目录
YOLOv2的第二个改进在网络中加入了Batch Normalization
YOLOv2的第三个改进是增加了HighResolution Classifier
YOLOv2的第四个改进是Multi-ScaleTraining
大家好,我是羽峰,今天要和大家分享的是YOLOv2算法。YOLOv2算法是在YOLOv1算法的基础上进行改进的,YOLOv1算法主要存在两个缺点:一是YOLOv1定位不准确,另一个是基于Region proposal的方法的召回率相对较低,因此YOLOv2主要是在这两方面做了一些改进。这个视频主要讲YOLOv2 的主要改进方案,尤其重点要讲述Anchor,Anchor是目标检测算法最重要的一个机制。希望通过本视频的讲解,各位朋友可以对YOLOv2以及Anchor有个更深入的了解。
同时可以关注公众号“羽峰码字”,或者b站“羽峰码字”,浏览更多内容哈。
YOLOv2的第一个改进就是网络的改进
使用DarckNet19代替了YOLOv1的GoogLeNet网络,这里主要改进是去掉了全连接层,用卷积和softmax进行代替。
YOLOv2的第二个改进在网络中加入了Batch Normalization
使用Batch Normalization对网络进行优化,让网络提高了收敛性,同时还消除了对其他形式的正则化(regularization)的依赖。
YOLOv2的第三个改进是增加了HighResolution Classifier
具体做法是:首先在448×448的全分辨率下在ImageNet上微调分类网络的10个epoch。这使网络有时间调整其过滤器,使其在更高分辨率的输入上更好地工作。然后,我们根据检测结果对网络进行微调。这种高分辨率分类网络使我们的mAP几乎提高了4%。
YOLOv2的第四个改进是Multi-ScaleTraining
让网络在不同的输入尺寸上都能达到一个很好的预测效果,同一网络能在不同分辨率上进行检测。当输入图片尺寸比较小的时候跑的比较快,输入图片尺寸比较大的时候精度高。
YOLOv2的第五个改进是加入了Anchor机制
这个是最重要的一个改进,也是本视频将重点讲解的一个改进。首先我们要了解什么是Anchor机制,Anchor首先要预设好几个虚拟框,在用回归的方法确定最终的预测框,在YOLOv2中,使用K-means算法来生成Anchor bbox,如图1所示,当k=5时,模型的复杂度与召回率达到了一个比较好的平衡,所以YOLOv2使用了5个Anchor bbox 。

图1
我们将YOLOv1的输出与YOLOv2输出进行对比,如图2所示。YOLOv1是的输出7*7*30的多维向量,其中7*7是分辨率,对原图进行了7*7的分割,每个网格对应一个包含30个参数的向量,每个向量中包含两个bbox,每个bbox中包含5个向量,分别是bbox的质心坐标(x,y)和bbox的长和宽,还有一个bbox的置信度,剩下20个则是类别概率。这个如果不懂可以看一下我之前的文章,
YOLO算法之YOLOv1精讲
。而YOLOv2对此进行了修改,YOLOv2输出的是13*13*5*25的一个多维向量,其中13*13是分辨率,也就是说网络将输入图片分成了13*13的网格,每一个网格对应一个包含5*25=125个参数的一维向量,其中5代表5个Anchor bbox,每个Anchor bbox中包含25个参数,分别是bbox的质心坐标(x,y)和bbox的长和宽,还有一个bbox的置信度,剩下20个则是类别概率。这样的好处是YOLOv2可以对一个区域进行多个标签的预测,比如一个“人”的目标物体,他可以属于“人”这个标签,也可以属于“男”或者“女”这个标签,也可以是“老师”,“学生”或者“职工”等这些标签,而YOLOv1只能预测目标物体的一个类别。这里所做的最主要的改变是:bbox的四个位置参数的损失函数计算方法发生了改变。
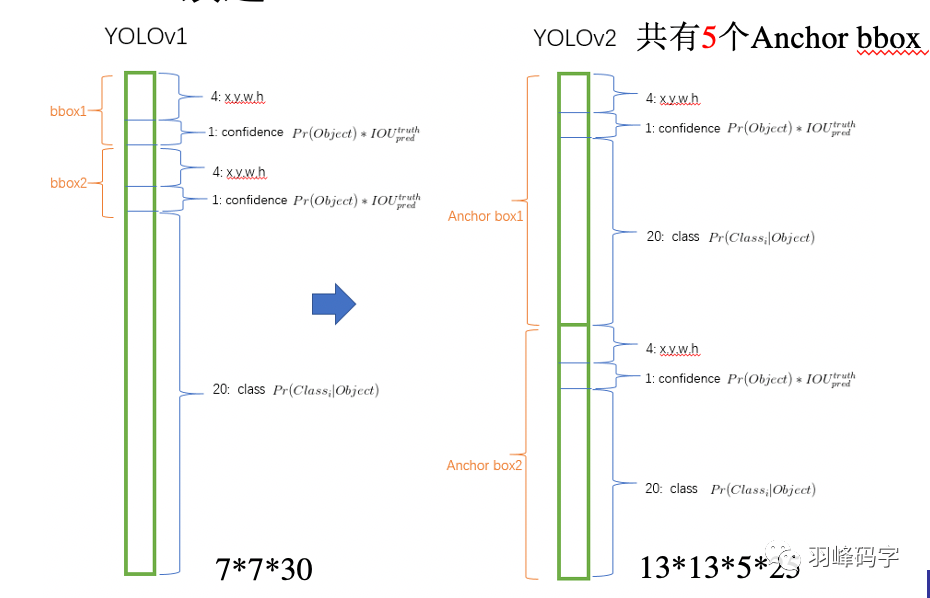
图2
首先我们来认识一下Anchor bbox, Predicated bbox以及Ground truth bbox 三者之间的关系。如图3所示,红色框代表了Anchor bbox,蓝色框代表了 Predicated bbox,绿色框则代表了Ground truth bbox。我们希望的是Anchor bbox 接近于Ground truth bbox,但Anchor bbox是预先设定好的,不可以更改。但Anchor bbox可以生成不同的Predicated bbox,所以我们将我们目标转化为:Predicated bbox更接近于Ground truth bbox, 将这个目标转化为数学表达式就是
f(x)
,具体如图所示,那么我们的目标就变成了数学上的
tp
更加接近于
tg
。式子中都做了归一化,防止大物体干扰整个计算结果。

图3 三者之间关系
其次我们要了解一下坐标转换的概念,YOLOv1的坐标是相对于整个图像的,而YOLOv2的坐标是相对于每个网格的,那如何得到相对网格的这个坐标呢,又是如何计算loss值的呢?
如图4所示,最开始我们会生成Anchor bbox,这时候的这个bbox是相对于整个图像来说的,所以此时我们要进行归一化,归一到[0,1]之间。YOLOv2的分辨率是13*13,所以我们要将这个[0,1]之间的坐标乘上13,使得bbox的坐标是相对于13个网格的,此时坐标范围在[0,13]之间。此时我们在进行归一化操作,使得此时的坐标是相对于单独一个网格的,归一化计算公式是
xf = x-i, yf = y-j, wf = log(w/anchors[0]),hf = log(h/anchors[1]),
这里我们可以举个粒子,加入
x = 9.6
(
x
的范围是[0,13]),那么此时的
i
是
x
的整数部分,也就是
i = 9
, 所以
xf
= 0.6
,此时这个
0.6
就是相对于轴向第10个网格的x轴坐标。

图4 坐标变换
然后就是最后的loss 计算,如图5所示,图片中间的公式就是YOLOv2loss的计算公式,这个计算公式是相对于网格的,而其对应的f(x)则是相当于整个图像的。网络会计算得到δ(tx),δ(ty),其中δ是sigmoid函数,将网络输出归一化到[0,1]之间,这样就会得到相对于某个网格的质心位置,加上该网格相对于整个13*13网格的偏移值,就会得到预测bbox的质心位置,高和宽,调整这个值,使其更加接近于真实的bbox。

图5 总结