【导读】在应用中使用深度学习的挑战之一是管理加载模型进行推理的成本。在本文中,我们将展示如何利用 PyTorch 和 Ray 的功能将这一成本几乎降至零。
Introduction
深度学习模型庞大而繁琐。由于它们的大小,它们需要很长时间才能加载。管理这种加载成本需要复杂的系统来在生产中部署模型。TFX、TorchServe 和 IBM Spectrum Conductor Deep Learning Impact 等模型推理平台在专用的、长期存在的流程和容器中运行深度学习模型,并有额外的层来管理容器并在它们之间传递数据。
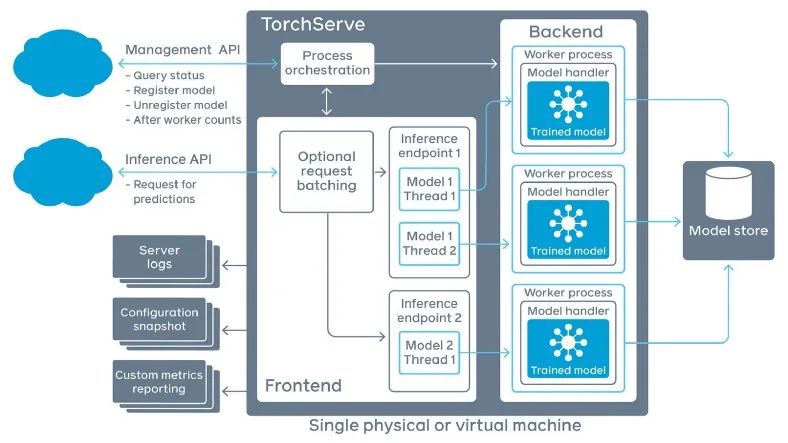
TorchServe 模型推理平台的框图,显示 TorchServe 如何为每个模型分配一个专用的、长期存在的进程池,以分摊模型加载成本。这些进程池给它们上面和下面的层增加了额外的复杂性。
但是,如果这种传统智慧不完全正确呢?如果有一种方法可以在几分之一秒内加载深度学习模型呢?它可能为在生产中运行深度学习的更简单方法打开大门。
让我们看看可以让模型加载多快。
BERT
对于本文中的示例,我们将使用 BERT 掩码语言模型。BERT 属于一组通用模型,它们以(相对)紧凑的格式捕捉人类语言的细微差别。您可以使用这些模型来执行许多不同的自然语言处理 (NLP) 任务,从文档分类到机器翻译。但是,要以高精度执行任何任务,您需要从在目标语言上训练的模型开始,并针对任务微调模型。
为任务调整 BERT 模型有效地创建了一个新模型。如果您的应用程序需要以三种不同的语言执行三项任务,您将需要 BERT 的九个副本:一个用于语言和任务的每种组合。模型的这种激增给生产带来了麻烦。能够快速加载和卸载基于 BERT 的模型会省去很多麻烦。
让我们从以最直接的方式加载 BERT 模型开始。
加载 BERT 模型
Huggingface 的转换器库提供了方便的方法来加载 BERT 的不同变体。下面的代码片段展示了如何加载 bert-base-uncased,这是一个具有大约 420 MB 参数的中型模型。
bert = transformers.BertModel.from_pretrained("bert-base-uncased")
Transformers.BertModel.from_pretrained() 方法遵循 PyTorch 推荐的加载模型的做法:首先,构建模型的一个实例,它应该是 torch.nn.Module 的子类。然后使用 torch.load() 加载模型权重的 PyTorch 状态字典。最后,调用模型的 load_state_dict() 方法将模型权重从状态字典复制到模型的 torch.Tensor 对象中。
如果模型在本地磁盘上,此方法加载 BERT 大约需要 1.4 秒。对于一个大小超过 400MB 的模型来说,这是相当令人印象深刻的,但仍然需要很长时间。为了进行比较,使用此模型运行推理只需几分之一秒。
这种方法如此缓慢的主要原因是它针对通过慢速网络连接以便携式方式读取模型进行了优化。它在构建状态字典时多次复制模型的参数,然后在将权重安装到模型的 Python 对象中时再复制一些。
PyTorch 有一种替代模型加载方法,它放弃了一些兼容性,但只复制模型权重一次。以下是使用该方法加载 BERT 的代码:
# Serialize the model we loaded in the previous code listing.
torch.save(bert, "bert.pt")
# Load the model back in.
bert_2 = torch.load("bert.pt")
此方法在同一台机器上以 0.125 秒加载 BERT。快了 11 倍。
如果将副本数降为 1 会使模型加载速度更快,想象一下如果我们将副本数降为零会发生什么!有可能这样做吗?
零拷贝模型加载
事实证明,我们确实可以在复制权重零次的同时加载 PyTorch 模型。我们可以通过利用 PyTorch 和 Ray 的一些特性来实现这一目标。
首先,介绍一下 Ray 的背景。
**Ray 是一个用于构建高性能分布式应用程序的开源系统。Ray 的独特功能之一是它的主内存对象存储 Plasma,它使用共享内存在 Ray 集群中每台机器上的进程之间传递对象。Ray 使用 Plasma 来实现 NumPy 数组的零拷贝传输。**如果 Ray 任务需要从 Plasma 读取 NumPy 数组,则该任务可以直接从共享内存中访问该数组的数据,而无需将任何数据复制到其本地堆中。
如果我们将模型的权重作为 NumPy 数组存储在 Plasma 上,我们可以直接从 Plasma 的共享内存段中访问这些权重,而无需进行任何复制。
但是我们仍然需要将这些权重连接到 PyTorch 模型的其余部分,这需要将它们包装在 PyTorch Tensor 对象中。创建张量的标准方法包括复制张量的内容,但 PyTorch 也有一个替代代码路径,用于在不执行复制的情况下初始化Tensor。您可以通过将 NumPy 数组传递给 torch.as_tensor() 而不是使用 Tensor.__new__() 来访问此代码路径。
考虑到所有这些背景信息,这里是如何从 Plasma 进行零拷贝模型加载的高级概述。首先,您需要将模型加载到 Plasma 对象存储中,这是一个三步过程:
-
从磁盘加载模型。
-
将原始 PyTorch 模型分为权重和操作图,并将权重转换为 NumPy 数组。
-
将 NumPy 数组和模型(减去权重)上传到 Plasma。
一旦模型及其权重在对象存储中,就可以对模型进行零拷贝加载。以下是要遵循的步骤:
-
从 Plasma 反序列化模型(减去权重)
-
从 Plasma 中提取权重(不复制数据)
-
将权重包裹在 PyTorch 张量中(无需复制)
-
将权重张量安装回重建的模型中(无需复制)
如果模型的副本在本地机器的 Plasma 共享内存段中,这些步骤将在 0.004 秒内加载加载 BERT。这比使用 BertModel.from_pretrained() 加载模型快 340 倍。
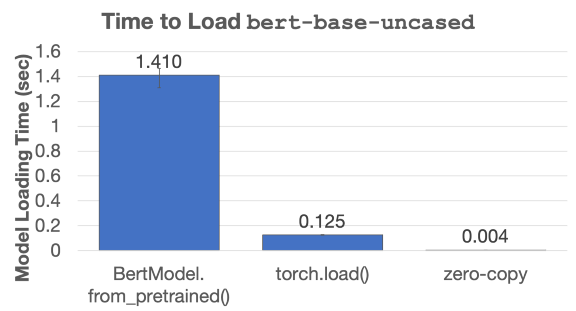
加载 BERT 语言模型的三种不同方式的运行时间比较。计时是在配备 2.3 GHz Intel Core i9 处理器的 MacBook Pro 上运行 100 次的平均值。与标准的 BertModel.from_pretrained() 模型加载 API 相比,零拷贝模型加载将加载时间减少了 340 倍。
更重要的是,此加载时间比使用通用 CPU 在此模型上运行一个推理请求所需的时间少一个数量级。这意味着您可以按需加载模型而几乎没有性能损失。需要启动一个专用的模型服务平台或 Ray 演员池,为当前未运行推理的模型占用资源。
The Details
让我们分解如何实现零拷贝模型加载的每个步骤,首先是将模型以适当的格式加载到 Plasma 上。
我们已经介绍了如何从磁盘加载 PyTorch 模型。初始加载后的下一步是将模型分为权重和操作图,将权重转换为 NumPy 数组。这是一个可以完成所有这些事情的 Python 函数。
def extract_tensors(m: torch.nn.Module) -> Tuple[torch.nn.Module, List[Dict]]:
"""
Remove the tensors from a PyTorch model, convert them to NumPy
arrays, and return the stripped model and tensors.
"""
tensors = []
for _, module in m.named_modules():
# Store the tensors in Python dictionaries
params = {
name: torch.clone(param).detach().numpy()
for name, param in module.named_parameters(recurse=False)
}
buffers = {
name: torch.clone(buf).detach().numpy()
for name, buf in module.named_buffers(recurse=False)
}
tensors.append({"params": params, "buffers": buffers})
# Make a copy of the original model and strip all tensors and
# buffers out of the copy.
m_copy = copy.deepcopy(m)
for _, module in m_copy.named_modules():
for name in ([name for name, _ in module.named_parameters(recurse=False)]
+ [name for name, _ in module.named_buffers(recurse=False)]):
setattr(module, name, None)
# Make sure the copy is configured for inference.
m_copy.train(False)
return m_copy, tensors
大多数 PyTorch 模型都建立在 PyTorch 类 torch.nn.Module 之上。模型是 Python 对象的图,每个对象都是 Module 的子类。
Module 类提供了两个位置来存储模型权重:通过梯度下降训练的权重的参数,以及以其他方式训练的权重的缓冲区。上面清单的第 6-17 行迭代模型的组件,提取参数和缓冲区,并将它们的值转换为 NumPy 数组。然后第 21-25 行创建模型的副本并从副本中删除所有权重。最后,第 29 行将副本和转换后的权重张量作为 Python 元组返回。
我们可以将这个函数的返回值直接传递给 ray.put() 以将模型及其权重上传到 Plasma。这是上传操作的样子。
bert_ref = ray.put(extract_tensors(bert))
这里的变量 bert_ref 是一个 Ray 对象引用。我们可以通过将此对象引用传递给 ray.get() 来检索模型和权重,如下所示。
bert_skeleton, bert_weights = ray.get(bert_ref)
如果 bert_ref 指向的对象在 Ray 集群的当前节点上不可用,则在 Ray 将对象下载到节点的本地共享内存段时,第一次读取模型的尝试将被阻止。对 ray.get(bert_ref) 的后续调用将立即返回本地副本。
现在我们需要将 bert_weights 从 NumPy 数组转换为 torch.Tensor 对象并将它们附加到 bert_skeleton 中的模型,所有这些都不需要执行任何额外的副本。这是一个执行这些步骤的 Python 函数。
def replace_tensors(m: torch.nn.Module, tensors: List[Dict]):
"""
Restore the tensors that extract_tensors() stripped out of a
PyTorch model.
:param no_parameters_objects: Skip wrapping tensors in
``torch.nn.Parameters`` objects (~20% speedup, may impact
some models)
"""
modules = [module for _, module in m.named_modules()]
for module, tensor_dict in zip(modules, tensors):
# There are separate APIs to set parameters and buffers.
for name, array in tensor_dict["params"].items():
module.register_parameter(name,
torch.nn.Parameter(torch.as_tensor(array)))
for name, array in tensor_dict["buffers"].items():
module.register_buffer(name, torch.as_tensor(array))
该函数与 PyTorch 的 load_state_dict() 函数的作用大致相同,只是它避免了复制张量。replace_tensors() 函数就地修改重建的模型。调用 replace_tensors() 后,我们可以运行模型,产生与模型原始副本相同的结果。这是一些代码,显示在使用 replace_tensors() 加载权重后运行 BERT 模型。
# Load tensors into the model's graph of Python objects
replace_tensors(bert_skeleton, bert_weights)
# Preprocess an example input string for BERT.
test_text = "All work and no play makes Jack a dull boy."
tokenizer = transformers.BertTokenizerFast.from_pretrained(
"bert-base-uncased")
test_tokens = tokenizer(test_text, return_tensors="pt")
# Run the original model and the copy that we just loaded
print("Original model's output:")
print(bert(**test_tokens).last_hidden_state)
print("\nModel output after zero-copy model loading:")
print(bert_skeleton(**test_tokens).last_hidden_state)
output:
Original model's output:
tensor([[[-0.1153, 0.2566, -0.2220, ..., -0.3130, 0.6333, 0.6588],
[ 0.2769, 0.5195, 0.2059, ..., -0.1062, 1.1186, 0.3836],
[ 0.9019, 0.7557, -0.1615, ..., 0.0588, 0.3570, -0.0296],
...,
[ 0.0155, -0.0602, 0.3365, ..., -0.0936, 0.8055, -0.5007],
[ 0.6198, 0.2695, -0.3402, ..., 0.0860, -0.3373, -0.4606],
[ 0.8493, 0.3726, -0.2073, ..., -0.1145, -0.5216, -0.4418]]],
grad_fn=<NativeLayerNormBackward>)
注意事项
第一次调用 replace_tensors() 函数时,PyTorch 会打印出警告:
UserWarning: The given NumPy array is not writeable, and PyTorch does not support
non-writeable tensors. This means you can write to the underlying (supposedly
non-writeable) NumPy array using the tensor. [...]
大多数 PyTorch 模型在推理过程中不会修改自己的权重,但 PyTorch 不会阻止模型这样做。如果您通过零复制方法加载您的权重并且您的模型修改了一个权重张量,它将更改 Plasma 共享内存中这些权重的副本。Ray(从 1.4 版开始)总是以读写模式打开共享内存段。
如果您确定您的模型在推理过程中不会修改自己的权重,则可以放心地忽略此警告。您可以通过比较推理前后模型的权重来测试这些修改。如果您的模型确实修改了其某些权重,则在运行推理之前复制相关张量非常重要。
另一件要注意的事情是,此方法会加载用于基于 CPU 的推理的模型。要使用 GPU 加速,您需要复制模型的权重一次以将它们加载到 GPU 内存中。这个复制操作大约需要 0.07 秒,这仍然是将模型加载到 GPU 上的第二快方法的三倍。
最后要注意的一件事:
上面的代码仅适用于 PyTorch。使用 TensorFlow 实现零拷贝模型加载在理论上是可能的,但在实践中要困难得多。
参考链接:
https://medium.com/ibm-data-ai/how-to-load-pytorch-models-340-times-faster-with-ray-8be751a6944c
学习交流
目前开通了技术交流群,群友超过
500人
,添加时最好备注形式为:来源+兴趣方向,方便找到志同道合的朋友
- 方式1、发送如下图片至微信,长按识别,关注后台回复:加群;
- 方式2、微信搜索公众号:机器学习社区,关注后台回复:加群;
