Spark数据库操作初步
本文的操作环境和安装的版本
- 操作系统:Windows 10 1909版本
- IDE:IntelliJ IDEA Ultimate 2019.2.4版本
- JDK:1.8.0_221
- Hadoop:2.7.1
- Spark:3.0.0-preview
- Scala:2.12.10
- Maven:3.6.2
- 数据库:MySQL 8.0.18
一、准备工作
在之前环境的基础上我们需要安装一个数据库,本文选取MySQL最新版本8.0.18。安装部署数据库的方法不再详述,各位可以参考
MySQL 8.0.18安装教程(Windows 64位)
。
数据库完成部署之后可以在IntelliJ IDEA中用附带的插件进行连接,点击右侧栏中的Database,添加新的MySQL连接,设置界面如下。

如果没有连接驱动,直接默认下载最新版的即可(虽然最新版的是8.0.15,但是实测可以连接8.0.18版本的MySQL数据库)。URL处一定要指定时区,否则会连接失败;另外注意输入正确的用户名和密码。此时点击测试连接应该会出现上图中绿色的对勾和相关信息,点击OK即可。
然后在Database栏位中创建一个新的数据库,名为:hivemetastore。然后在其中创建相应的表并且导入一些示例数据。
drop table if exists people;
create table people(
id serial primary key,
name varchar(20),
level smallint default 0
);
insert into people values (1, 'zhu', 4), (2, 'katus', 5), (3, 'li', 4);
然后我们需要在pom.xml中补充新的依赖,即MySQL连接驱动相关依赖,更新之后的pom.xml如下。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>zju</groupId>
<artifactId>WordCount</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<jdk.version>1.8.0</jdk.version>
<spark.version>3.0.0-preview</spark.version>
<scala.version>2.12</scala.version>
<mysql.version>8.0.18</mysql.version>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-hive -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
</dependencies>
</project>
然后倒入相关依赖,完成即可。
二、Spark连接数据库
以下是一份连接hivemetastore数据库,读取people表中全部数据并显示在控制台的代码。
import org.apache.spark.sql.SQLContext;
import org.apache.spark.sql.SparkSession;
import java.util.Properties;
public class DbConnect {
public static void main(String[] args) {
SparkSession session = SparkSession.builder().getOrCreate();
SQLContext sqlContext = new SQLContext(session);
// 数据库连接参数
String dbUrl = "jdbc:mysql://localhost:3306/hivemetastore?serverTimezone=Asia/Shanghai";
String tableName = "people";
Properties connectionProperties = new Properties();
connectionProperties.put("user", "root");
connectionProperties.put("password", "xxxxx123");
connectionProperties.put("driver", "com.mysql.cj.jdbc.Driver");
// 读取hivemetastore数据库中的people表的全部内容
sqlContext.read().jdbc(dbUrl, tableName, connectionProperties).select("*").show();
session.stop();
}
}
运行之后在控制台会有如下输出。(没有截取Spark集群的状态信息的控制台输出)

对上面的代码进行简单的解释就是,SQLContext是所有的数据库操作的核心。SQLContext对象的read函数会返回一个DataFrameReader对象,DataFrameReader对象可以调用jdbc函数返回读取的数据库表,类型为Dataset,Dataset调用select可以筛选出一个至多个数据列(此处选择全部列其实是可以省略的,对结果没有影响),然后可以通过直接调用show函数直接以表格的形式直接输出在控制台。
Spark官方文档有一段对SQLContext类的描述:“As of Spark 2.0, this is replaced by SparkSession. However, we are keeping the class here for backward compatibility.”;也就是说,在Spark 2.0之后的版本可以直接用SparkSession替代SQLContext,SQLContext的保留只是为了向下兼容。实测也是可以替代的。
三、简单的读取数据库操作
为了体现出更多的数据库操作,将示例表格和数据进行复杂化,更新如下。
drop table if exists people;
create table people(
id int primary key,
name varchar(20),
level smallint default 0,
experience float
);
insert into people values (1, 'zhu', 4, 48.24), (2, 'katus', 5, 82.49), (3, 'li', 4, 56.34);
drop table if exists device;
create table device(
id serial primary key,
name varchar(20),
price float default 0,
ownerId int references people(id)
);
insert into device values (1, 'computer', 6250.5, 2), (2, 'radio', 126.4, 1);
查询经验值大于50的人的姓名(name)和级别(level)并输出到控制台。
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.SQLContext;
import org.apache.spark.sql.Dataset;
import java.util.Properties;
public class DbConnect {
public static void main(String[] args) {
SparkSession session = SparkSession.builder().getOrCreate();
SQLContext sqlContext = new SQLContext(session);
// 数据库连接参数
String dbUrl = "jdbc:mysql://localhost:3306/hivemetastore?serverTimezone=Asia/Shanghai";
String tableName = "people";
Properties connectionProperties = new Properties();
connectionProperties.put("user", "root");
connectionProperties.put("password", "xxxxx123");
connectionProperties.put("driver", "com.mysql.cj.jdbc.Driver");
// 查询经验值大于50的人的姓名(name)和级别(level)并输出到控制台
Dataset people = sqlContext.read().jdbc(dbUrl, tableName, connectionProperties).select("*");
people.select("name", "level").filter(people.col("experience").gt(50)).show();
session.stop();
}
}
输出结果如图。

查询拥有ID为1的设备的人对应的编号(ID)、姓名(name)和经验值(experience)。
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.SQLContext;
import org.apache.spark.sql.Dataset;
import scala.Tuple2;
import java.util.Properties;
public class DbConnect {
public static void main(String[] args) {
SparkSession session = SparkSession.builder().getOrCreate();
SQLContext sqlContext = new SQLContext(session);
// 数据库连接参数
String dbUrl = "jdbc:mysql://localhost:3306/hivemetastore?serverTimezone=Asia/Shanghai";
Properties connectionProperties = new Properties();
connectionProperties.put("user", "root");
connectionProperties.put("password", "xxxxx123");
connectionProperties.put("driver", "com.mysql.cj.jdbc.Driver");
// 查询拥有ID为1的设备的人对应的编号(ID)、姓名(name)和经验值(experience)
Dataset people = sqlContext.read().jdbc(dbUrl, "people", connectionProperties);
Dataset device = sqlContext.read().jdbc(dbUrl, "device", connectionProperties);
JavaPairRDD peopleRDD = people.toJavaRDD().mapToPair((PairFunction<Row, Integer, Tuple2<String, Double>>) row -> {
Integer personId = (Integer) row.get(0);
String personName = (String) row.get(1);
Double personExp = (Double) row.get(3);
return new Tuple2<>(personId, new Tuple2<>(personName, personExp));
});
JavaPairRDD deviceRDD = device.toJavaRDD().mapToPair((PairFunction<Row, Integer, Integer>) row -> {
Integer deviceId = (Integer) row.get(0);
Integer ownerId = (Integer) row.get(3);
return new Tuple2<>(ownerId, deviceId);
});
for (Tuple2<Integer, Tuple2<Tuple2<String, Double>, Integer>> item : (Iterable<Tuple2<Integer, Tuple2<Tuple2<String, Double>, Integer>>>) peopleRDD.join(deviceRDD).collect()) {
if (item._2()._2() == 1) {
System.out.println("id: " + item._1().toString() + " ; name: " + item._2()._1()._1() + " ; exp: " + item._2()._1()._2().toString());
}
}
session.stop();
}
}
运行结果如图。

最后一个查询相对而言还是十分复杂的,此处涉及到两个表格的自然连接操作,直接对单一表格的SQL查询是难以实现的,因此将每个表格的查询结果转化为RDD,然后使用RDD中的join操作,最后遍历结果,筛选出符合条件的记录。但是这种实现从代码角度考虑前面的操作虽然有分布式计算的加速,但是最后对于join结果的遍历是完全依靠Driver程序实现的,这个运算效率会大大下降,因此可以考虑在join之前就对表格记录进行尽可能地筛选,减少最后Driver程序的运算量。(当然这个只是个人的实现,可能还存在更加简单高效的实现方法,待进一步研究)
四、简单的写入数据库操作
实现向数据库表people中插入两条数据,初始时数据库people表记录如下。
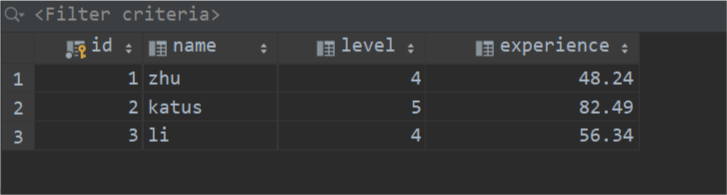
然后新创建一个Java类,填充如下代码。
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructType;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Properties;
public class DbWrite {
public static void main(String[] args) {
SparkSession session = SparkSession.builder().getOrCreate();
JavaSparkContext sparkContext = JavaSparkContext.fromSparkContext(session.sparkContext());
// 数据库连接参数
String dbUrl = "jdbc:mysql://localhost:3306/hivemetastore?serverTimezone=Asia/Shanghai";
Properties connectionProperties = new Properties();
connectionProperties.put("user", "root");
connectionProperties.put("password", "xxxxx123");
connectionProperties.put("driver", "com.mysql.cj.jdbc.Driver");
// 构建新的数据记录RDD
JavaRDD<String> personData = sparkContext.parallelize(Arrays.asList("4,jiang,5,79.46", "5,wan,4,63.49"));
// 将RDD成员(String)分割成四个field
JavaRDD<Row> personsRDD = personData.map((Function<String, Row>) line -> {
String[] splited = line.split(",");
return RowFactory.create(Integer.valueOf(splited[0]), splited[1], Integer.valueOf(splited[2]), Double.valueOf(splited[3]));
});
List structFields = new ArrayList();
structFields.add(DataTypes.createStructField("id", DataTypes.IntegerType, false));
structFields.add(DataTypes.createStructField("name", DataTypes.StringType, true));
structFields.add(DataTypes.createStructField("level", DataTypes.IntegerType, true));
structFields.add(DataTypes.createStructField("experience", DataTypes.DoubleType, true));
// 构建StructType(类似创建一个表格结构的描述)
StructType structType = DataTypes.createStructType(structFields);
// 构建数据集(用于和数据库对接)
Dataset personsDF = session.createDataFrame(personsRDD, structType);
// 以追加的形式写入数据库的people
personsDF.write().mode("append").jdbc(dbUrl, "people", connectionProperties);
session.stop();
}
}
运行之后数据库中数据发生了如下变化。
