作者 | 帅性而为1号
出处 :
https://blog.csdn.net/zhushuai1221/article/details/51740846
网上关于SQL优化的教程很多,但是比较杂乱。近日有空整理了一下,写出来跟大家分享一下,其中有错误和不足的地方,还请大家纠正补充。
这篇文章我花费了大量的时间查找资料、修改、排版,希望大家阅读之后,感觉好的话推荐给更多的人,让更多的人看到、纠正以及补充。
一、百万级数据库优化方案
1.对查询进行优化,要尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num is null最好不要给数据库留NULL,尽可能的使用 NOT NULL填充数据库.
备注、描述、评论之类的可以设置为 NULL,其他的,最好不要使用NULL。
不要以为 NULL 不需要空间,比如:char(100) 型,在字段建立时,空间就固定了, 不管是否插入值(NULL也包含在内),都是占用 100个字符的空间的,如果是varchar这样的变长字段, null 不占用空间。
可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:
select id from t where num = 03.应尽量避免在 where 子句中使用 != 或 <> 操作符,否则将引擎放弃使用索引而进行全表扫描。
4.应尽量避免在 where 子句中使用 or 来连接条件,如果一个字段有索引,一个字段没有索引,将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num=10 or Name = 'admin'可以这样查询:select id from t where num = 10union allselect id from t where Name = 'admin'5.in 和 not in 也要慎用,否则会导致全表扫描,如:select id from t where num in(1,2,3)对于连续的数值,能用 between 就不要用 in 了:
select id from t where num between 1 and 3很多时候用 exists 代替 in 是一个好的选择:
select num from a where num in(select num from b)用下面的语句替换:
select num from a where exists(select 1 from b where num=a.num)6.下面的查询也将导致全表扫描:
select id from t where name like ‘%abc%’若要提高效率,可以考虑全文检索。
7.如果在 where 子句中使用参数,也会导致全表扫描。因为SQL只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推迟到运行时;它必须在编译时进行选择。然 而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where num/2 = 100应改为:select id from t where num = 100*29.应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。
10.不要在 where 子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。
11.在使用索引字段作为条件时,如果该索引是复合索引,那么必须使用到该索引中的第一个字段作为条件时才能保证系统使用该索引,否则该索引将不会被使用,并且应尽可能的让字段顺序与索引顺序相一致。
12.不要写一些没有意义的查询,如需要生成一个空表结构:
select col1,col2 into #t from t where 1=0
这类代码不会返回任何结果集,但是会消耗系统资源的
13.Update 语句,如果只更改1、2个字段,不要Update全部字段,否则频繁调用会引起明显的性能消耗,同时带来大量日志。
14.对于多张大数据量(这里几百条就算大了)的表JOIN,要先分页再JOIN,否则逻辑读会很高,性能很差。
15.select count(*) from table;这样不带任何条件的count会引起全表扫描,并且没有任何业务意义,是一定要杜绝的。
16.索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有 必要。
17.应尽可能的避免更新 clustered 索引数据列,因为 clustered 索引数据列的顺序就是表记录的物理存储顺序,一旦该列值改变将导致整个表记录的顺序的调整,会耗费相当大的资源。若应用系统需要频繁更新 clustered 索引数据列,那么需要考虑是否应将该索引建为 clustered 索引。
18.尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连 接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
19.尽可能的使用 varchar/nvarchar 代替 char/nchar ,因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
20.任何地方都不要使用 select * from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段。
21.尽量使用表变量来代替临时表。如果表变量包含大量数据,请注意索引非常有限(只有主键索引)。
22. 避免频繁创建和删除临时表,以减少系统表资源的消耗。临时表并不是不可使用,适当地使用它们可以使某些例程更有效,例如,当需要重复引用大型表或常用表中的某个数据集时。但是,对于一次性事件, 最好使用导出表。
23.在新建临时表时,如果一次性插入数据量很大,那么可以使用 select into 代替 create table,避免造成大量 log ,以提高速度;如果数据量不大,为了缓和系统表的资源,应先create table,然后insert。
24.如果使用到了临时表,在存储过程的最后务必将所有的临时表显式删除,先 truncate table ,然后 drop table ,这样可以避免系统表的较长时间锁定。
25.尽量避免使用游标,因为游标的效率较差,如果游标操作的数据超过1万行,那么就应该考虑改写。
26.使用基于游标的方法或临时表方法之前,应先寻找基于集的解决方案来解决问题,基于集的方法通常更有效。
27.与临时表一样,游标并不是不可使用。对小型数据集使用 FAST_FORWARD 游标通常要优于其他逐行处理方法,尤其是在必须引用几个表才能获得所需的数据时。在结果集中包括“合计”的例程通常要比使用游标执行的速度快。如果开发时 间允许,基于游标的方法和基于集的方法都可以尝试一下,看哪一种方法的效果更好。
28.在所有的存储过程和触发器的开始处设置 SET NOCOUNT ON ,在结束时设置 SET NOCOUNT OFF 。无需在执行存储过程和触发器的每个语句后向客户端发送 DONE_IN_PROC 消息。
29.尽量避免大事务操作,提高系统并发能力。
30.尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理。
二、数据库访问性能优化
特别说明:
1、 本文只是面对数据库应用开发的程序员,不适合专业DBA,DBA在数据库性能优化方面需要了解更多的知识;
2、 本文许多示例及概念是基于Oracle数据库描述,对于其它关系型数据库也可以参考,但许多观点不适合于KV数据库或内存数据库或者是基于SSD技术的数据库;
3、 本文未深入数据库优化中最核心的执行计划分析技术。
读者对像:
开发人员:如果你是做数据库开发,那本文的内容非常适合,因为本文是从程序员的角度来谈数据库性能优化。
架构师:如果你已经是数据库应用的架构师,那本文的知识你应该清楚90%,否则你可能是一个喜欢折腾的架构师。
DBA(数据库管理员):大型数据库优化的知识非常复杂,本文只是从程序员的角度来谈性能优化,DBA除了需要了解这些知识外,还需要深入数据库的内部体系架构来解决问题。
在网上有很多文章介绍数据库优化知识,但是大部份文章只是对某个一个方面进行说明,而对于我们程序员来说这种介绍并不能很好的掌握优化知识,因为很多介绍只是对一些特定的场景优化的,所以反而有时会产生误导或让程序员感觉不明白其中的奥妙而对数据库优化感觉很神秘。
很多程序员总是问如何学习数据库优化,有没有好的教材之类的问题。在书店也看到了许多数据库优化的专业书籍,但是感觉更多是面向DBA或者是PL/SQL开发方面的知识,个人感觉不太适合普通程序员。而要想做到数据库优化的高手,不是花几周,几个月就能达到的,这并不是因为数据库优化有多高深,而是因为要做好优化一方面需要有非常好的技术功底,对操作系统、存储硬件网络、数据库原理等方面有比较扎实的基础知识,另一方面是需要花大量时间对特定的数据库进行实践测试与总结。
作为一个程序员,我们也许不清楚线上正式的服务器硬件配置,我们不可能像DBA那样专业的对数据库进行各种实践测试与总结,但我们都应该非常了解我们SQL的业务逻辑,我们清楚SQL中访问表及字段的数据情况,我们其实只关心我们的SQL是否能尽快返回结果。那程序员如何利用已知的知识进行数据库优化?如何能快速定位SQL性能问题并找到正确的优化方向?
面对这些问题,笔者总结了一些面向程序员的基本优化法则,本文将结合实例来坦述数据库开发的优化知识。
要正确的优化SQL,我们需要快速定位能性的瓶颈点,也就是说快速找到我们SQL主要的开销在哪里?而大多数情况性能最慢的设备会是瓶颈点,如下载时网络速度可能会是瓶颈点,本地复制文件时硬盘可能会是瓶颈点,为什么这些一般的工作我们能快速确认瓶颈点呢,因为我们对这些慢速设备的性能数据有一些基本的认识,如网络带宽是2Mbps,硬盘是每分钟7200转等等。因此,为了快速找到SQL的性能瓶颈点,我们也需要了解我们计算机系统的硬件基本性能指标,下图展示的当前主流计算机性能指标数据。
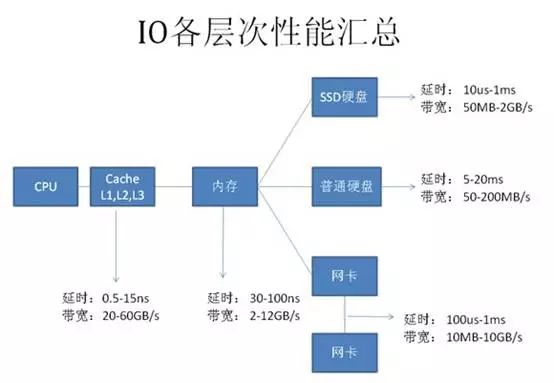
从图上可以看到基本上每种设备都有两个指标:
延时(响应时间):表示硬件的突发处理能力;
带宽(吞吐量):代表硬件持续处理能力。
从上图可以看出,计算机系统硬件性能从高到代依次为:
CPU——Cache(L1-L2-L3)——内存——SSD硬盘——网络——硬盘
由于SSD硬盘还处于快速发展阶段,所以本文的内容不涉及SSD相关应用系统。
根据数据库知识,我们可以列出每种硬件主要的工作内容:
CPU及内存:缓存数据访问、比较、排序、事务检测、SQL解析、函数或逻辑运算;
网络:结果数据传输、SQL请求、远程数据库访问(dblink);
硬盘:数据访问、数据写入、日志记录、大数据量排序、大表连接。
根据当前计算机硬件的基本性能指标及其在数据库中主要操作内容,可以整理出如下图所示的性能基本优化法则:
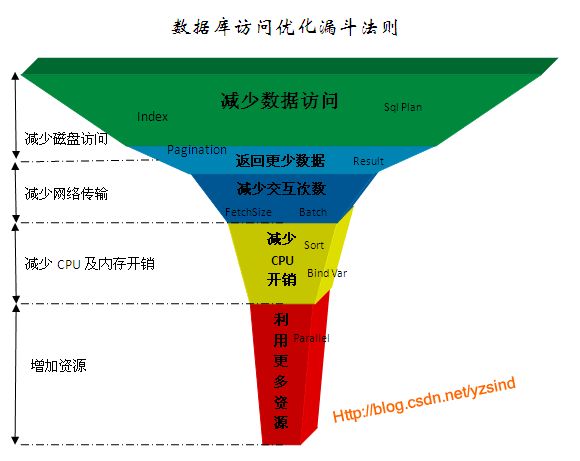
这个优化法则归纳为5个层次:
1、 减少数据访问(减少磁盘访问)
2、 返回更少数据(减少网络传输或磁盘访问)
3、 减少交互次数(减少网络传输)
4、 减少服务器CPU开销(减少CPU及内存开销)
5、 利用更