|
|
|
|
|
|
|
发布时间 |
2012 |
2014 |
2015 |
2015 |
|
层数 |
8 |
19 |
152 |
22 |
|
卷积层数 |
5 |
16 |
151 |
21 |
|
卷积核大小 |
11,5,3 |
3 |
7,1,3,5 |
7,1,3,5 |
|
池化方式 |
MaxPooling |
MaxPooling |
Max+AvgPooling |
Max+AvgPooling |
|
全连接层数 |
3 |
3 |
1 |
1 |
|
全连接层大小 |
4096,4096,1000 |
4096,4096,1000 |
1000 |
1000 |
|
Dropout |
+ |
+ |
+ |
+ |
|
LRN |
+ |
– |
– |
+ |
|
BN |
– |
– |
+ |
– |
1、AlexNet网络
网络核心
- 使用ReLU激活函数(计算开销小、解决梯度消失、网路稀疏性)
- 使用重叠的最大池化(步长比池化核的尺寸小),避免平均池化的模糊效果
- 全连接层中使用Dropout随机失活神经元,避免过拟合
- 提出LRN层,局部响应归一化
-
- 有助于快速收敛
- 对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力
- 公式:
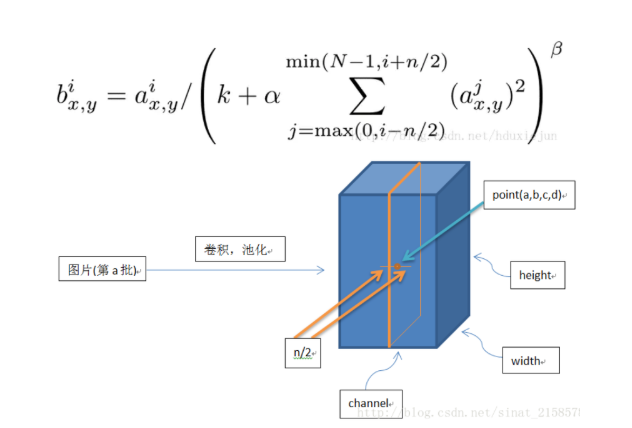
-
- 理解:比如i=10、n=4第10个卷积核在位置x,y处取到特征a,局部响应归一化的过程就是用结构a除以第8、9、10、11、12这几个卷积核在位置x,y处提取的特征值和
架构
- 网络输入:224 * 224 * 3的彩色图片
- 中间层:由5个卷积层和3个最大池化层组成,激活函数为ReLU
- 全连接层:3个全连接层,加入dropout避免过拟合
- 网络输出:1000 * 1 输出向量
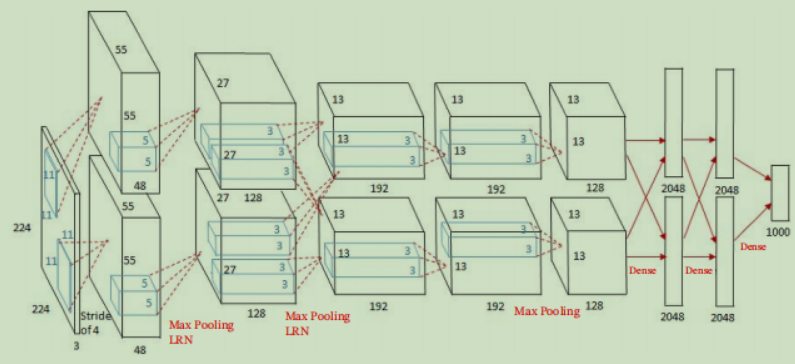
|
layer_name |
kernel_size |
kernel_num |
padding |
stride |
|
conv1 |
11 |
96 |
1 |
4 |
|
maxpool1 |
3 |
none |
0 |
2 |
|
conv2 |
5 |
256 |
2 |
1 |
|
maxpool2 |
3 |
none |
0 |
2 |
|
conv3 |
3 |
384 |
1 |
1 |
|
conv4 |
3 |
384 |
1 |
1 |
|
conv5 |
3 |
256 |
1 |
1 |
|
maxpool3 |
3 |
none |
0 |
2 |
|
fc1 |
2048 |
none |
none |
none |
|
fc2 |
2048 |
none |
none |
none |
|
fc3 |
1000 |
none |
none |
none |
class Alexnet(nn.Module):
def __init__(self):
super(Alexnet,self).__init__()
self.conv1 = nn.Conv2d(3,96,kernel_size=11,stride=4,padding=1)
self.maxpool1 = nn.MaxPool2d(kernel_size=3,stride=2)
self.conv2 = nn.Conv2d(96,256,kernel_size=5,stride=1,padding=2)
self.maxpool2 = nn.MaxPool2d(kernel_size=3,stride=2)
self.conv3 = nn.Conv2d(256,384,kernel_size=3,stride=1,padding=1)
self.conv4 = nn.Conv2d(384,384,kernel_size=3,stride=1,padding=1)
self.conv5 = nn.Conv2d(384,256,kernel_size=3,stride=1,padding=1)
self.maxpool3 = nn.MaxPool2d(kernel_size=3,stride=2)
self.flatten = nn.Flatten()
# 全连接层
self.fc1 = nn.Linear(256*5*5,4096)
self.Dropout = nn.Dropout2d(0.5)
self.fc2 = nn.Linear(4096,4096)
self.fc3 = nn.Linear(4096,10)
def forward(self,x):
x = F.relu(self.conv1(x))
x = self.maxpool1(x)
x = F.relu(self.conv2(x))
x = self.maxpool2(x)
x = F.relu(self.conv3(x))
x = F.relu(self.conv4(x))
x = F.relu(self.conv5(x))
x = self.maxpool3(x)
x = self.flatten(x)
x = self.fc1(x)
x = self.Dropout(x)
x = self.fc2(x)
x = self.fc3(x)
return x网络优缺点
- 优点:
-
- 用ReLU作为激活函数,效果比传统sigmoid好,避免了梯度弥散的问题
- 利用Dropout避免过拟合
- 最大池化避免了平均池化的模糊效果
- 缺点:
-
- 如果移除一个卷积层 ,则整个网络都会退化,认为网络深度对结果很重要
2、VGG网络
网络核心
- CNN的深度增加和小卷积核的使用影响网络分类识别结果
- 使用小卷积核(把网络做深、减少参数量、增加网络非线性)
- 通道数多(通道数逐渐翻倍,提取信息多)
- 图像预处理(将原始图像缩放到不同尺寸,随机裁切到224 * 224的图片并进行反转等操作,增加数据量,防止过拟合)
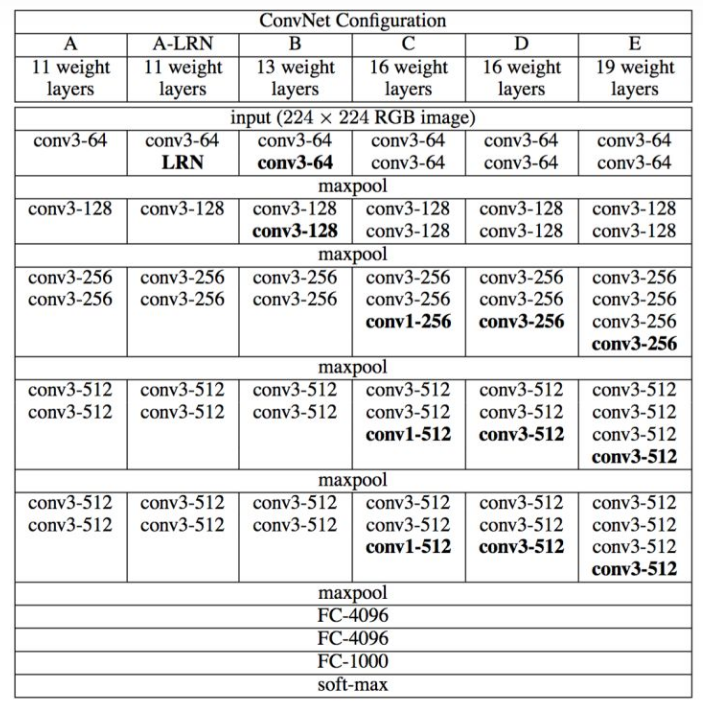
架构(VGG-16)
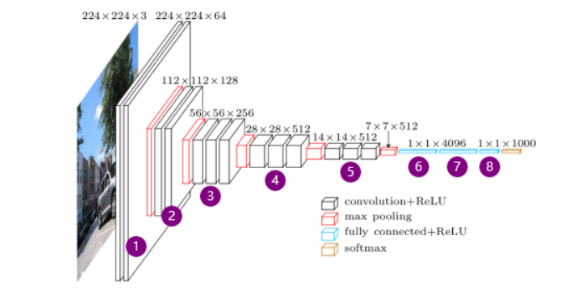
-
网络输入:224
224
3的彩色图像 -
中间层:13个卷积层(3
3,stride=1,padding=1)+5个最大池化层(2
2,stride=2)+ReLU - 全连接层:3个全连接层+ReLU+Dropout
- 网络输出:Softmax输出识别结果,1000个可能类别中的哪一个
class VGGnet(nn.Module):
def __init__(self,num_classes):
super(VGGnet,self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3,64,kernel_size=3,padding=1),
nn.ReLU(),
nn.Conv2d(64,64,kernel_size=3,padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.Conv2d(64,128,kernel_size=3,padding=1),
nn.ReLU(),
nn.Conv2d(128,128,kernel_size=3,padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.Conv2d(128,256,kernel_size=3,padding=1),
nn.ReLU(),
nn.Conv2d(256,256,kernel_size=3,padding=1),
nn.ReLU(),
nn.Conv2d(256,256,kernel_size=3,padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.Conv2d(256,512,kernel_size=3,padding=1),
nn.ReLU(),
nn.Conv2d(512,512,kernel_size=3,padding=1),
nn.ReLU(),
nn.Conv2d(512,512,kernel_size=3,padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.classifier = nn.Sequential(
nn.Linear(512*7*7,4096),
nn.ReLU(),
nn.Linear(4096,4096),
nn.ReLU(),
nn.Dropout(),
nn.Linear(4096,num_classes))
def forward(self,x):
x = self.features(x)
x = x.view(x.size(0),-1) #展开成一维度
x = self.classifier(x)
return x网络优缺点
- 优点:
-
- 结构简单,整个网络只使用相同大小卷积核和最大池化尺寸
- 小卷积核的组合比大卷积核的效果好
- 缺点:
-
- 加深层数、加宽特征图使得耗费更多计算资源,并且使用了更多参数,导致更多的内存占用
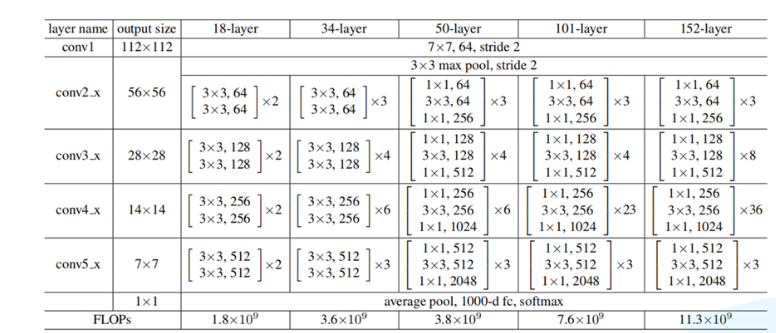
3、ResNet残差网络
网络核心
- 网络结构深(超过1000层)
- 提出残差结构(residual)模块
- 使用Batch Normalization加速训练
残差结构
- why
-
- 解决梯度消失、梯度爆炸问题
- 解决退化问题(层数增加反而预测效果变差)
- what
-
- 设置神经网路某些层跳过下一层神经元的连接,隔层相连,弱化每层之间的强联系
- how
-
- 使用shortcut的连接方式,特征矩阵隔层相加(矩阵相同位置数字相加)
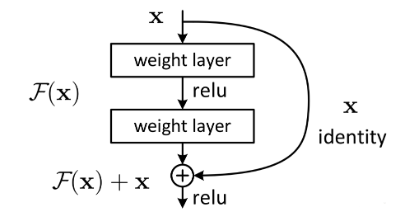
-
- 两种residual
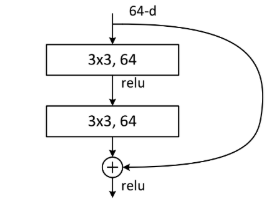
-
-
- BasicBlock
- Bottleneck(与前者相比减少参数个数):两层1 * 1的卷积层,特征矩阵先降维后升维,保证主分支矩阵形状相同
-
Batch Normalization(标准化处理)
-
why
对图像进行标准化处理,加速网络收敛,使整个训练样本集对应的feature map满足分布规律 -
what
将一批数据的feature map满足均值为0,方差为1的分布规律 - how

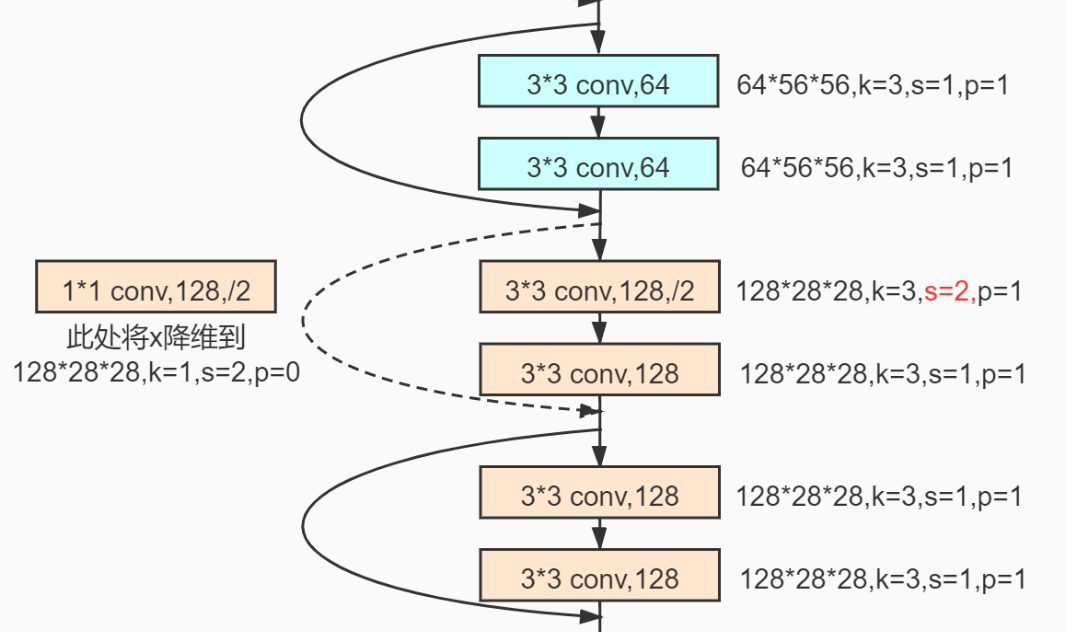
架构
在网络构建过程中,残差模块的shortcut有些是实线的,有些则是虚线的,这些虚线的 short cut 上通过1×1的卷积核进行了维度处理(特征矩阵在长宽方向降采样,深度方向调整成下一层残差结构所需要的channel)
举例:
def conv3x3(in_planes,out_planes,stride=1,groups=1,dilation=1):
return nn.Conv2d(in_planes,out_planes,kernel_size=3,stride=stride,
padding=dilation,groups=groups,bias=False,dilation=dilation)
def conv1x1(in_planes,out_planes,stride=1):
return nn.Conv2d(in_planes,out_planes,kernel_size=1,stride=stride,bias=False)
class BasicBlock(nn.Module):
#基本block类
expansion = 1 #扩张值,用于通道倍增
def __init__(self,inplanes,planes,stride=1,downsample=None,
groups=1,base_width=64,dilation=1,norm_layer=None):
"""
inplanes: 输入通道数
planes: 输出通道数
stride: 步长
downsample: 下采样层
groups: 组数,当为1时不进行分组卷积
base_width: 基本宽度
dilation: 膨胀率
norm_layer: 归一化层
"""
super(BasicBlock,self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
# 组数不等于1或则基本宽度不等于64,则报错,表明只支持组数为1,且base_width为64
if groups != 1 or base_width != 64:
raise ValueError('BasicBlock only supports groups=1 and base_width=64')
# 膨胀只能为1
if dilation > 1:
raise NotImplementedError("Dilation > 1 not supported in BasicBlock")
# Both self.conv1 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv3x3(inplanes, planes, stride) # 3x3卷积层
self.bn1 = norm_layer(planes) # BN层
self.relu = nn.ReLU(inplace=True) # Relu层
self.conv2 = conv3x3(planes, planes) # 3x3卷积层
self.bn2 = norm_layer(planes) # BN层
self.downsample = downsample # 下采样层
self.stride = stride # 步长
def forward(self, x):
identity = x # 恒等值
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None: # 如果下采样层不为None,则进行下采样处理。
identity = self.downsample(x)
out += identity
# 残差连接,与原来x相加
out = self.relu(out)
return out
class Bottleneck(nn.Module):
# Bottleneck in torchvision places the stride for downsampling at 3x3 convolution(self.conv2)
# while original implementation places the stride at the first 1x1 convolution(self.conv1)
# according to "Deep residual learning for image recognition"https://arxiv.org/abs/1512.03385.
# This variant is also known as ResNet V1.5 and improves accuracy according to
# https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch.
expansion = 4 # 扩张值,用于通道数倍增
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None):
super(Bottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.)) * groups # 重新计算输出层
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv1x1(inplanes, width) # 1x1卷积层
self.bn1 = norm_layer(width) # BN层
self.conv2 = conv3x3(width, width, stride, groups, dilation) # 3x3卷积层
self.bn2 = norm_layer(width) # BN层
self.conv3 = conv1x1(width, planes * self.expansion) # 1x1卷积层
self.bn3 = norm_layer(planes * self.expansion) # BN层
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample # 下采样层
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity #残差结构
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000, zero_init_residual=False,
groups=1, width_per_group=64, replace_stride_with_dilation=None,
norm_layer=None):
# block基本模块类BasicBlock(18,34)或者Bottleneck(50,101,152),
# layes=[2, 2, 2, 2]是每个layer的重复次数, num_classes类别数
super(ResNet, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d # norm_layer未指定,默认为nn.BatchNorm2d
self._norm_layer = norm_layer
self.inplanes = 64 # 输入通道数
self.dilation = 1 # 不采用空洞卷积,即膨胀率为1
if replace_stride_with_dilation is None: # 替换步长用膨胀率,如果为None,设置默认值为[False, False, False]
# each element in the tuple indicates if we should replace
# tuple中的每个元素都表示是否应该替换
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3: # 检查是否为None或者长度为3
raise ValueError("replace_stride_with_dilation should be None "
"or a 3-element tuple, got {}".format(replace_stride_with_dilation))
self.groups = groups # 组数为1
self.base_width = width_per_group # 每个组为64
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3,
bias=False) # 第一个卷积层,(3,64,7,2,3)
self.bn1 = norm_layer(self.inplanes) # nn.BatchNorm2d层
self.relu = nn.ReLU(inplace=True) # relu层
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) # 最大池化层
self.layer1 = self._make_layer(block, 64, layers[0]) # 输出层数64,该层重复2次
self.layer2 = self._make_layer(block, 128, layers[1], stride=2, # 输出层数128,该层重复2次,步长为2,
dilate=replace_stride_with_dilation[0])
self.layer3 = self._make_layer(block, 256, layers[2], stride=2, # 输出层数256,该层重复2次
dilate=replace_stride_with_dilation[1])
self.layer4 = self._make_layer(block, 512, layers[3], stride=2, # 输出层数512,该层重复2次
dilate=replace_stride_with_dilation[2])
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # 自适应平均池化层,输出大小为(1,1)
self.fc = nn.Linear(512 * block.expansion, num_classes) # fc层(expansion为1或4)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0)
def _make_layer(self, block, planes, blocks, stride=1, dilate=False):
# 函数BasicBlock类,输出层128,该层重复次数2,步长1,是否使用膨胀参数替代步长
norm_layer = self._norm_layer # nn.BatchNorm2d层
downsample = None # 下采样层初始化
previous_dilation = self.dilation # 先前的膨胀率
if dilate: # 用膨胀,更新膨胀率
self.dilation *= stride # 膨胀率= 1*步长
stride = 1 # 步长为1
# 步长不为1,或self.inplances=64 不等于输出层数乘以基本类的扩张率1 ,则给下采样层赋值
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
) # 1x1的卷积层作为下采样层
layers = []
layers.append(block(self.inplanes, planes, stride, downsample, self.groups,
self.base_width, previous_dilation, norm_layer))
self.inplanes = planes * block.expansion # 更新self.inplanes 值
for _ in range(1, blocks): # 重复次数2的for循环
layers.append(block(self.inplanes, planes, groups=self.groups,
base_width=self.base_width, dilation=self.dilation,
norm_layer=norm_layer))
return nn.Sequential(*layers)
def _forward_impl(self, x):
# See note [TorchScript super()]
# torch.Size([1, 3, 224, 224])
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x) # torch.Size([1, 64, 112, 112])
x = self.maxpool(x) # torch.Size([1, 64, 56, 56])
x = self.layer1(x) # torch.Size([1, 64, 56, 56])
x = self.layer2(x) # torch.Size([1, 128, 28, 28])
x = self.layer3(x) # torch.Size([1, 128, 14, 14])
x = self.layer4(x) # torch.Size([1, 512, 7, 7])
x = self.avgpool(x) # torch.Size([1, 512, 1, 1])
x = torch.flatten(x, 1) # torch.Size([1, 512])
x = self.fc(x) # torch.Size([1, 1000])
return x
def forward(self, x):
return self._forward_impl(x)网络优缺点
- 优点:
-
- 既利用了深层次的神经网络又避免了梯度消散和退化的问题
- ResNet看起来很深但实际起作用的网络层数不是很深,大部分网络层都在防止模型退化,误差过大
- 缺点:
-
- 训练时间长
- 残差不能完全解决梯度消失或者爆炸、网络退化的问题,只能缓解
4、Inception网络
网络核心
- 将多个卷积或池化操作放在一起组装成一个网络模块,以模块为单位组装网络
- 每一层采用不同大小的卷积核提取上一层的特征,最后进行拼接(不同感受野的尺度特征融合)
- 采用1 * 1的卷积降低参数和计算量(缓和由于网络宽度扩大造成的计算量和过拟合问题)
- 引入额外的两个softmax预测层,用于反向传播更新梯度(避免了因梯度消失导致浅层的网络参数无法更新)
架构
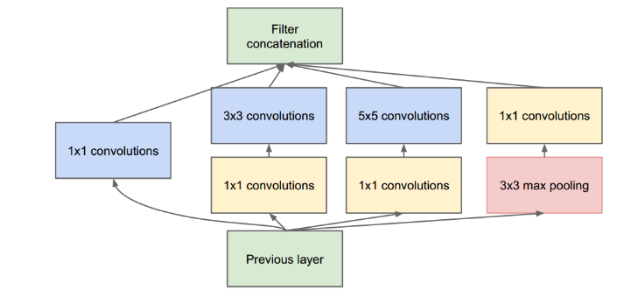
- V1:多尺度卷积核,1×1卷积操作减少参数量
- V2:在v1的基础上增加了BN层,使用2个3*3小卷积核堆叠替换5*5大卷积核
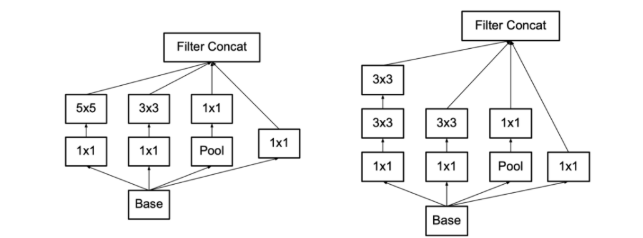
-
- 保持感受野范围的同时又减少了参数量,并且可以避免表达瓶颈,加深非线性表达能力
- V3:进行了卷积分解(将7*7分解成两个一维的卷积1*7和1*7,3*3也是一样1*3和3*1)和特征图降维
-
- 卷积分解
-
-
- 对称卷积分解:堆叠两层 3 × 3 的卷积核可以替代一层 5 × 5 的卷积核,堆叠三层 3 × 3 的卷积核替代一层 7 × 7 的卷积核
- 非对称卷积分解:任意 n × n 的卷积都可以通过 1 × n 卷积后接 n × 1 卷积来替代
-
-
-
-
- 在网络的前期使用这种分解效果并不好,在中度大小的feature map上使用效果才会更好。(对于mxm大小的feature map,建议m在12到20之间)
-
-
-
- 特征图降维
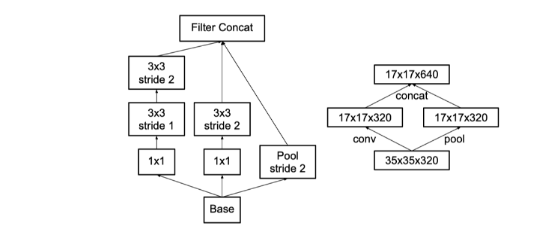
-
-
- 用卷积得到一半的特征图,池化得到一半的特征图,再进行拼接
-
- V4:在v3的基础上融合了Residual模块
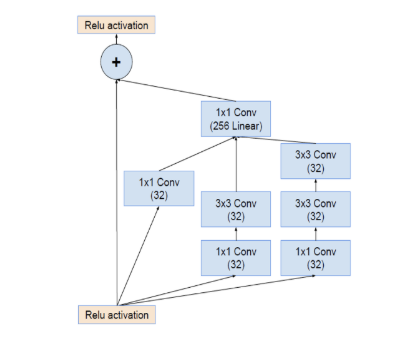
-
- 通过增加残差模块,跨层连接从而避免梯度消散等问题,同时能够使得多层语义信息融合
class Inception(nn.Module):
def __init__(self,in_c,c1,c2,c3,c4):
super(Inception,self).__init__()
self.p1 = nn.Sequential(
nn.Conv2d(in_c,c1,kernel_size=1),
nn.ReLU()
)
self.p2 = nn.Sequential(
nn.Conv2d(in_c,c2[0],kernel_size=1),
nn.ReLU(),
nn.Conv2d(c2[0], c2[1], kernel_size=3,padding=1),
nn.ReLU()
)
self.p3 = nn.Sequential(
nn.Conv2d(in_c, c3[0], kernel_size=1),
nn.ReLU(),
nn.Conv2d(c3[0], c3[1], kernel_size=5,padding=2),
nn.ReLU()
)
self.p4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3,stride=1,padding=1),
nn.Conv2d(in_c,c4,kernel_size=1),
nn.ReLU()
)
def forward(self, x):
p1 = self.p1(x)
p2 = self.p2(x)
p3 = self.p3(x)
p4 = self.p4(x)
return torch.cat((p1,p2,p3,p4),dim=1)
class GoogModel(nn.Module):
def __init__(self):
super(GoogModel,self).__init__()
self.b1 = nn.Sequential(
nn.Conv2d(3,64,kernel_size=7,stride=2,padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
)
self.b2 = nn.Sequential(
nn.Conv2d(64,64,kernel_size=1),
nn.Conv2d(64,192,kernel_size=3,padding=1),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
)
self.b3 = nn.Sequential(
Inception(192,64,(96,128),(16,32),32),
Inception(256,128,(128,192),(32,96),64),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
)
self.b4 = nn.Sequential(
Inception(480,192,(96,208),(16,48),64),
Inception(512,160,(112,224),(24,64),64),
Inception(512,128,(128,256),(24,64),64),
Inception(512,112,(144,288),(32,64),64),
Inception(528,256,(160,320),(32,128),128),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
)
self.b5 = nn.Sequential(
Inception(832,256,(160,320),(32,128),128),
Inception(832,384,(192,384),(48,128),128),
GlobalAvgPool2d()
)
self.feature = nn.Sequential(
self.b1,self.b2,self.b3,self.b4,self.b5
)
self.fc = nn.Sequential(
nn.Linear(3*3*1024,10) #这里使用的图像大小224*224的
)
def forward(self, x):
x = self.feature(x)
x = x.view(x.size(0),-1)
x = self.fc(x)
return x网络优缺点
- 优点:
-
- 代替人工选择卷积的类型或者确定是否要选择卷积核或者池化层
- 总体乘积参数比普通网络少,降低参数计算量
- 缺点:
-
- 非对称卷积在前期使用分解效果不好,在中度大小的feature map上使用效果更好
- 要平衡好深度和宽度,虽然同时增加有利于提高网络的性能,但是会增加计算的消耗