目录
四、思考:如何不借助url.parse方法,解析地址得到的结果和使用该方法相同?
后端的实现不仅仅只有JAVA、Python、PHP等语言,前端也有对应的语言,那就是
Node.js
。Node号称前端中的后端,作用和其他后端语言一样,可以搭建服务器、连接数据库、返回数据等。并且Node也有对应的框架,例如
Express、Remix
等等,能够快速搭建服务器,让程序员更加轻松。
******注意,在Node中,我们之前使用的部分JS方法是不存在的,例如:元素节点的获取、localStorage、location等等,如果使用了就会报错。
一、Node下载
在这就不多说如何下载了,不懂下载和安装的朋友自行去其他帖子查看,在这提供一篇个人认为比较详细的博客:
Node的下载与安装
。提醒一句,建议下载长期维护版本,不要下载新版,新版可能出现一些未知的Bug,到时候会比较麻烦。
二、模块的引入与js文件的运行
什么是模块?
模块其实就是一个个已经被他人封装好的js文件,能够直接被我们使用。在Node中,可以使用require来引入
全局模块、三方模块以及自定义模块
。
var 变量=require("模块路径")- 全局模块:就是下载Node时自带的模块;
- 三方模块:就是Node中没有,但已经被别人写好并开源在某个网站上的模块,我们可以通过某种方式去下载;
- 自定义模块:顾名思义,就是自己定义、封装的js文件,能够在其他文件内引入并使用;
如何启动已经引入模块的JS文件
?
终端进入保存着该文件的文件夹后,使用
node 文件名.js
运行文件。
![]()
我的app.js保存在某个文件夹中,进入该文件夹后直接使用上述命令运行指定文件。
三、Node常用全局模块
1、querystring模块
querystring模块作用是拆解参数,变为键值对形式。
例如:
var qs = require("querystring");
var url = "name=txl&age=18";
console.log(qs.parse(url)); //{ name: 'txl', age: '18' }
可以看出,
querystring.parse
根据&符号进行分割。
但该模块有很大的局限性:
只能解析传递的参数部分
,如果传递的是一个完整的url,那么解析的结果就不是我们想要的,所以不推荐使用该模块。
var qs = require("querystring");
var url = "https://localhost:8080?name=txl&age=18";
console.log(qs.parse(url));
/*
{
'https://localhost:8080?name': 'txl',
age: '18'
}
*/
2、url模块
url模块可以解析完整的网址,即
可以得到网址的各个部分
,例如:协议、域名、端口号、请求路径、请求参数等。
url中有很多的方法,但我们最常用的就是
url.parser()
。该方法能帮助我们得到上述的所有东西。至于其他方法,有兴趣的小伙伴自行查阅官方文档。
Node.js官方中文文档
。
语法:
url.parse(地址,true/false)
。
- 第一个参数就是要解析的地址;
-
第二个参数是一个布尔值,表示是否要调用
querystring.parse()
解析地址中的参数部分,true表示需要,false表示不需要,
默认是false
。
var url = require("url");
var urlstr = "https://localhost:8080/s/index.html?name=txl&age=18";
console.log(url.parse(urlstr, true));
/*
Url {
protocol: 'https:',
slashes: true,
auth: null,
host: 'localhost:8080',
port: '8080',
hostname: 'localhost',
hash: null,
search: '?name=txl&age=18',
query: [Object: null prototype] { name: 'txl', age: '18' },
pathname: '/s/index.html',
path: '/s/index.html?name=txl&age=18',
href: 'https://localhost:8080/s/index.html?name=txl&age=18'
}
*/
3、fs模块
fs模块:FileSystem,文件系统,提供了可以操作文件的API,例如:
读取、写入、追加
。
1)、写入
语法:
fs.readFile(“文件路径”,”可选参数:设置读取结果的字符编码”,回调函数)
,异步的读取文件。
-
第二个参数是可选参数
,如果不设置字符编码,那么读取的结果就是十六进制的; -
回调函数
有两个形参
,第一个是err,也就是当读取错误时,err才有值,否则为null,第二个是data,也就是读取的结果,所以是一个错误优先的回调函数;
const fs = require("fs");
// 读取文件
fs.readFile("./public/css/style.css", "utf8", (err, data) => {
if (err) throw err;
console.log(data)
});
2)、读取
语法:
fs.writeFile(“文件路径”,”要写入的内容”,”可选参数:设置字符编码”,回调函数)
,异步的写入文件,
会把原本的内容覆盖
。
fs.writeFile("./public/css/style.backup.css", "123456", () => {
console.log("写入完毕");
});注意:当文件的读取和写入同时存在于相同作用域时,会先执行写入方法,后执行读取方法。
3)、追加
语法:
fs.appendFile(“文件路径”,”要写入的内容”,”可选参数:设置字符编码”,回调函数)
,异步追加文件内容,不会把原本的内容覆盖。
fs.appendFile("./public/css/style.backup.css", "123456", () => {
console.log("追加完毕");
});常用模块肯定不止这些,但目前这三个(可用的就两个)其实已经够初学者使用了。
4、http模块
该模块用于
使用代码搭建服务器
。
前端的一切action、href、src,所有引入路径的地方,全都被node.js当作了是一个路由请求,解析请求,读取对应的文件给用户看,所以需要我们手动的搭建服务器,返回这些用户所需要的资源。
在我们开发时,搭建的都是本地服务器,即只有自己和同一局域网中的人才可以访问。
- 如果自己想要访问自己,打开浏览器,可以使用127.0.0.1(或者localhost)+端口号进行访问;
- 访问别人(前提:防火墙要关闭),需要别人把自己的ipv4地址给你,地址栏输入别人的ip+端口号进行访问;
使用http模块搭建服务器的固定步骤:
- 第一步:引入http模块
const http=require("http")-
第二步:使用
createServer方法
创建服务器
const a=http.createServer()-
第三步:使用
listen方法
为服务器指定一个端口进行监听
const http=require("http")
const a=http.createServer()
app.listen(端口号)-
第四步:使用
on方法
给服务器绑定请求事件
const http=require("http")
const a=http.createServer()
app.listen(端口号)
app.on("request",(req,res)=>{})-
app.on()的第一个参数
必须传入
“request”; -
app.on()的
第二个参数是一个回调函数
,该回调函数有两个参数,第一个参数是前端发来的请求,第二个参数是后端返回给前端的东西;-
req:request,保存着
请求对象
,有一个
req.url属性
,我们拿到这个属性值之后,就需要进行解析操作(url.parse方法),获取有用的信息; -
res:response,保存响应对象,提供了一个方法:
res.end(“要响应的东西”)
,可以把数据返回给前端;
-
5、http、fs、url的综合运用
// 引入http模块
var http = require("http");
var url = require("url");
var fs = require("fs");
// 创建服务器
var app = http.createServer();
// 为服务器绑定请求事件,回调函数内执行操作
app.on("request", (req, res) => {
/*
req:request,保存着请求对象,有一个req.url属性,
我们拿到这个属性值之后,就需要进行解析操作,获取有用的信息
*/
var urlobj = url.parse(req.url, true);
// 设置响应头,可以设置返回的编码格式
// res.writeHead(200, { "content-type": "text/plain;charset=utf-8" });
if (urlobj.pathname == "/" || urlobj.pathname == "/index.html") {
/*
res:response,保存响应对象,提供了一个方法:res.end("要响应的东西")
*/
fs.readFile("./public/html/index.html", (err, data) => {
res.end(data);
});
} else if (urlobj.pathname.match(/html/)) {
console.log(urlobj.pathname);
fs.readFile("./public" + urlobj.pathname, (err, data) => {
res.end(data);
});
} else if (urlobj.pathname.match(/jpg|png|webp|js|css/) != null) {
console.log(urlobj.pathname);
fs.readFile("./public" + urlobj.pathname, (err, data) => {
res.end(data);
});
}
});
// 为服务器设置监听的端口号
app.listen(3000, () => {
console.log("服务器启动成功");
});
四、思考:如何不借助url.parse方法,解析地址得到的结果和使用该方法相同?
咱就是说,直接上代码吧~注释什么的都有。
function UrlParse(url) {
// 以 ftp://www.baidu.com:443/index.html?name=dy&pwd=123123 为例
// 创建解析后保存值的空对象
var urlobj = {};
// 根据 : 截取字符串,第一个:前的是协议
if (url.indexOf(":") >= 8) {
// 如果获取到的第一个:下标超过了8,则说明网址不是从从浏览器复制的,默认添加协议http
urlobj.protocol = "http";
} else {
urlobj.protocol = url.substring(0, url.indexOf(":"));
// 在获取到协议后,应该将原本的路径改变,从第一个:开始,+3是因为:后还有两个/,要保存的后续路劲不需要 协议:// 这些东西
url = url.slice(url.indexOf(":") + 3); //此时的路径变为 www.baidu.com:443/index.html?name=dy&pwd=123123
}
// 提前设置好主机名
var hostname = null;
// 如果除去 协议:// 后,还存在 / ,表示请求的是当前网站下的子网页
if (url.indexOf("/") != -1) {
// 那么就截取到 / 之前就是主机名
hostname = url.slice(0, url.indexOf("/"));
} else {
// 没有 / 就代表只是www.baidu.com:443,即没有子路由,直接赋值
hostname = url;
}
// 根据 : 分割,即将域名和端口号分隔开,不论是否存在端口号,都至少能找到域名
var host = hostname.split(/:/);
urlobj.hostname = host[0];
// host[1]就是表示端口号,如果端口号不为false,则说明存在端口号
if (host[1]) {
urlobj.port = host[1];
} else if (urlobj.protocol == "http" && !host[1]) {
// 如果不存在端口号,但是协议为http的话,说明使用的是默认端口号80
urlobj.port = "80";
} else if (urlobj.protocol == "https" && !host[1]) {
// 如果不存在端口号,但是用的协议是https的话,则说明使用的是默认端口号443
urlobj.port = "443";
} else {
// 既不是http,也不是https,也没有端口号的话,表示的是使用的其他协议的默认端口,我这设置为/
urlobj.port = "/";
}
// 提前设置好urlobj中的路径属性
urlobj.pathname = null;
// 提前设置好参数对象
urlobj.query = {};
// 如果除去 协议:// 后,还存在 / ,表示请求的是当前网站下的子网页
if (url.indexOf("/") != -1) {
// 从 / 开始截取,即舍去主机名,只要子路由和参数部分
url = url.slice(url.indexOf("/")); //此时的url为:/index.html?name=dy&pwd=123123
// 根据?分割,不论是否存在?,都至少会出现一个数组,只是说当没有?时,该数组的长度为1,里面保存的是子路由,长度为2表示的是子路由和请求的参数。
urlobj.pathname = url.split("?")[0];
} else {
// 没有 / 代表没有子路由,所以设置pathname为null
urlobj.pathname = "null";
// 没有子路由就代表着没有参数,之前已经设置好了query为空对象了,所以可以直接返回解析好的路径对象urlobj
return urlobj;
}
// 进入到这说明是有子路由的,就判断有没有参数,如果url.split("?")[1]为true,就说明是有参数
if (url.split("?")[1]) {
// 有参数的话,就根据&进行分割
var queryarr = url.split("?")[1].split("&");
for (var i = 0; i < queryarr.length; i++) {
// 根据=分割,分割之后只会出现长度为2的数组
// 下标为0代表键
var key = queryarr[i].split("=")[0];
// 下标为1代表值
var item = queryarr[i].split("=")[1];
urlobj.query[key] = item;
}
}
return urlobj;
}
var urlobj = UrlParse(
"ftp://www.jd.com:443/index.html/a/b.html?name=dy&pwd=123123&age=18"
);
console.log(urlobj);
五、三方模块的下载
之前有提到过除了官方模块之外,还有第三方模块的存在。那么第三方模块是存在于哪里呢?所有的三方模块(这里说的是JavaScript的第三方模块)都存在于
npm官网
上。
那么如何下载三方模块?答案是通过npm命令。
1、npm命令的了解与使用
npm 为你和你的团队打开了连接整个 JavaScript 天才世界的一扇大门。它是世界上最大的软件注册表,每星期大约有 30 亿次的下载量,包含超过 600000 个
包(package)
(即,代码模块)。来自各大洲的开源软件开发者使用 npm 互相分享和借鉴。包的结构使您能够轻松跟踪依赖项和版本。–来自npm中文文档
说白了就是专门管理第三方模块的,用于模块的下载、安装、删除、更新、维护包的依赖关系 等等。
npm的使用方式需要在终端界面下才可以,windows系统可以使用
“win”键+R键,然后输入“cmd”回车打开终端
。

在打开终端后,需要使用cd命令进入到你想把三方模块下载到的文件夹中 ,cd命令不知道的朋友,可以自行查找相关资料,或者查看我这提供的别的博客:
Window系统 cd命令
。
或者直接在存储三方模块的文件夹中,在顶部地址栏输入cmd+回车也可以直接进入终端界面。


2、npm的常见命令
- npm下载命令:npm install 包名。
例如我们想要下载一个mysql包:

也可以使用简写形式:npm i 包名。
- npm删除命令:用于删除已经安装好的包,npm uninstall 包名

也可以使用简写形式:npm un 包名。
- npm更新命令:npm update 包名。

六、mongoose:连接与使用mongodb数据库
以mongodb数据库为例,通过使用mongoose对mongodb进行操作(增删改查等)。
注意:使用mongoose之前,要先下载mongoddb数据库才行:
Mongodb的下载与安装
。
后续内容会出现Promise的语法,我主要使用了then和catch回调,不了解的同学可以简单的理解一下:
then和catch都是回调函数:
- then只会在方法成功使用时被调用,并打印成功的结果;
- catch只会在方法调用失败是被调用,并能够输出错误结果;
xxxx().then(res=>{
//有一个res形参,如果方法调用后有返回值,那么res就能够接收这个返回值
console.log("then回调会在xxx方法执行成功时被调用")
}).catch(err=>{
//有一个err形参,如果方法调用后报错,那么errr就能够接收这个错误信息
console.log("catch回调会在xxx方法执行失败时被调用",err)
})
1、mongoose的下载
进入终端并进入指定文件夹后,使用
npm install mongoose
进行下载。

出现以上结果表示下载成功!
在文件夹中会多出一个名为:node_modules的目录,保存的就是下载的文件。
![]()
2、使用mongoose创建集合
- 创建一个JS文件,在其中引入mongoose模块。
const mongoose = require("mongoose");
1)、连接 mongodb
//在 MongoDB 中,不需要显示的去创建数据库,如果正在使用的数据库不存在,MongoDB 会自动创建
mongoose
.connect("mongodb://localhost/数据库名")
.then(() => {
console.log("数据库连接成功");
})
.catch((err) => {
console.log(err);
});
//这里的then和catch都是使用Promise封装后出现的回调函数,不了解Promise的可以去学习一下
//当然,这里的then和catch都不是必要的,可以省略不写
2)、创建集合
在mongodb中,数据表被叫做
集合
,数据被叫做
文档
。
创建集合分为两步:
-
设定集合规则:
设定规则的目的就是为了限制插入集合中的文档类型要相同,如果不同的话则会很混乱,到时候前端渲染会很麻烦
。通过mongoose中的Schema方法,传入一个对象,该对象就是集合的规则。
const cursorSchema=new mongoose.Schema({
name:String, //name列为字符串类型
author:String, //author列为字符串类型
isPublished:Boolean //isPublish列为布尔类型
})- 创建集合并应用规则:使用model方法应用集合规则
const Course=mongoose.model("Course",courseSchema)model方法可以传入三个参数:
- 第一个参数:模型名,后面就是根据模型名来对数据库进行操作,并且建议将模型名和变量名取相同的名字;
- 第二个参数:就是创建的规则变量名;
- 第三个参数:要将规则应用到哪个集合上。可以不填,不填的话就默认是模型名的小写复数形式,如courses;
2、创建集合规则的另外一些语法
集合规则也可以叫做
mongoose验证
。上面说到创建集合规则时,只是简单的限制了集合中每一列的数据类型,其实还有一些更加高级的限定,当要给某一项设置多个验证时,就要
使用对象写法
了。
1)、必填字段
语法:
required:[true/false,’文本’]
- 第一个参数:表示是否必填,true为必填,false表示不是必填项,不过一般设置required就是为了设置成必填;
- 第二个参数是自定义错误信息,当没有传入该字段时,会显示你在这设置的错误信息;
const Schema=mongoose.Schema({
//设置多项验证,采用对象的写法
name:{
type:String, //设置数据类型
required:[true,"name不能为空!"]
}
})
2)、限制字符串的最小长度和最大长度
语法:
-
最小长度:
minlength:[num,”文本”]
; -
最大长度:
maxlength:[num,”文本”]
;
注意:
- 第一个参数是Number类型的数字;
- 第二个参数是自定义错误信息;
const Schema = mongoose.Schema({
name: {
type: String,
required: [true, "name不能为空"],
// 最小长度
minLength: [2, "name不能小于2个字符"],
// 最大长度
maxlength: [5, "name不能大于5个字符"]
},
});
3)、去除两边的空格
有时候前端传过来的数据没有做数据处理,比如去除数据左右的空格,那么这时候就可以通过集合规则来实现最后的一道防线。
语法:
trim:true/false
;
const Schema = mongoose.Schema({
title: {
type: String,
required: [true, "标题不能为空"],
// 最小长度
minLength: [2, "标题不能小于2个字符"],
// 最大长度
maxlength: [5, "标题不能大于5个字符"],
// 去除字符串两边空格
trim: true,
},
});
4)、限制数字的最大和最小值
之前的
maxlength和minlength都是针对字符串类型的数据
,数值类型的数据有专门的限制属性。
语法:
-
min:[num,”文本”]
; -
max:[num,”文本”]
;
注意:
- 第一个参数是一个数值类型的参数;
- 第二个参数是自定义错误文本;
const Schema = mongoose.Schema({
price: {
type: Number,
// 最小长度
min: [2, "价格不能低于2元"],
// 最大长度
max: [11, "价格不能高于11元"]
},
});
5)、设置默认值
如果没有给某一项传值,那么可以设置一个默认值,用于解决数据缺失问题。
语法:default:xxx
const Schema = mongoose.Schema({
publishDate: {
type: Date,
//default 默认值
default: Date.now,
}
});
6)、指定该字段能够拥有的值
可以通过enum属性,设置当前字段能够有哪些值,如果传入的值不在列举的这些值当中,那么就会报错。
语法:enum:{values:[“值1″,”值2″,”值3″…],message:”文本”}
注意:
- enum是一个对象;
-
可以设置两个属性:
- 第一个属性是values:是一个数组类型的数据,用于列举当前字段能够传入哪些值,传入不在values中的值则会报错 ;
- 第二个属性是message:也就是自定义报错信息;
const Schema = mongoose.Schema({
category: {
type: String,
// enum 只能是指定的值,即可以列举去当前字段的可以拥有的值
enum: {
values: ["html", "css", "javascript", "vue", "react", "node", "mongoose"],
message: "请输入正确的分类",
},
}
})
7)、自定义验证
除了可以设置已经规定好的验证之外,还可以设置自定义验证,用自己的想法去验证文档是否是自己想要的 。
语法:
validate:{
validator:(v)=>{
return 要执行的操作
},
message:"文本"
}注意:
- validate是一个对象;
-
validate中的validator是一个函数类型的属性;
- validator有一个形参v,v表示要被验证的值;
-
validator中写验证v的代码,如
v&&v>10
; - 返回值是一个布尔值;
- message就是自定义错误信息;
const Schema = mongoose.Schema({
// 自定义验证信息
author: {
type: String,
validate: {
validator: (v) => {
// 返回布尔值,true验证成功,false验证失败,v就是要被验证的值
// v不为空且长度大于4
return v && v.length > 4;
},
// 自定义错误信息
message: "作者名称不能为空且长度大于4",
},
},
});注意:以上部分方法的第二个参数不是必须的,可以只传第一个参数。如果只传一个参数的话,那就不需要写中括号的形式了。
const Schema = mongoose.Schema({
title: {
type: String,
required: true,
// 最小长度
minLength:2,
// 最大长度
maxlength:5,
},
});
3、对文档的操作(增删改查)
1)、创建文档
创建文档,其实就是向数据库中插入文档,常用方法有两种:
方法一:创建实例对象并调用save方法
方法一分两步:
- 创建集合实例,集合就是在应用集合规则时创建的集合;
const Course=mongoose.model("Course",courseSchema)- 调用实例下的save方法将文档保存到集合中;
// 创建集合实例,并在构造函数中传入对象,对象的内容就是要插入的文档
const course = new Course({
name: "Node.js course",
author: "xxxx",
isPublished: true,
});
//将数据保存到数据库中
course.save();
方法二:调用集合模型下的create方法
给create方法传入一个对象,对象中的内容就是要插入的文档。
Course.create({
name: "HTML",
author: "xxxx",
isPublished: false,
})
注意,
这里的Course不是实例对象
,是使用集合规则时的那个变量名,也就
是创建实例对象时的那个构造函数
。(实例对象按照规定一般首字母是小写的,如果是构造函数的话,首字母要大写。)
2)、查找文档
-
find方法
。
Course.find().then((result) => {
console.log(result);
});
find方法无论找到几条文档,
返回的都是一个数组
,如果没有返回的文档,则是一个空数组。
-
findOne方法
Course.findOne();返回一条文档,默认返回当前集合中的第一条文档。也可以给条件。
-
可以指定范围查找文档
Course.find({ age: { $gt: 18, $lt: 50 } }).then((result) => {
console.log(result);
});
使用表达式查询某一范围的文档,find方法内传入一个对象类型的参数,对象内表示要根据哪一项来查找。
$gt表示大于,$lt表示小于
。
-
可以查找是否包含指定值
Course.find({ hobies: { $in: ["足球"] } }).then((result) => {
console.log(result);
});同样的,也是在find方法内传入一个对象,$in表示要包含什么值。
-
查看指定字段
Course.find()
.select("name author -_id")
.then((result) => {
console.log(result);
});
在find方法后使用
.select
方法,传入一个字符串类型的参数,字符串内表示想查看哪些字段,各字段使用空格隔开。字段前面加上一个
短横线(-)
表示不想查看该字段,即最后的结果不会出现_id字段的值。
-
将查找出来的结果升序/降序排列
Course.find()
.sort("age")
.then((result) => {
console.log(result);
});
在find方法后使用
.sort
方法就可以实现排序,sort方法中传入一个字符串类型的参数,表示要根据哪个字段进行排序,默认是升序排序;
如果想要降序排序,就在传入的字段前加上
一个负号(-)
。
Course.find()
.sort("-age")
.then((result) => {
console.log(result);
});此时的结果就是降序排序了。
-
跳过指定数量的文档以及限制查询文档结果的数量
Course.find()
.skip(2)
.limit(2)
.then((result) => {
console.log(result);
});- skip方法是跳过指定数量的文档;
- limit方法是限制查找的结果为指定数字;
-
一般这两个方法搭配使用,进而实现
数据的分页效果
;
3)、删除文档
-
findOneAndDelete()
Course.findOneAndDelete({}).then((result) => {
console.log(result);
});
该方法是
找到一条文档并删除
,并返回删除的文档,then的形参接收的就是被删除的文档。如果不使用条件,那么默认找到的是第一条文档。
-
deleteMany()
Course.deleteMany({}).then((result) => {
console.log(result);
});返回的结果是一个对象,表示删除了几条文档。同样的可以传入条件,根据条件删除多条文档。
4)、更新文档
-
updateOne()
Course.updateOne({ 查询条件 }, { 要修改的值 }).then((result) => {
console.log(result);
});该方法只会找到符合条件的第一个文档并修改。
传入两个参数,每个参数都是对象类型的:
- 第一个参数:是指定查找的条件;
- 第二个参数:是要修改值;
Course.updateOne({ name: "Node.js基础" }, { name: "Python" }).then((result) => {
console.log(result);
});-
updateMany()
Course.updateMany({ 查询条件 }, { 要修改的值 }).then((result) => {
console.log(result);
});同updateOne,只是该方法是查找多个结果并修改。
Course.updateMany({}, { name: "Python" }).then((result) => {
console.log(result);
});
七、模块化开发
本篇博客的最开始就提到过一个概念:模块。现在正式的说一下模块
在程序开发中
的概念:
为完成某一功能所需的一段程序或子程序;或指能由编译程序、装配程序等处理的独立程序单位;或指大型软件系统的一部分。
个人理解:
也就是将我们所写的部分代码封装成一个独立的JS文件,该文件能够被其他文件引入并使用
。
那么什么是模块化开发?
- 在之前我们使用JS代码写页面功能时,都是讲所有的代码写在一个JS文件中,当代码量很多时,就不便于查看和维护;
-
模块划开发就是
将各个功能部分的代码分别封装成不同的JS文件
,然后
引入同一个主JS文件中
,当某一部分功能出现Bug时,就可以直接找到代码的位置了;
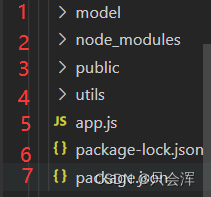
1、一个简单的模块开发项目目录
-
文件夹1
:数据库相关文件,有的数据库代码只能执行一次,如果多次执行服务器会报错,所以需要单独的建立JS文件保存相关代码; -
文件夹2
:该文件夹是使用npm命令
第一次下载
三方模块后会
自动出现的文件夹
,里面保存着已下载模块; -
文件6和7
:这两个文件是
第一次使用
npm命令下载三方模块时
自动出现的文件
,保存着一些配置信息,这里不详细说明; -
文件夹3
:保存着前端的相关文件,例如HTML、CSS、JS等; -
文件夹4
:保存着一些
自定义工具模块
,例如手机号的正则验证等;
2、模块的导入和导出
导入很简单:require(“要导入模块的路径”)。如果是全局模块,直接写模块名就好;
导出自定义模块:
-
exports.方法名=方法名
; -
module.exports={方法1,方法2…}
; - 其实exports和module.exports是同一个,但如果两个导出的内容发生了冲突,那么以module.exports为准;
当然模块的导入和导出形式不止这一种,还有其他方式,有兴趣的自行去了解。
根据前面的所有内容,已经可以实现:
后端连接数据库、对数据库进行操作、将数据返回给前端
,但还有一个点没有实现,那就是
前端如何主动的向后端索要数据?
八、AJAX的使用
前端要想主动的找后端要数据,那就需要通过发送网络请求才可以,这时候ajax就闪亮登场了。
1、什么是AJAX
ajax全名
async javascript and XML
,是
能够实现前后端交互
的能力的途径,也是我们客户端
给服务端发送消息以及接受响应
的工具,是一个
默认异步
执行机制的功能。
2、AJAX的优缺点
优点
:
-
不需要插件的支持,原生 js 就可以使用;
-
用户体验好(不需要刷新页面就可以更新数据);
-
减轻服务端和带宽的负担;
缺点
:
-
搜索引擎的支持度不够,因为数据都不在页面上,搜索引擎搜索不到;
3、AJAX的基本使用
-
在 js 中有内置的构造函数来创建 ajax 对象
-
创建 ajax 对象以后,我们就使用 ajax 对象的方法去发送请求和接受响应
1)、创建一个AJAX对象
// IE9及以上
const xhr = new XMLHttpRequest()
// IE9以下
const xhr = new ActiveXObject('Mricosoft.XMLHTTP')
2)、配置连接信息
const xhr = new XMLHttpRequest()
// xhr 对象中的 open 方法是来配置请求信息的
// 第一个参数是本次请求的请求方式 get / post / put / ...
// 第二个参数是本次请求的 url
// 第三个参数是本次请求是否异步,默认 true 表示异步,false 表示同步
// xhr.open('请求方式', '请求地址', 是否异步)
xhr.open('get', './data.php')
3)、发送请求
const xhr = new XMLHttpRequest()
xhr.open('get', './data.php')
// 使用 xhr 对象中的 send 方法来发送请求
xhr.send()
4、一个基本的AJAX请求
-
一个最基本的 ajax 请求就是上面三步
-
但是光有上面的三个步骤,我们确实能把请求发送的到服务端
-
如果服务端正常的话,响应也能回到客户端
-
但是我们拿不到响应
-
如果想拿到响应,我们有两个前提条件
-
本次 HTTP 请求是成功的,也就是我们之前说的 http 状态码为 200 ~ 299
-
ajax 对象也有自己的状态码,用来表示本次 ajax 请求中各个阶段
-
1)、ajax状态码
-
ajax 状态码 –
xhr.readyState
-
是用来表示一个 ajax 请求的全部过程中的某一个状态
-
readyState === 0
: 表示未初始化完成,也就是
open
方法还没有执行 -
readyState === 1
: 表示配置信息已经完成,也就是执行完
open
之后 -
readyState === 2
: 表示
send
方法已经执行完成 -
readyState === 3
: 表示正在解析响应内容 -
readyState === 4
: 表示响应内容已经解析完毕,可以在客户端使用了
-
-
这个时候我们就会发现,当一个 ajax 请求的全部过程中,只有当
readyState === 4
的时候,我们才可以正常使用服务端给我们的数据 -
所以,配合 http 状态码为 200 ~ 299
-
一个 ajax 对象中有一个成员叫做
xhr.status
-
这个成员就是记录本次请求的 http 状态码的
-
-
两个条件都满足的时候,才是本次请求正常完成
2)、readyStateChange
-
在 ajax 对象中有一个事件,叫做
readyStateChange
事件 -
这个事件是专门用来监听 ajax 对象的
readyState
值改变的的行为 -
也就是说只要
readyState
的值发生变化了,那么就会触发该事件 -
所以我们就在这个事件中来监听 ajax 的
readyState
是不是到 4 了
const xhr = new XMLHttpRequest()
xhr.open('get', './data.php')
xhr.send()
xhr.onreadyStateChange = function () {
// 每次 readyState 改变的时候都会触发该事件
// 我们就在这里判断 readyState 的值是不是到 4
// 并且 http 的状态码是不是 200 ~ 299
if (xhr.readyState === 4 && /^2\d{2}$/.test(xhr.status)) {
// 这里表示验证通过
// 我们就可以获取服务端给我们响应的内容了
}
}
3)、xhr.onload事件
该事件只会在
readyState
为4时触发,相比于
readystatechange
,可以直接判断status。
<body>
<script>
const xhr=new XMLHttpRequest()
xhr.open("get","./data.php")
xhr.send()
xhr.onload=function(){
console.log(xhr.readyState)
}
</script>
</body>
4)、responseText
-
ajax 对象中的
responseText
成员 -
就是用来记录服务端给我们的响应体内容的
-
所以我们就用这个成员来获取响应体内容
const xhr = new XMLHttpRequest()
xhr.open('get', './data.php')
xhr.send()
xhr.onreadyStateChange = function () {
if (xhr.readyState === 4 && /^2\d{2}$/.test(xhr.status)) {
// 我们在这里直接打印 xhr.responseText 来查看服务端给我们返回的内容
console.log(xhr.responseText)
}
}
5、AJAX案例
<body>
<div id="div"></div>
<script>
// http://xiongmaoyouxuan.com/api/tabs
//创建ajax实例化对象
const xhr = new XMLHttpRequest();
//配置请求信息
xhr.open("get", "http://xiongmaoyouxuan.com/api/tabs");
//发送请求
xhr.send();
//请求完成后
xhr.onload = function () {
//获取到的数据是JSON格式字符串,需要JSON.parse解析为JSON格式的数据
var resObj = JSON.parse(xhr.responseText).data;
render(resObj);
};
function render(obj) {
console.log(obj);
//获取到的obj.lis是一个数组,所以通过map将数组内的每一项都进行模板字符串操作并用新的变量接收
var str = obj.list.map(
(item) =>
`<li>
<img src="${item.imageUrl}">
<div>${item.name}</div>
</li>`
);
console.log(str);
div.innerHTML = str.join("");
}
</script>
</body>
6、使用 AJAX 发送请求时携带参数
-
我们使用 ajax 发送请求也是可以携带参数的
-
参数就是和后台交互的时候给他的一些信息
-
但是携带参数 get 和 post 两个方式还是有区别的
1)、发送一个带有参数的 get 请求
get 请求的参数就直接在 url 后面进行拼接就可以。
const xhr = new XMLHttpRequest()
// 直接在地址后面加一个 ?,然后以 key=value 的形式传递
// 两个数据之间以 & 分割
xhr.open('get', './data.php?a=100&b=200')
xhr.send()
2)、发送一个带有参数的 post 请求
post 请求的参数是携带在请求体中的,所以不需要再 url 后面拼接。
const xhr = new XMLHttpRequest()
xhr.open('get', './data.php')
// 如果是用 ajax 对象发送 post 请求,必须要先设置一下请求头中的 content-type
// 告诉一下服务端我给你的是一个什么样子的数据格式
xhr.setRequestHeader('content-type', 'application/x-www-form-urlencoded')
// 请求体直接再 send 的时候写在 () 里面就行
// 不需要问号,直接就是 'key=value&key=value' 的形式
xhr.send('a=100&b=200')
九、总结
-
Node是前端中的后端语言,能够帮助我们成为全栈开发工程师,实现前端与后端的交互;
-
前端只要做出这些行为:地址栏输入地址并按下回车、src、href、form表单提交等,后端都会认为是在发起一个请求,然后进行响应,返回对应的资源;
-
后端通过http模块搭建好服务器,通过请求事件中回调函数的两个形参来进行请求的获取与响应:
1)、req:能够获取请求的路径以及参数等;
2)、res:能够将数据返回给前端;
-
前端通过创建ajax请求,向后端主动索要数据;
-
日后建议使用模块化的开发形式,保证各功能块之间的代码独立,以便日后维护;