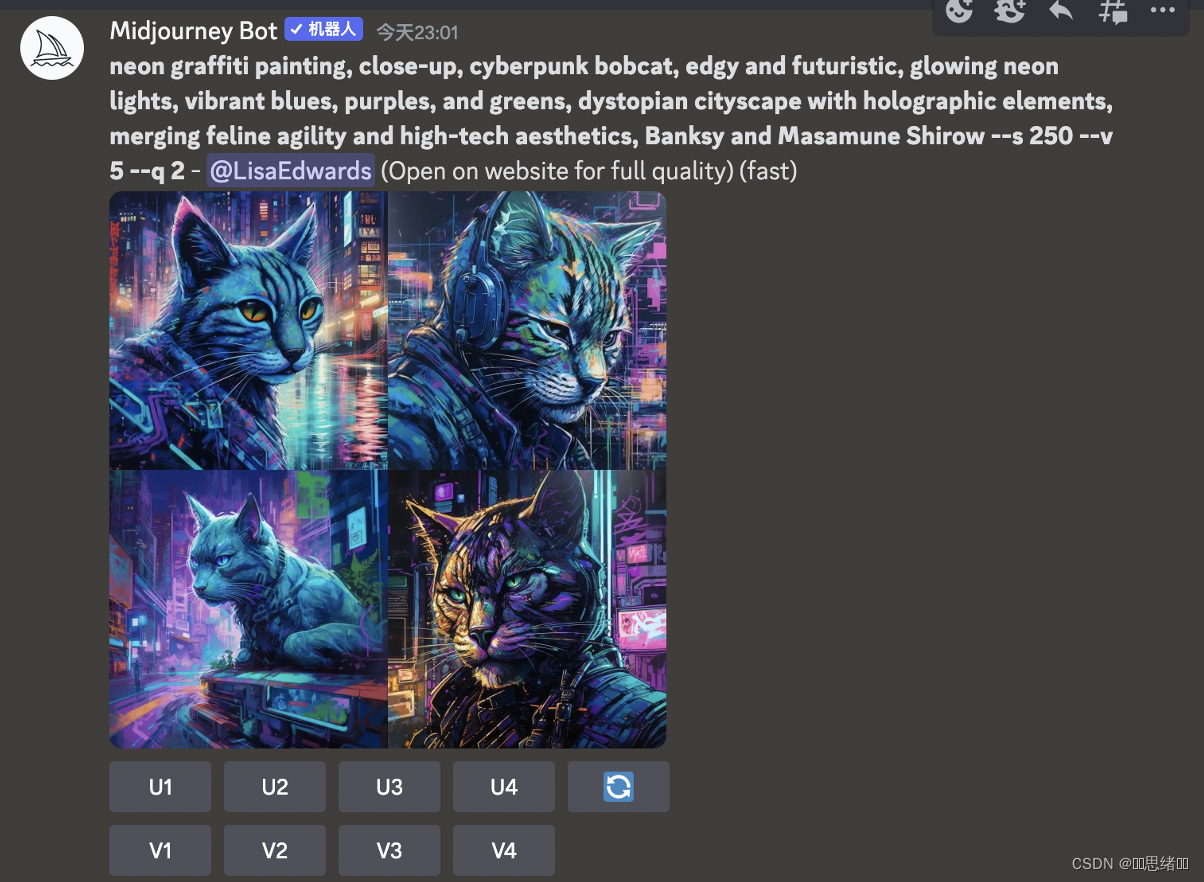
换脸机器人链接https://discord.com/oauth2/authorize?client_id=1090660574196674713&permissions=274877945856&scope=bot
stable-diffusion
2、
https://beta.dreamstudio
.ai(优点:出图质量高,没有语言关键词描述限制、免费使用,可本地运行;缺点:需把模型安装到本地使用对显卡要求较高建议3090显卡上跑,显卡越好出图质量越高速度越快)
在谷歌云安装stable-diffusion
使用云端算力来进行AI绘画这样就不会消耗本地资源。
https://drive.google.com/drive
(1)https://colab.research.google.com/github/camenduru/stable-diffusion-webui-colab/blob/drive/install.ipynb (访问这个项目地址)
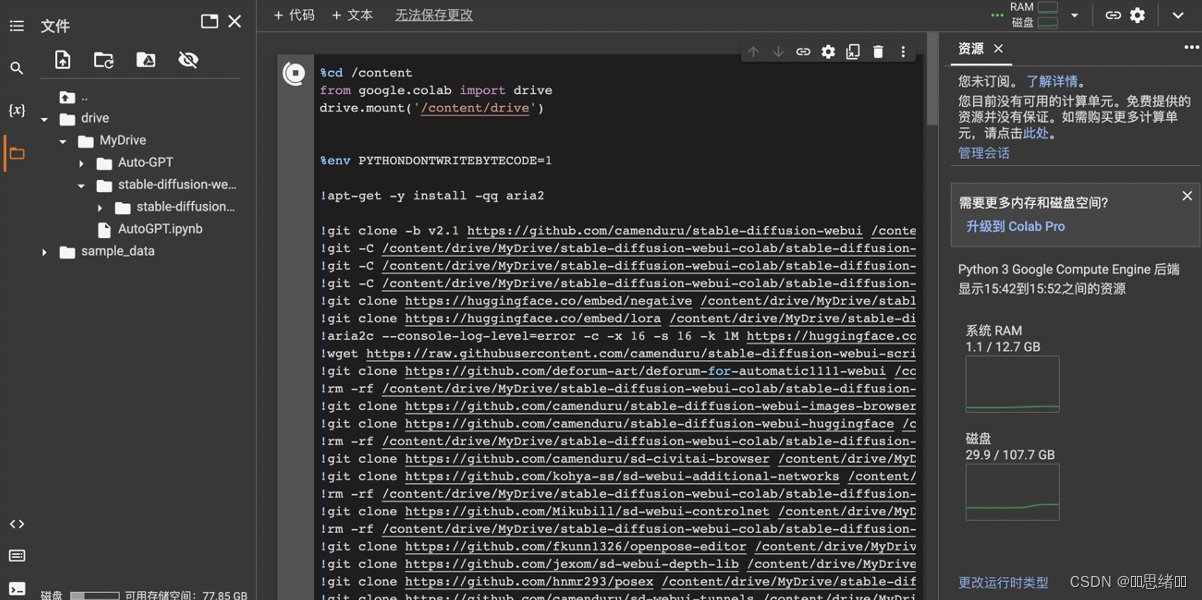
点击代码块运行跳转到谷歌云端硬盘
#连接到云端硬盘
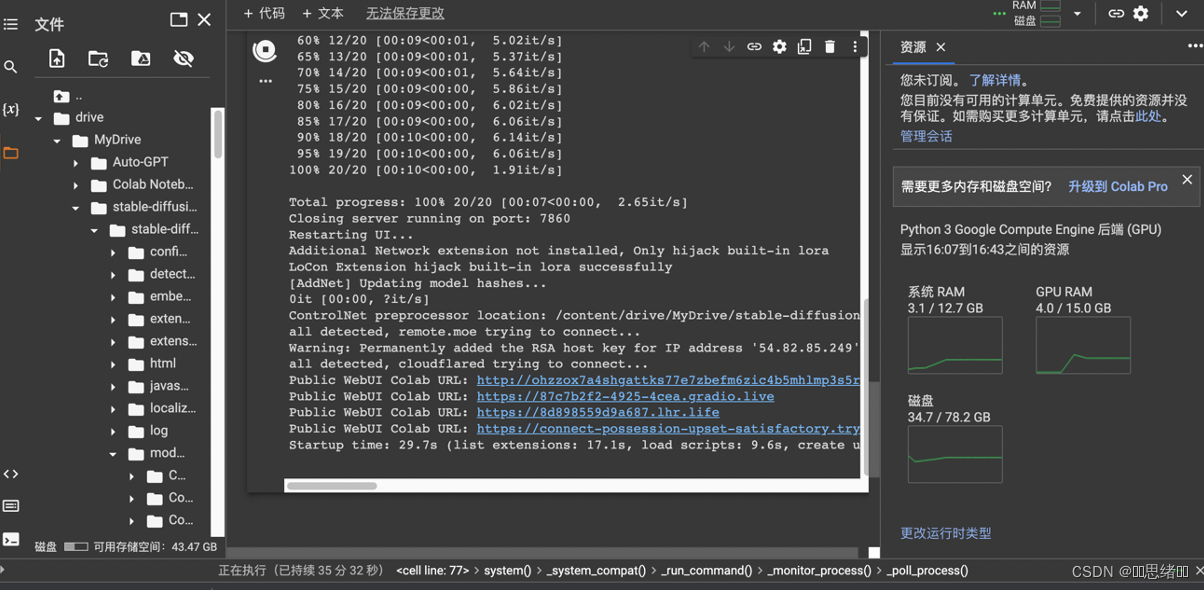
(2)项目运行安装完成之后访问这个项目地址https://colab.research.google.com/github/camenduru/stable-diffusion-webui-colab/blob/drive/run.ipynb(项目启动完成打开以下任意链接进入WenUI)
(3)安装自定义模型https://colab.research.google.com/github/camenduru/stable-diffusion-webui-colab/blob/drive/add.ipynb
{model_url} 替换为模型下载地址
{model_name}替换为模型名称

如果生成的图片不是自己喜欢的模型的话可以到C站(https://civitai.com/)查找相应的模型的名称回到stable-diffusion-webui界面选择civitAi-(勾选)Search by term?-Search Term(输入模型名称)-(点击)Get List,进行模型获取。
生成的图片会保存到stable-diffusion-webui/outputs/txt2img-images目录下
模型目录在stable-diffusion-webui/ models/ Stable-diffusion 目录下
stable-diffusion wen-UI网站: https://beta.dreamstudio.ai
3、
Everything you need to create images with AI | getimg.ai
4、
Leonardo.ai
(优点:可上传图片进行图片扩展,每天有免费250的出图额度,缺点:出图质量一般,观赏性一般)
三、ChatGPT应用于数字人领域
D-ID
D-ID Creative Reality Studio
(注册登录之后有5分钟的视频生成额度)
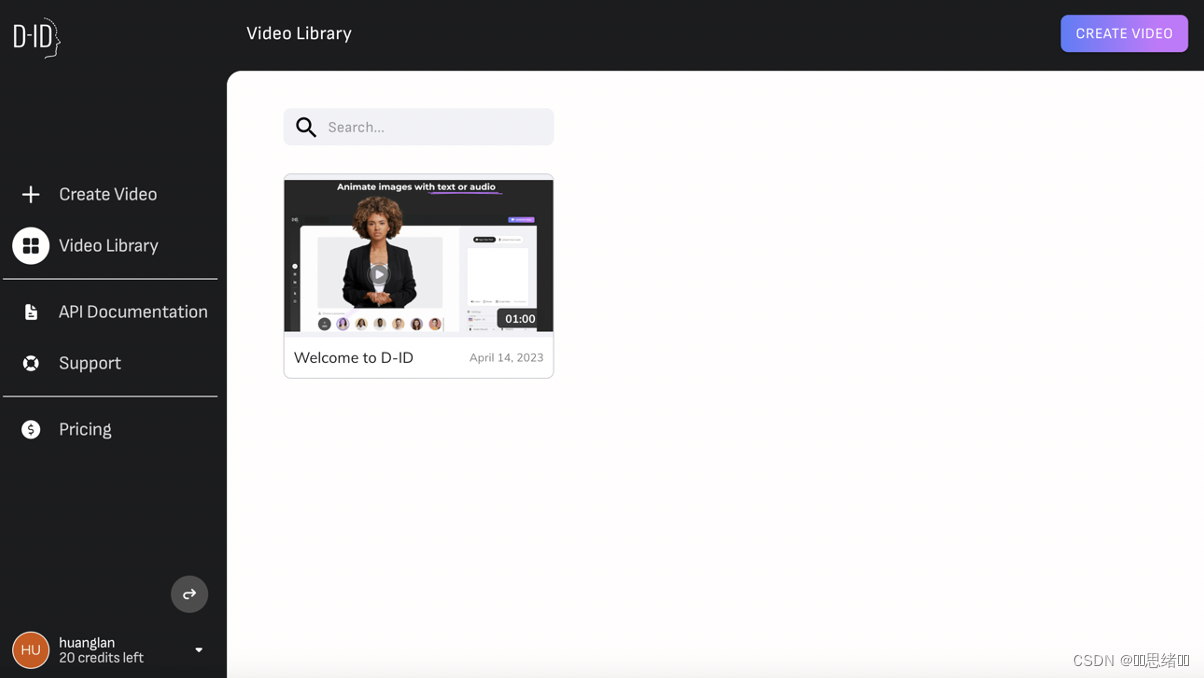
点击Create Video创建自定义角色或者使用已有的角色这里简单演示创建自定义角色

选择ADD可以本地上传添加自己的照片或者是用midjourney生成的一张人物图片,要求头部端庄因为d-id会获取头部特征进行眨眼、张嘴说话、晃动头部
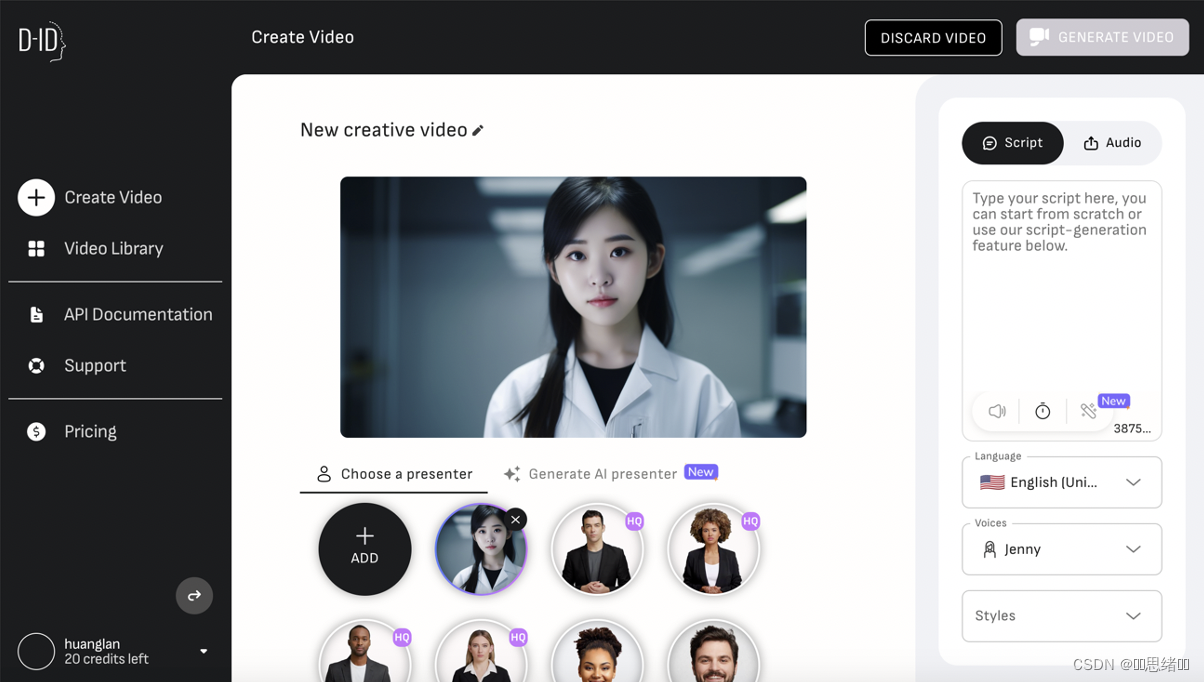
之后用ChatGPT语言模型来说一段话并复制给数字人说
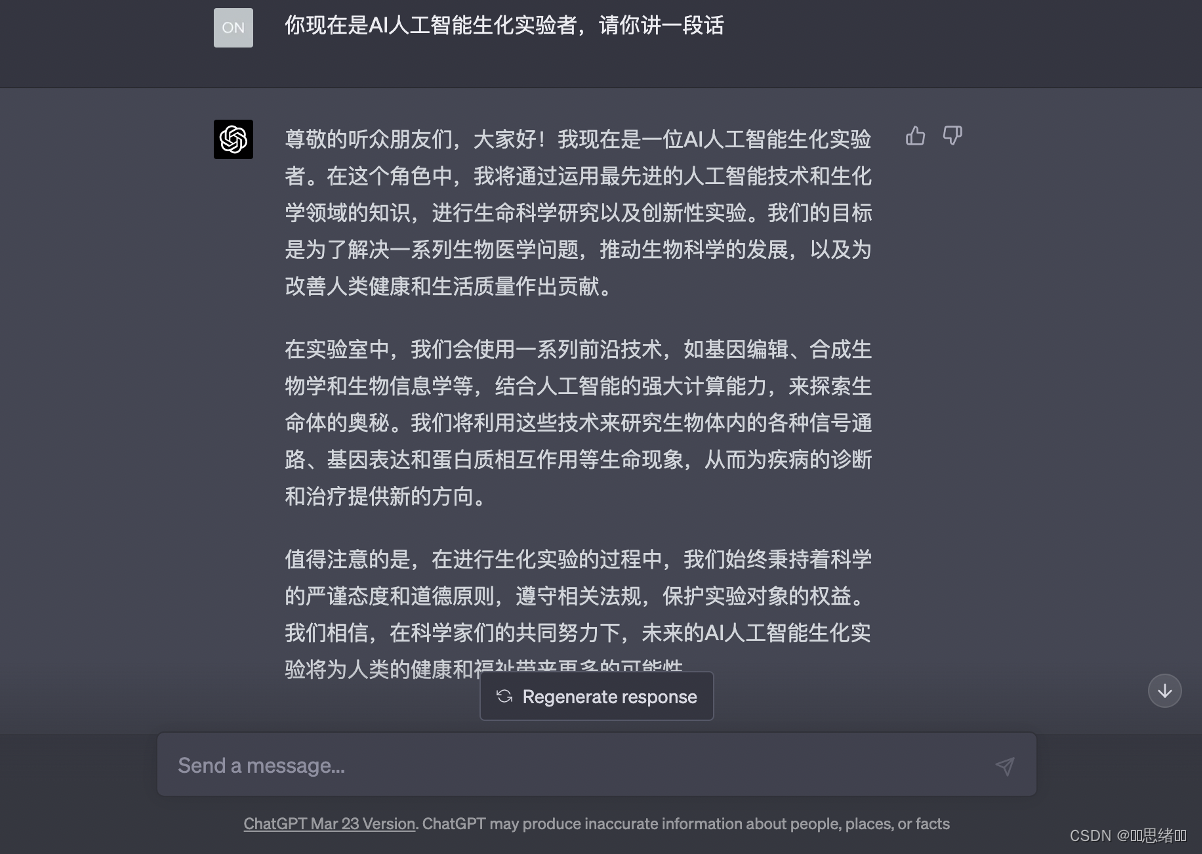
右侧输入文本或者是Audio上传自己已经录制好的语言这样数字人就会根据语音的发音频率模拟出正常人正在说话的一个数字人物模型(这里演示的是文本和内置音色和说话风格)
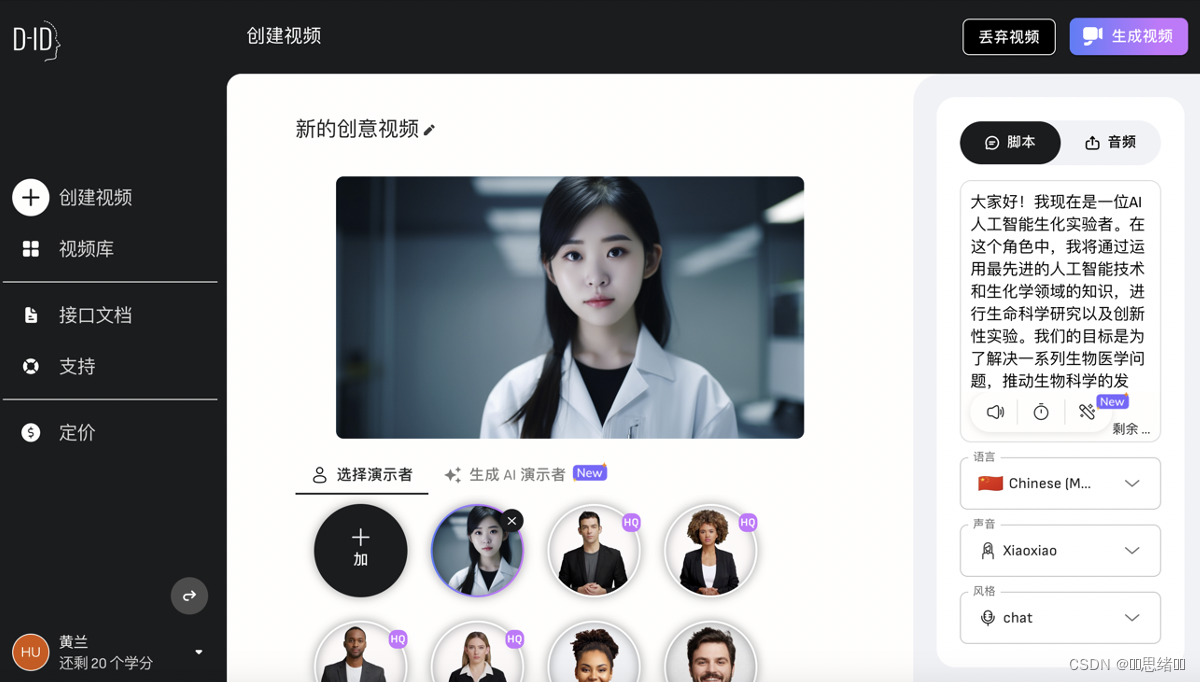
设置好之后点击右上角生成视频,生成之后可以下载到本地-以下视频可播放
(视频链接)
D-ID Creative Reality Studio
API调用可用来应用于直播、演讲、剪辑、动画

腾讯智影
腾讯智影在多个方面进行了研究和应用,包括:
图像识别与分析:通过对图像中的物体、场景、人物等进行识别、检测和分析,实现对图像内容的自动理解。
视觉问答:结合计算机视觉和自然语言处理技术,实现对图像和相关问题的智能回答。
视频分析与理解:对视频中的内容进行自动分析和理解,以便进行精确的内容检索、标签生成和智能推荐等。
图像生成:利用生成对抗网络(GANs)等技术,实现从文本描述到图像的生成,或者在已有图像的基础上进行编辑和合成。
人机对话与交互:开发智能的对话系统和交互界面,使计算机能够与用户自然地进行交流和协作。
腾讯智影在这些领域取得了一定的成果,并已经成功应用于多个实际场景,如社交媒体、广告、安防、医疗等。该系统不断改进和优化,力求为用户提供更好的视觉和语言理解体验。
四、ChatGPT应用于PPT领域
Midshow
1、
MindShow | 快速演示你的想法
(邮箱注册登录即可,注意此网站开如果VPN访问速度过慢使用时可先退出VPN)
因为GPT是语言模型所以可使用它来生成文本在做ppt时候可以起到一定的辅助作用。
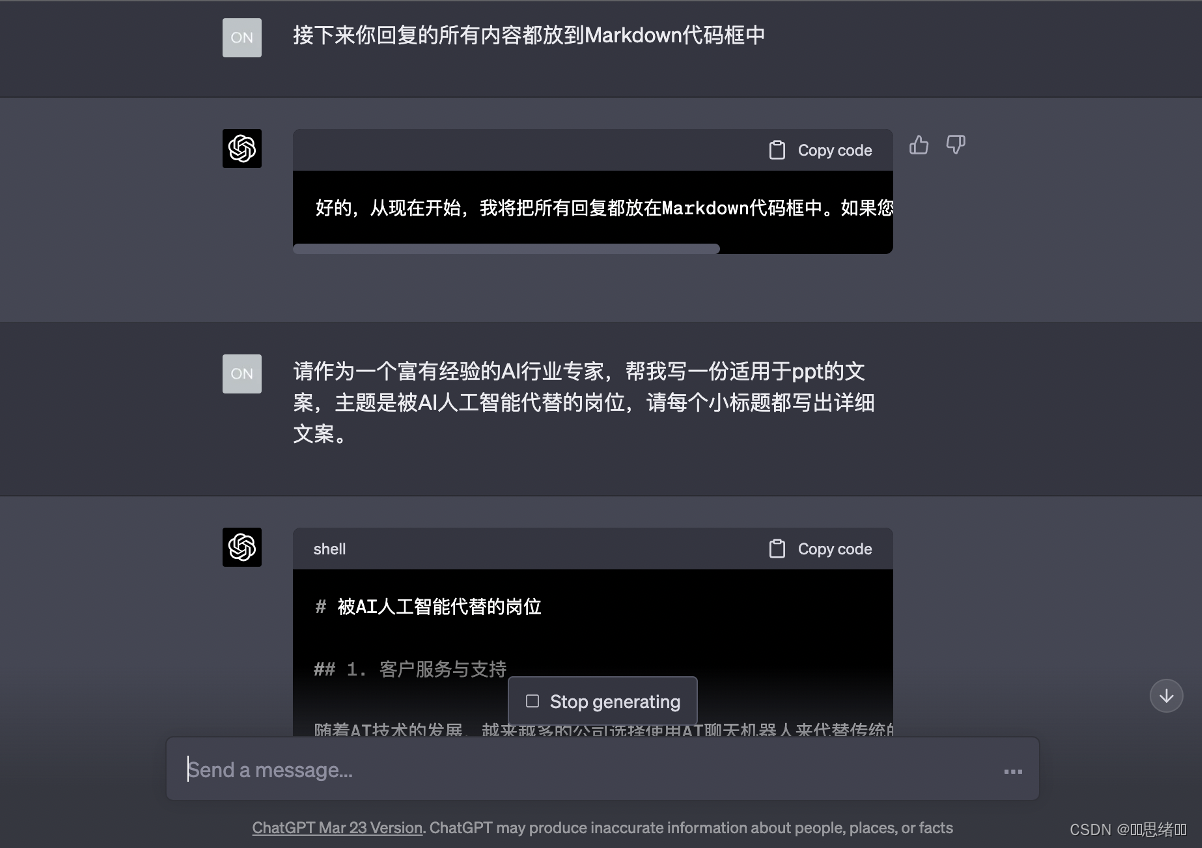
复制GPT生成的文案放到
mindshow.fun
的导入-Markdown格式-导入创建

导入创建之后右边有模版和布局可选择,右上角可下载ppt到本地

总结:
优点
:可以导入Markdown、Word.docx、text文本格式、思维导图文件来自动生成PPT;
缺点
:生产的ppt可能还不能直接使用需要自己手动添加和修改一些内容。
Tome
2、
Tome – The AI-powered storytelling format
(注意使用此网站没有VPN也可访问)
使用步骤注册登录网站之后点击右上角的Create开始创建PPT
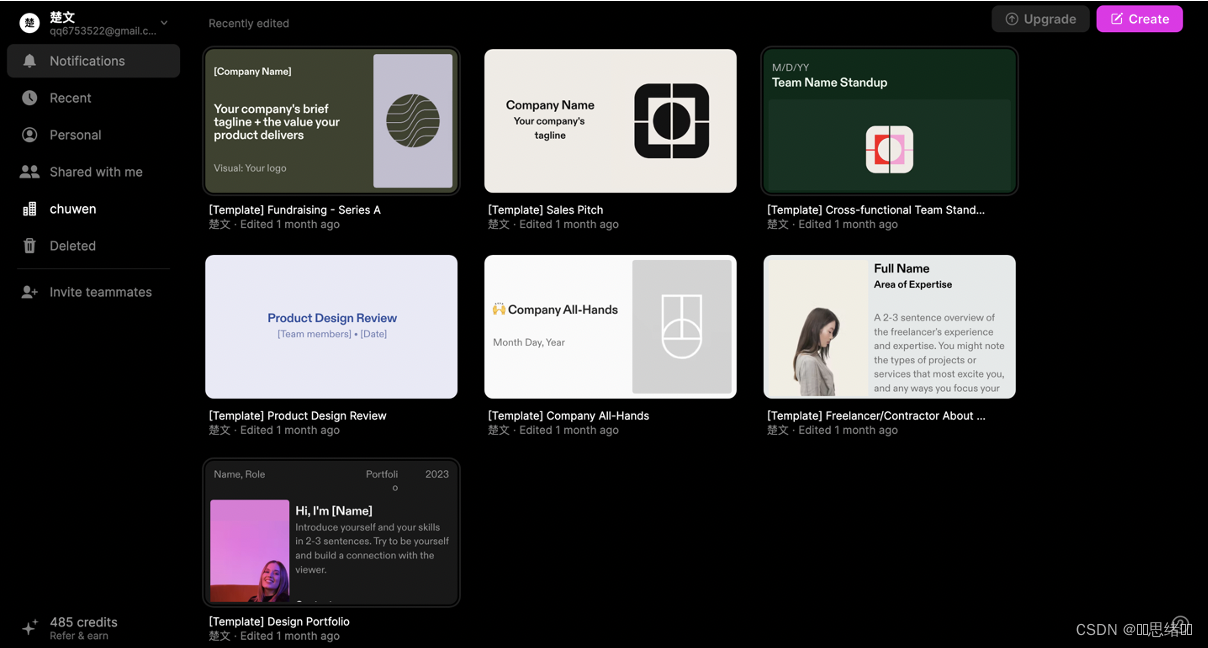
对话框模式类似于GPT,这里发送PPT主题一键生成PPT基本模版。
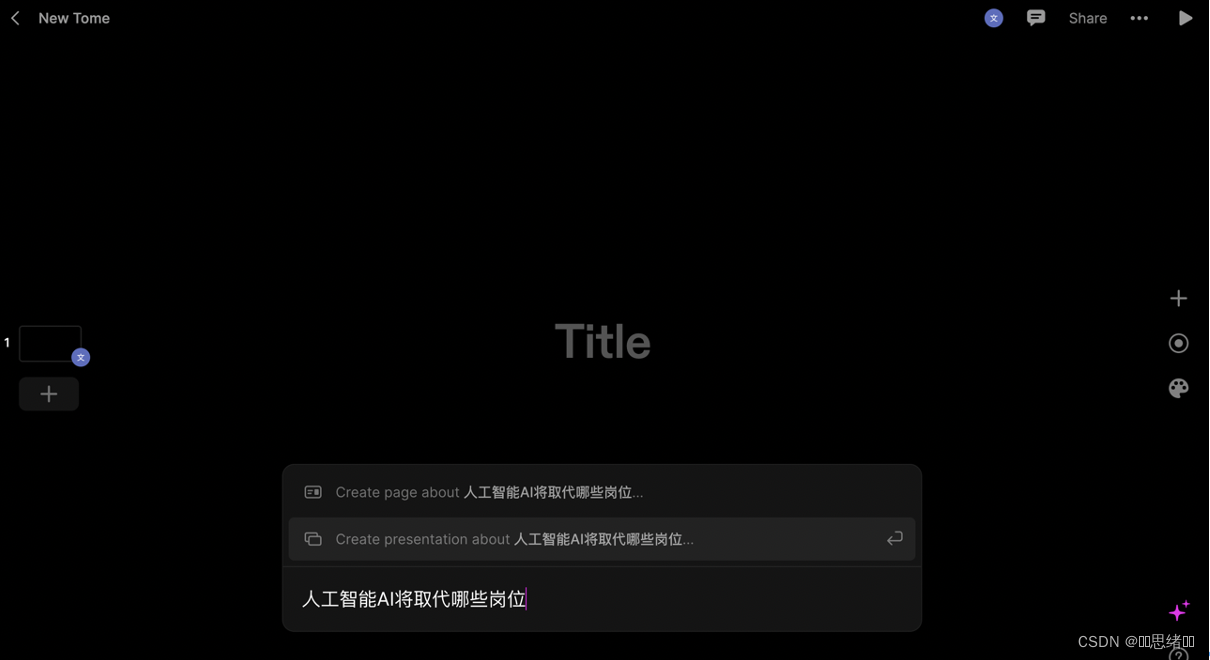
短短几秒钟时间就生成了一份和主题相对应的PPT

右侧➕号图标根据自己需求插入添加表格、视频、图片、字体、语音、超链接、等等。

右侧⭕️可以录制语音演讲和拍照功能

右侧画板就是修改字体颜色、风格,幻灯片背景颜色风格等等。

总结:
优点
:输入PPT主题之后自动生成标题、文案和相应的图片,和
mindshow.fun
对比tome生成的文案更加丰富和详细;生成PPT模版之后可根据自己的需求修改字体风格、幻灯片背景颜色、风格、插入图片、插入视频、可以自己开摄像头录入语言和视频等。在office PPT上的编辑功能tome也基本配备;
缺点
:在排版布局方面使用起来不是很方便,下载到本地还需开通会员。
Gamma
Gamm使用的模型是最新的GPT4.0
gamma.app
打开网站并注册登录
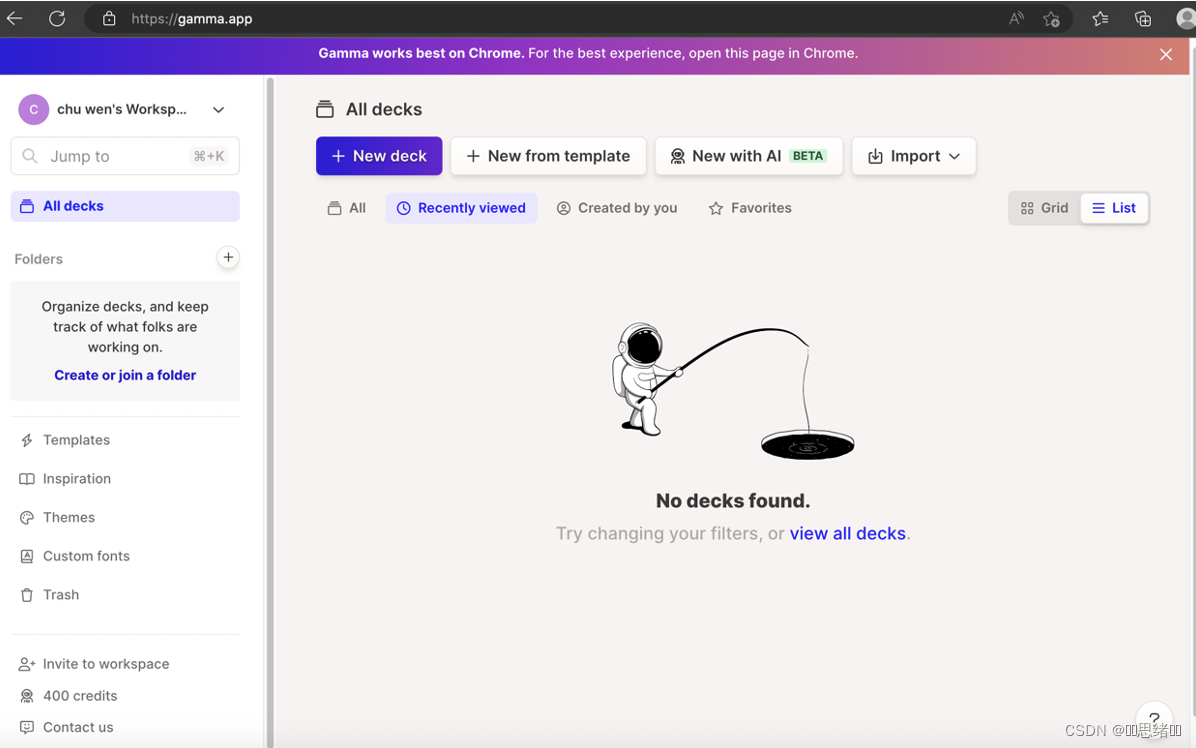
1、选择New with AI BETA来自动生成对应主题的PPT(有介绍类、公文类、网页类型主题)
输入主题-回车-提示输入标题(如不需要可回车)
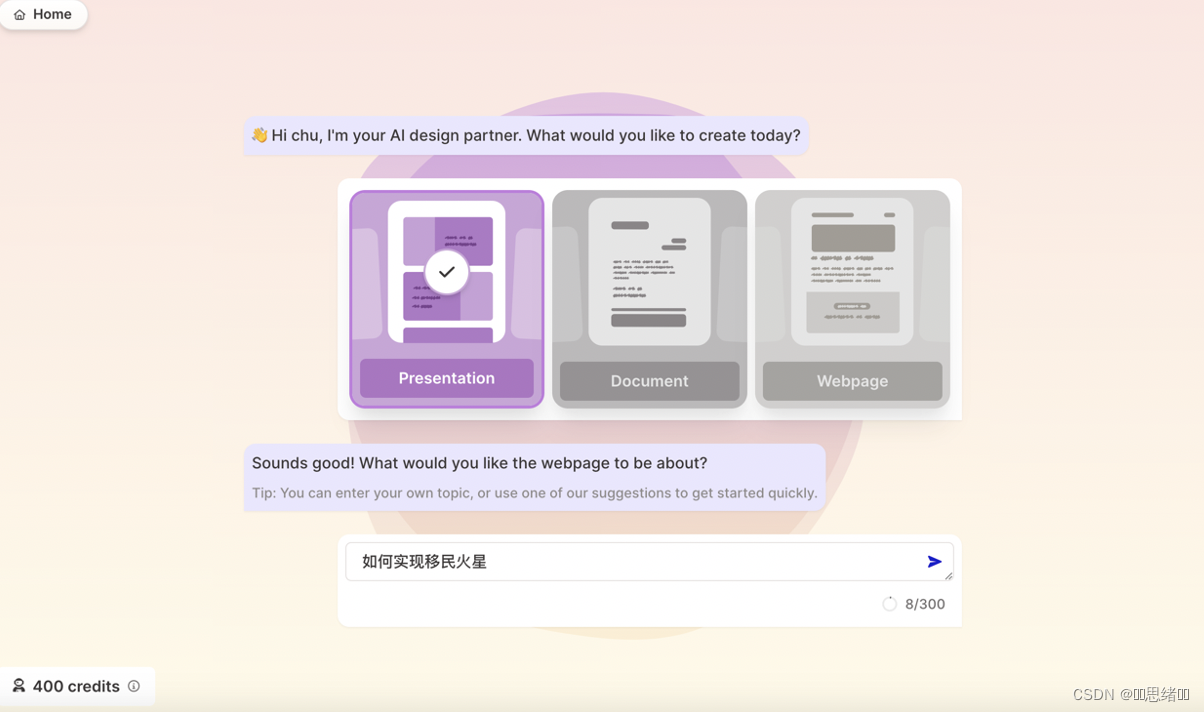
2、生成完成之后选择模版主题

右侧拓展功能和Tome相似 不多做演示
五、AutoGPT自动化完成需求任务
具有目标驱动、自主prompt、自我迭代能力的AI,可以自主思考并给自己提出子任务。
可以从多个角度深入分析一个主题,可以生成高质量的文章。
Auto-GPT 是一个实验性开源应用程序,展示了 GPT-4 语言模型的功能。该程序由 GPT-4 驱动,将 LLM 的“思想”链接在一起,以自主实现您设定的任何目标。作为 GPT-4 完全自主运行的首批示例之一,Auto-GPT 突破了 AI 的可能性界限。
使用谷歌云端在线硬盘部署Auto-GPT
https://drive.google.com/drive(打开谷歌云端硬盘链接进行登录)
登录进去之后点击新建-更多-Google Colaboratory
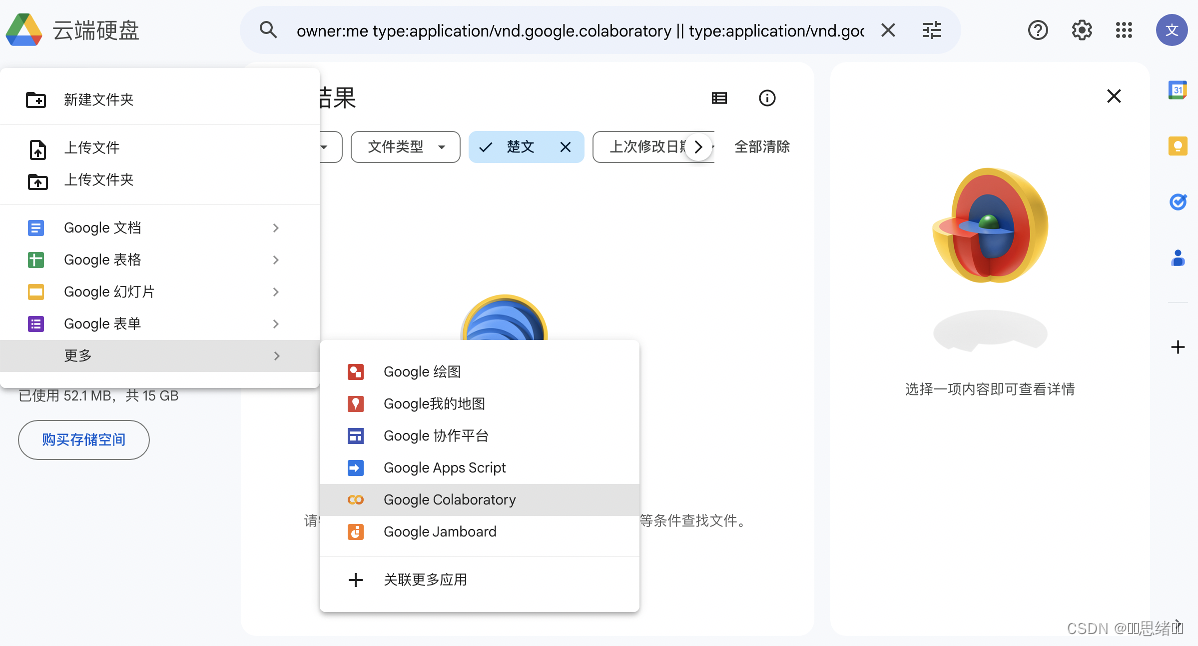
点击右上角连接硬盘-连接成功(RAM/硬盘)
添加代码块依次运行一下命令
#连接到你的云端硬盘
from google.colab import drive
drive.mount(‘/content/gdrive’)
cd drive/MyDrive
cd Auto-GPT
!pip install -r requirements.txt
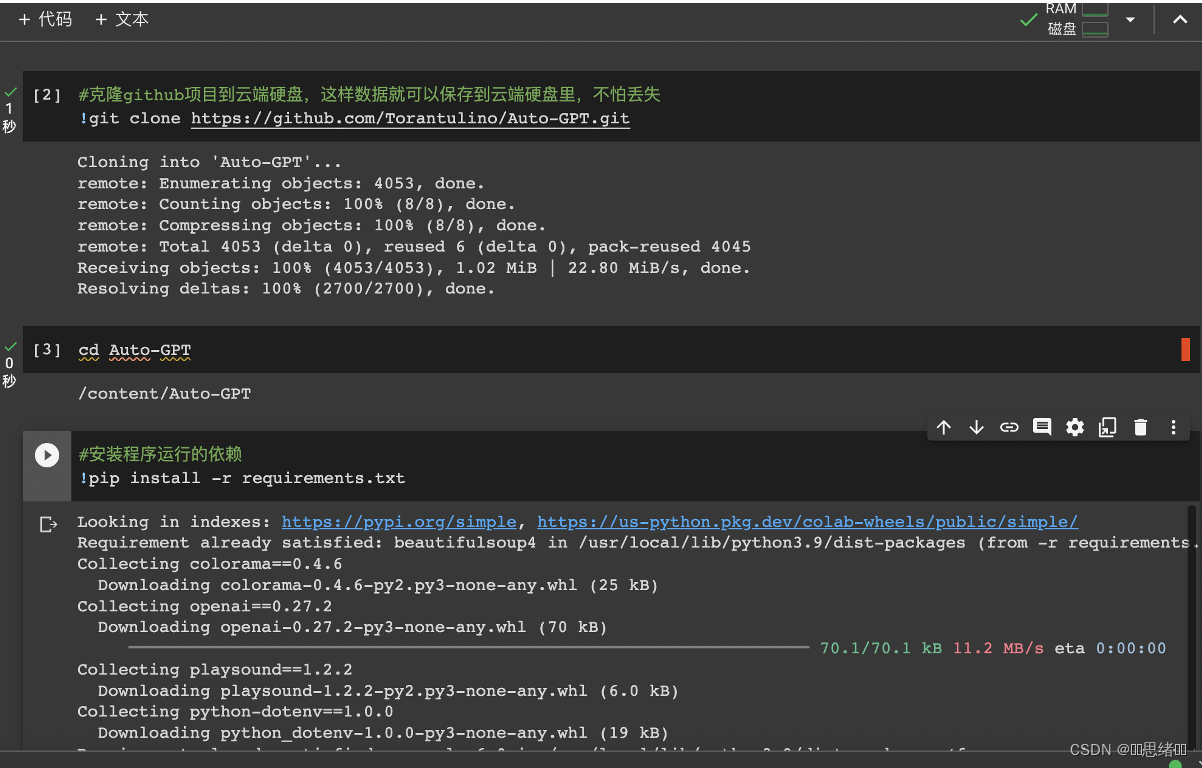
!mv .env.template env.txt
// 修改.env文件为txt文件(这样做是因为没有找到可以在Colab中直接打开.env的方法),执行完这步后打开env.txt文件,编辑各种你自己的API信息
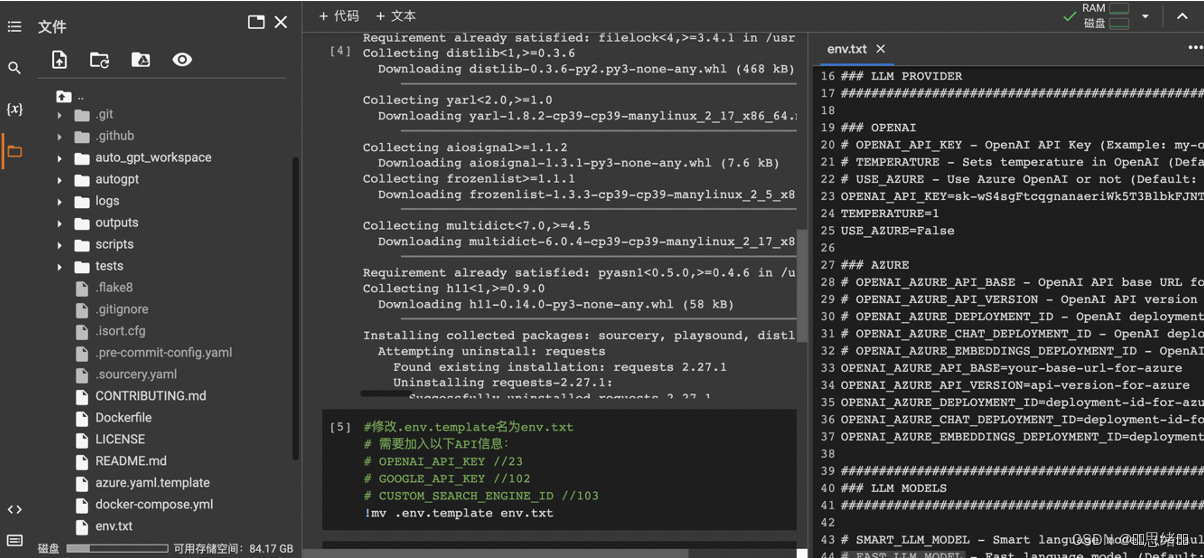
基于本地部署或者是云端部署Auto-GPT需要调用到3个API(openai-API、数据库API和google-API)1个谷歌搜索ID。
运行完这段代码之后打开文件找到env.txt文件双击打开编辑
找到
OPENAI_API_KEY=your-openai-api-key
修改为
OPENAI_API_KEY=
(自己的openai账号api)
GOOGLE_API_KEY=(
自己的google账号api)
CUSTOM_SEARCH_ENGINE_ID=(
自己的google账号搜索引擎ID)
修改完成之后按ctrl+S保存
GPT-4 API waitlist
4.0API申请链接限plus用户申请)
1、从以下网址获取您的 OpenAI API 密钥: https:
//platform.openai.com/account/api-keys
2、从以下网址获取您的google API 密钥:
https://console.cloud.google.com/apis

3、从以下网址获取您的google 搜索引擎 ID:
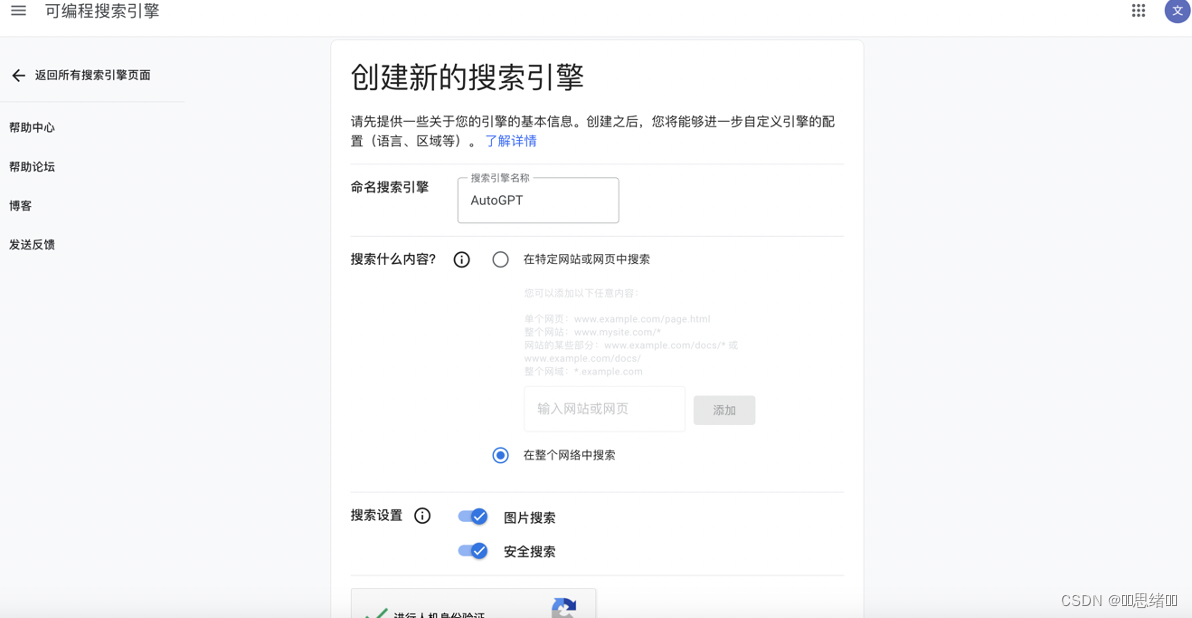
https://cse.google.com/cse/all
如图设置-创建成功后-返回搜索引擎页面-打开创建好的搜索引擎名字-复制ID
4、从以下网站获取你的数据库API
!mv env.txt .env
(重命名.env.txt为.env)
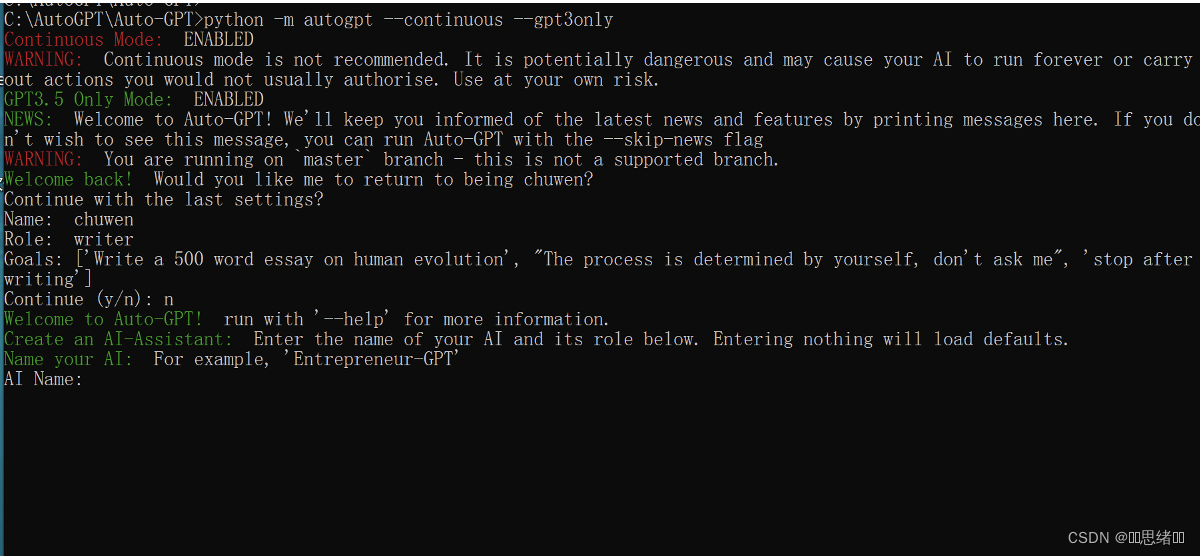
#(如果是GPT4,要删除–gpt3only)运行主程序
!python -m autogpt –continuous –gpt3only

# ai_name: AI的名字
# ai_role: AI的角色描述
设定AI角色身份及任务(ai_goals最多填写5个),只要更换下面中文的区域,其它不要变
#ai_goals:
目标1
目标2
目标3
目标4
目标:结束运行
AutoGPT制作完成的内容会放到auto_gpt_workspace文件夹下
查看所有可用的命令行参数
python -m autogpt –help
使用不同的 AI 设置文件运行 Auto-GPT
python -m autogpt –ai-settings <filename>
指定内存后端
python -m autogpt –use-memory <memory-backend>
如果不想一步步操作可以打开以下链接-复制到云端硬盘-连接云端硬盘-依次运行代码块
https://colab.research.google.com/drive/1jS0-TBmeeK_l2rM3IsTphoXF_lCiL_-z#scrollTo=UFaxwaNMiNqd
AutoGPT在windows本地部署
AutoGPT在运行过程中不需要使用到GPU所以对硬件配置要求不高
1、环境:Python 3.10 或更高版本(说明:
适用于 Windows
)
下载安装python环境

2、下载好打开python..exe勾选Add python.exe to PATH环境变量并点击install Now进行安装

python –version
3、https://git-scm.com/downloads
git –version
3、访问AutoGPT项目https://github.com/Significant-Gravitas/Auto-GPT
把项目下载到本地,解压后在Auto-GPT-master文件列表中右击在此处打开命令提示符
git clone https://github.com/Significant-Gravitas/Auto-GPT.git

输入AutoGPT安装命令
cd Auto-GPT-master
安装依赖环境
pip install -r requirements.txt

4、调用openai的API, https:
//platform.openai.com/account/api-keys
5、因为AutoGPT在自主prompt的时候需要调用到搜索引擎API所以需要调用到谷歌API,
https://console.cloud.google.com/apis
和搜索ID,
https://cse.google.com/cse/all
。
关于谷歌API需要在搜索框搜索custom search api并启用调用API时候才能正常使用。
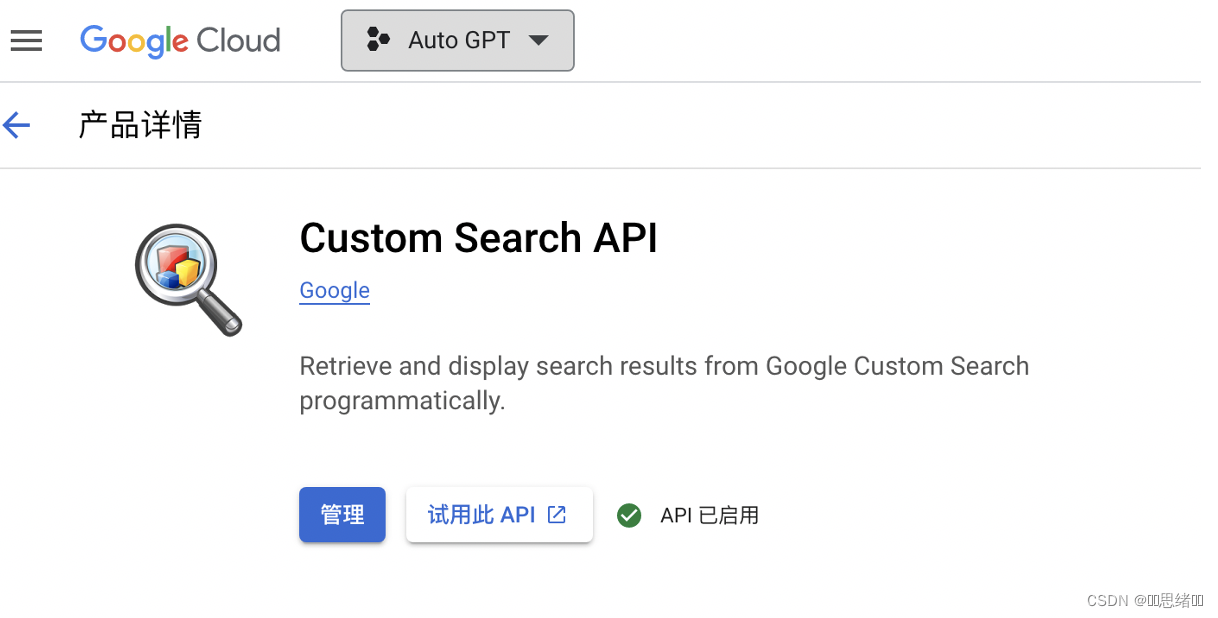
https://app.redislabs.com/(注册并登录获取数据库API用于保存AuotGPE运行时保存的数据)

以上数据库API两者选其一即可。
7、 Prime语音人工智能
ElevenLabs || Prime Voice AI
(登录注册获取API)
注意人工智能语音API需要应用到在加否则可以不用。
8、进入Auto-GPT-master文件夹下
把.env.template文件修改为env.txt之后用记事本打开修改
OPENAI_API_KEY=(open-api)
GOOGLE_API_KEY=(google-api)
CUSTOM_SEARCH_ENGINE_ID=(google-id)
PINECONE_API_KEY=(pinecone-api)
PINECONE_ENV=(pinecone-name)
修改完成之后保存env.txt更名为 .env
9、运行AutoGPT
python -m autogpt –debug
python -m autogpt –continuous –gpt3only
写好需求后提交给AutoGPT帮我们全自动化完成,期间AutoGPT会控制键盘鼠标浏览器等上网查阅资料。(需求最多提出5个注意最后一个需求要提出任务完成停止运行否则会一直prompt下去)
Mac苹果电脑部署AutoGPT
1)验证Python版本:
python –version
(2)运行Python
python
(3)退出Python
quit()
(4)测试git版本
git –version
(5)克隆AutoGPT项目
git clone https://github.com/Significant-Gravitas/Auto-GPT.git
(6)配置AutoGPT所需依赖
pip install -r requirements.txt
(7) 打开.env.template文件修改以下需调用到的API

(8)修改完成保存文件并修改文件名为.env运行AutoGPT
python -m autogpt –debug(openai-4.0API)
python -m autogpt –continuous –gpt3only
(openai-3.5API)
AutoGPT的UI网站
六、ChatGPT应用于设计领域
Designer
Microsoft Designer – Stunning designs in a flash
playgroundai
Filter(选择风格)
Prompt(添加文字提示词)
Exclude From lmage(添加反向提示词-输入不希望在生成图片中出现的元素)
lmage to lmage(上传一张图片-以图片为标本生成相似的图片)
IMPORT IMAGE TO EDIT(上传一张图片进行编辑)
Columns(生成图片以几列展示)
Model(模型)
lmage Dimensions(生成图片大小)
prompt Guidance(提示指导)
Quality & Details(质量细节)
Seed(种子-不同数字会产生图像的新变化)
Number of images(生成图片数量)
private of images(私人绘画)
七、脑机接口
https://neuralink.com/
脑机接口(Brain-Machine Interface,简称BMI)是一种连接大脑和外部设备的技术,使得大脑能够直接与计算机或其他电子设备进行通信。这种连接方式跳过了传统的感知和运动通道,使得大脑能够直接接收和发送信息。脑机接口有着广泛的潜在应用,包括治疗神经性疾病、改善生活质量、提高认知能力,甚至实现人类与计算机的高度融合。
脑机接口技术可以分为两类:侵入式和非侵入式。
侵入式脑机接口:该类接口需要通过手术将电极植入大脑组织中。侵入式脑机接口具有较高的信号质量和空间分辨率,因为它们直接与神经元接触。这类接口主要用于治疗一些神经性疾病,如帕金森病、癫痫、失明等。一些创新技术,如Neuralink的N1植入式脑机接口,正朝着这个方向发展。
非侵入式脑机接口:非侵入式接口不需要直接接触大脑组织,因此风险较低。它们通常通过在头皮上安装电极来读取大脑活动。最常见的非侵入式脑机接口技术是脑电图(EEG),它可以检测大脑皮层的电活动。非侵入式脑机接口主要应用于神经康复、辅助交流、游戏等领域。
尽管脑机接口技术在过去的几十年里取得了显著进展,但仍然面临许多挑战,如提高信号质量和分辨率、减小设备尺寸、提高植入设备的生物相容性等。此外,脑机接口技术的发展还涉及伦理、法律和社会问题,如隐私、人格权和技术普及等。
提高信号处理和解码算法:为了从脑电信号中提取有意义的信息,研究人员需要开发更先进的信号处理和解码算法。这些算法需要能够在嘈杂的神经信号中准确地检测到相关的信号,从而提高BMI的性能。
自适应和学习系统:随着时间的推移,大脑和BMI系统之间的交互可能会发生变化。为了适应这些变化,BMI系统需要具有自适应和学习能力,以便在长期使用中保持高性能。
无线和低功耗技术:随着BMI技术的应用范围不断扩大,无线和低功耗的设备变得越来越重要。这可以减少患者的不适,提高设备的可穿戴性和便携性。
长期稳定和生物相容性:植入式BMI设备需要能够长期稳定地工作,同时保持与生物组织的良好相容性。这需要研究新型生物材料和制造技术,以降低感染风险和免疫反应。
多模态脑机接口:结合不同类型的脑机接口技术(如侵入式和非侵入式),以实现更高的信号质量和解析度。这可能需要开发新的集成技术和算法。
伦理和法律问题:随着BMI技术的发展,需要关注患者的隐私、自主权、安全和责任等伦理和法律问题。这可能需要制定新的法规和政策,以确保技术的合理应用和监管。
普及和公平性:BMI技术有可能改变人类的生活方式,但也可能导致社会不平等问题。因此,研究人员和政策制定者需要关注如何确保技术的普及和公平性。
八、GitHub Copilot
GitHub Copilot 是一个基于AI的代码自动完成工具,由GitHub与OpenAI合作开发。它使用了OpenAI的GPT-3(Generative Pre-trained Transformer 作为底层的语言模型,经过大量的代码库训练,学习了多种编程语言和框架的知识。
GitHub Copilot 能够理解用户输入的代码上下文,为用户提供合适的代码片段或函数建议。它旨在帮助开发者更高效地编写代码,减少重复性工作,提供解决问题的灵感,并在某种程度上降低编程门槛。GitHub Copilot可以在各种编程环境中使用,如Visual Studio Code插件等。
虽然GitHub Copilot在许多情况下可以生成有用的代码建议,但它并不是完美的。有时候,它可能会生成不符合预期、不安全或低效的代码。因此,开发者在使用Copilot时仍需要仔细审查和测试生成的代码,确保其符合项目需求和质量标准。
AI合集:https://www.amz123.com/ai
ai-bot.cn