recall
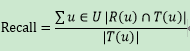
为用户u推荐N个物品(记为R(u)),令用户在测试集上喜欢的物品的集合为T(u)
,然后计算召回率。召回率描述还有多少比例的用户-物品评分记录包含在最终的推荐列表中。所以T(u)是测试集的总长度。
precison
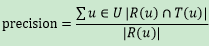
准确率描述最终的推荐列表中有多少比例是发生过的用户-物品评分记录。
论文中实例总结,这篇文章将持续更新。
- GRU4REC中,计算TOP 20的召回率时,每个session的target只有一个,所以T(u)的长度是1,意思为当取推荐的前20个数值时,(也就是softmax的结果取前20个概率对应的item),中是否包含了这个target,如果包含了就记为1。
def get_recall(indices, targets):
""" Calculates the recall score for the given predictions and targets
Args: indices (Bxk): torch.LongTensor. top-k indices predicted by the model. targets (B): torch.LongTensor. actual target indices.
Returns: recall (float): the recall score """
targets = targets.view(-1, 1).expand_as(indices)
hits = (targets == indices).nonzero()
if len(hits) == 0:
return 0
n_hits = (targets == indices).nonzero()[:, :-1].size(0)
recall = float(n_hits) / targets.size(0)
return recall
计算时,先计算一个batch的recall,最后对一个epoch的recall取平均。
也可以将一个epoch所有的正确的项加起来,除以一个epoch的也就是总的test的长度,计算recall。
- Caser中 为用户生成一个推荐列表N,然后使用每个用户后百分之20的数据作为测试集数据,最后使用预测列表与测试列表进行准确率等的计算,完全符合公式的定义。只要包含即可,不用 按照顺序来


def _compute_precision_recall(targets, predictions, k):
pred = predictions[:k]
num_hit = len(set(pred).intersection(set(targets)))
precision = float(num_hit) / len(pred)
recall = float(num_hit) / len(targets)
return precision, recall
def evaluate_ranking(model, test, train=None, k=10):
"""
Compute Precision@k, Recall@k scores and average precision (AP).
One score is given for every user with interactions in the test
set, representing the AP, Precision@k and Recall@k of all their test items.
Parameters ----------
model: fitted instance of a recommender model The model to evaluate.
test: :class:`spotlight.interactions.Interactions` Test interactions.
train: :class:`spotlight.interactions.Interactions`, optional Train interactions. If supplied, rated items in interactions will be excluded.
k: int or array of int, The maximum number of predicted items
"""
test = test.tocsr()
if train is not None:
train = train.tocsr()
if not isinstance(k, list):
ks = [k]
else:
ks = k
precisions = [list() for _ in range(len(ks))]
recalls = [list() for _ in range(len(ks))]
apks = list()
for user_id, row in enumerate(test):
if not len(row.indices):
continue
predictions = -model.predict(user_id)
predictions = predictions.argsort()
if train is not None:
rated = set(train[user_id].indices)
else:
rated = []
predictions = [p for p in predictions if p not in rated]
targets = row.indices
for i, _k in enumerate(ks):
precision, recall = _compute_precision_recall(targets, predictions, _k)
precisions[i].append(precision)
recalls[i].append(recall)
apks.append(_compute_apk(targets, predictions, k=np.inf))
precisions = [np.array(i) for i in precisions]
recalls = [np.array(i) for i in recalls]
if not isinstance(k, list):
precisions = precisions[0]
recalls = recalls[0]
mean_aps = np.mean(apks)
return precisions, recalls, mean_aps
- Next Item Recommendation with Self-Attention


该论文中的计算方法与GRU4REC的计算方法类似,在计算HR@50 的时候,也是对于生成的rank50中是否有目标target进行计算,如果有,则为1,没有则为0
计算mrr的意思是衡量这个模型排序排的怎么样,直观地说,在实践中,将groundtruth项排列得越高越好。MRR关心groundtruth项的位置,并计算放置groundtruth项的位置的倒数。
`
版权声明:本文为qq_40210472原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。