什么是UDF,UDAF,UDTF函数
UDF简单来说就是一对一,一个输入,一个输出
UDAF:User- Defined Aggregation Funcation;用户定义聚合函数,可对多行数据产生作用;也是聚合函数;
UDTF:User-Defined Table-Generating Functions,用来解决输入一行输出多行,但不怎么使用,使用explode,即用户定义表生成函数就可满足需求;
使用Java实现UDF
以实现
string_upper(LETTER) = letter
为例
java端
1,创建maven工程,导入相关依赖
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-common</artifactId>
<version>1.1.0</version>
</dependency>
build替换成这个
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>cn.kgc.serveris.MyUDF</mainClass><!--这里改成自己的启动位置(主类位置)-->
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
2,创建类,继承udf类,实现
evaluate
方法
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
/**
* @Author yanglitian
* @Date 2020/7/13
* @Description
*/
public class Str2Lower extends UDF {
public Text evaluate(final Text s) {
if (s == null) {
return null;
}
return new Text(s.toString().toUpperCase());
}
}
3,打成jar包,上传至虚拟机
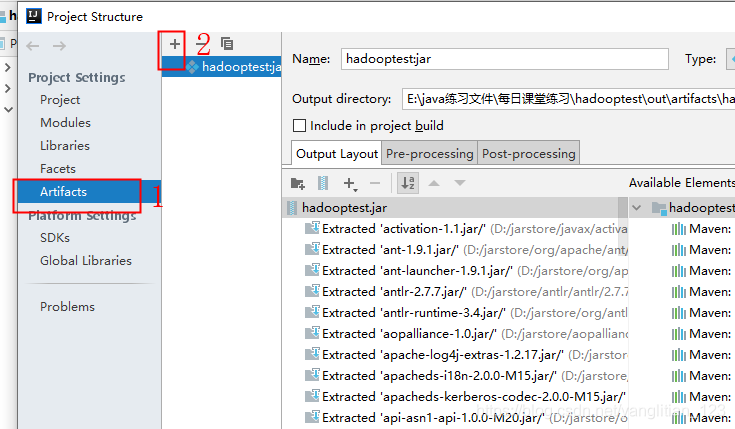
在界面点击Build–>build artifacts–>build
linux端
1,下载zip,删除jar包部分内容
[root@hadoop151 ~]# yum install -y zip
[root@hadoop151 ~]# zip -d hadooptest.jar 'META-INF/.SF' 'META-INF/.RSA' 'META-INF/*SF'
zip warning: name not matched: META-INF/.SF
zip warning: name not matched: META-INF/.RSA
deleting: META-INF/DUMMY.SF
2,添加jar包到hive
[root@hadoop151 ~]# hdfs dfs -mkdir /hdfs
[root@hadoop151 ~]# hdfs dfs -put /root/hadooptest.jar /hdfs/
3,创建永久函数
0: jdbc:hive2://localhost:10000> use demo;
0: jdbc:hive2://localhost:10000> CREATE FUNCTION str_upper AS 'cn.kgc.mr.hiveudf.Str2Lower' USING JAR 'hdfs://192.168.211.151:9000/hdfs/hadooptest.jar';
测试:
0: jdbc:hive2://localhost:10000> select str_upper("WWWbbb");
INFO : OK
+---------+--+
| _c0 |
+---------+--+
| WWWBBB |
+---------+--+
1 row selected (0.101 seconds)
4,创建临时函数()
和上面一样,但是不需要把jar包放到hdfs上,在虚拟机上即可
hive> add jar /root/hadooptest.jar;
hive> create temporary function function2 as 'cn.kgc.mr.hiveudf.Str2Lower';
使用Java实现UDAF
import org.apache.hadoop.hive.ql.exec.UDAF;
import org.apache.hadoop.hive.ql.exec.UDAFEvaluator;
import org.apache.hadoop.hive.ql.exec.UDAFEvaluatorResolver;
import org.apache.hadoop.io.Text;
/**
* @Description 实现聚合,把同意分组的项,用逗号连接成字符串
*/
public class MyUDAF extends UDAF {
public static class AllName implements UDAFEvaluator { //实现UDAFEvaluator接口,重写方法
private Text result;
@Override
public void init() { //接收输入参数
result = null;
}
public boolean iterate(Text txt){ //收到数据,遍历数据,存入result中,(在map中执行)
if(txt==null){
return false;
}
if(result==null){
result= new Text(txt.toString());
}else {
result=new Text(result.toString()+","+txt.toString());
}
return true;
}
public Text terminatePartial(){ //以持久化的方式返回部分集合结果
return result;
}
public boolean merge(Text txt){ //在reduce执行,用于最后的聚合
return iterate(txt);
}
public Text terminate(){ //返回最终结果
return result;
}
}
}
版权声明:本文为yanglitian_123原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。