HTTP请求
当我们通过DNS解析获取到对应的服务IP地址,接下来就可以进行HTTP请求了。
那么什么是HTTP请求呢?HTTP请求本质上
是把HTTP报文通过被包裹在TCP报文内的方式,发送到服务端指定端口的过程。
TCP概念我们之后会说,这里首先简单的介绍一下HTTP请求的基础概念:
请求报文
和
响应报文
请求报文
当我们发出一个HTTP请求时,我们的HTTP请求可以用下图来概括
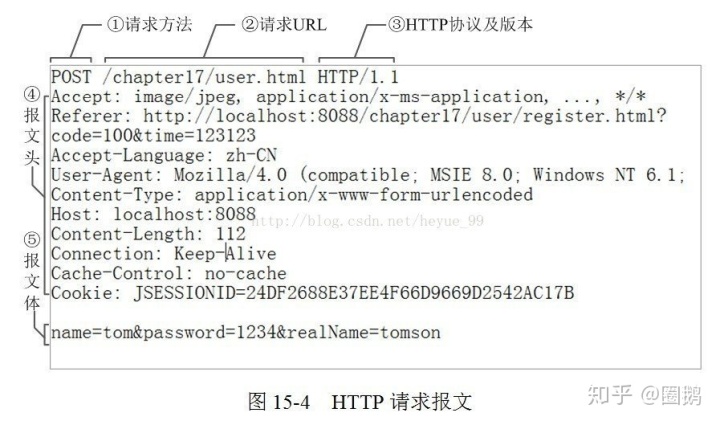
其中1,2,3为请求行,4为请求头,5为请求体。所以我们把HTTP请求组成是这样的
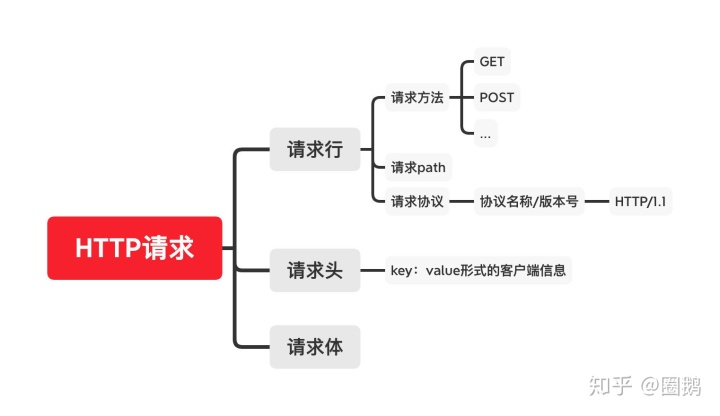
值得我们注意的是:1.
请求行中的请求协议版本
。(不同的http版本会有不同的特性,我们做优化时需要考虑到http协议的特性去做)2.
请求头中的客户端信息
。(我们之后做HTTP缓存的优化时就要应用到这里的相关属性),这里我们只需要对应请求报文有个大概的了解即可。
响应报文
当我们的服务器收到请求时,会给我们返回一些信息,这就是HTTP的响应报文。响应报文和我们的请求报文类似,它大概长这个样子

其中1、2为响应行,3为响应头,4为响应体,看起来和HTTP请求报文的结构类似,HTTP响应组成是这样的
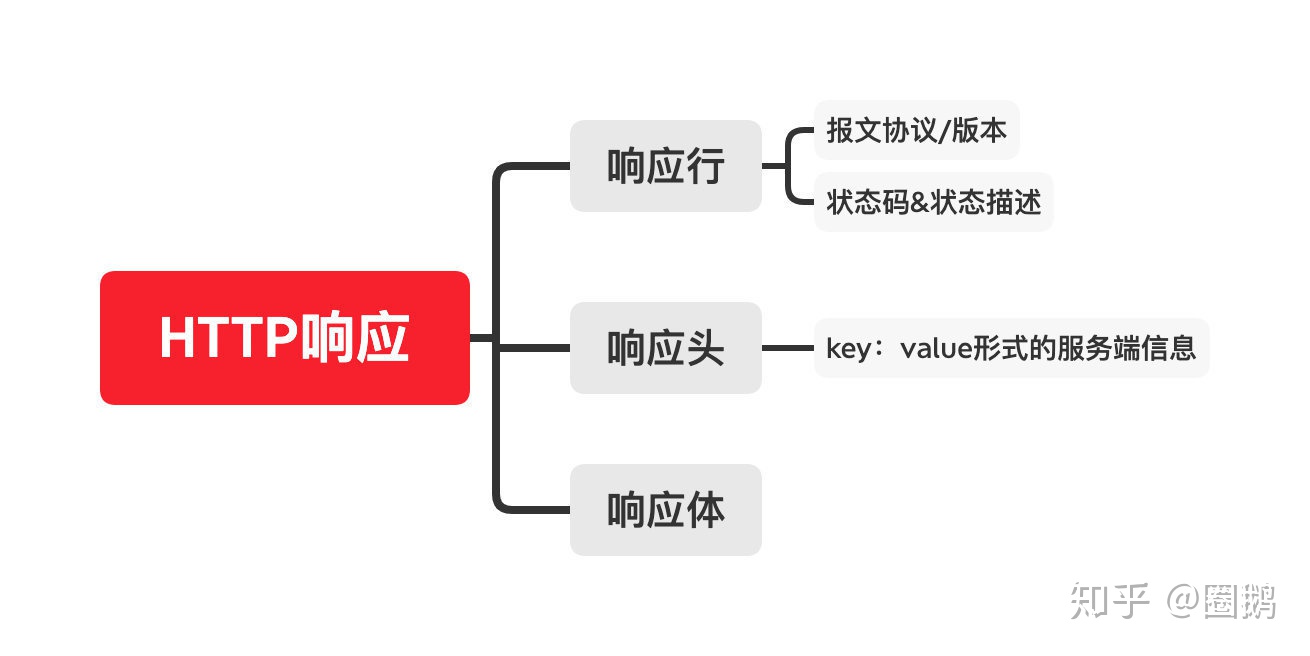
这里我们需要注意的:1.
状态码&状态描述
。(这里可以快速定位分析多种响应状态)2.
响应头中的服务端信息
。(我们之后做HTTP缓存的优化时也要应用到这里的相关属性)
其实我们HTTP基本上就由
HTTP请求
与
HTTP响应
两部分组成。目前我们对于HTTP请求报文和响应报文已经有一个比较简单的大体认知,之后我们讲把之前提到的几个关键点逐步展开进行分析。另外HTTP还有一个兄弟叫HTTPS,我们也会介绍一下HTTPS的实现原理。所以基本上HTTP这里的知识点有以下几部分:
- HTTP协议版本特征,以及HTTP不同版本协议的区别
- 结合HTTP请求头与响应头进行HTTP缓存策略
- HTTP状态码与状态描述
- HTTPS
HTTP版本区别
HTTP 0.9
只支持GET请求、只响应HTML文件,无状态码和错误代码
HTTP 0.9
HTML文档传输
<!-- HTTP Request -->
GET /mypage.html
<!-- HTTP Response -->
<HTML>
这是一个非常简单的HTML页面
</HTML>
HTTP 1.0
相比于0.9,1.0版本在可用性上做了极大的拓展,新增特性如下:
- 在请求头中增加版本协议信息用来区别HTTP版本
- 新增状态码
- 新增HTTP头
- 由于新增的HTTP头中的Content-Type可以指定其他的文本解析方式,所以可以传输HTML类型之外的文件
HTTP 1.0
HTML文档传输
<!-- HTTP Request -->
GET /mypage.html HTTP/1.0
User-Agent: NCSA_Mosaic/2.0 (Windows 3.1)
<!-- HTTP Response -->
200 OK
Date: Tue, 15 Nov 1994 08:12:31 GMT
Server: CERN/3.0 libwww/2.17
Content-Type: text/html
<HTML>
一个包含图片的页面
<IMG SRC="/myimage.gif">
</HTML>
HTML 1.0
其他文件传输(此处以图片为例)
<!-- HTTP Request -->
GET /myimage.gif HTTP/1.0
User-Agent: NCSA_Mosaic/2.0 (Windows 3.1)
<!-- HTTP Response -->
200 OK
Date: Tue, 15 Nov 1994 08:12:32 GMT
Server: CERN/3.0 libwww/2.17
Content-Type: text/gif
(这里是图片内容)
HTTP 1.1
HTTP 1.0
由于实现方式不一致导致在各个地方使用混乱,为了解决一致性问题,
HTTP 1.1
版本发布,这也是我们目前最常见的HTTP版本。
HTTP 1.1
版本相比于1.0版本,不仅消除了大量歧义内容,同时也引进了如下的功能改进。
- 持久化链接(支持TCP链接复用)
- 支持管线化技术(pipelining:在上一个请求响应之前可以发送第二个请求)但可惜的是只存在理论阶段,并没有被实现支持
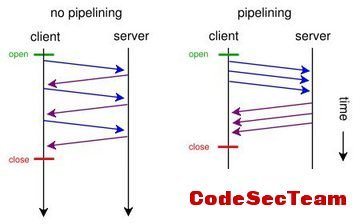
- 支持响应分块:chunked
- 支持额外的缓存控制特性
- If-Modefied-Since
- If-Unmodified-Since
- If-Match
- If-None-Match
- ET-tag
-
支持内容协商机制(客户端和服务端之间按照最合适的
语言
、
编码
、
类型
进行传输):Accept-XXX - 支持Host头(这个功能使不同的域名可以配置在同一个IP服务器下面):Host
HTTP 1.1
传输
<!-- HTTP Request -->
GET /en-US/docs/Glossary/Simple_header HTTP/1.1
Host: developer.mozilla.org
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:50.0) Gecko/20100101 Firefox/50.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate, br
Referer: https://developer.mozilla.org/en-US/docs/Glossary/Simple_header
<!-- HTTP Response -->
200 OK
Connection: Keep-Alive
Content-Encoding: gzip
Content-Type: text/html; charset=utf-8
Date: Wed, 20 Jul 2016 10:55:30 GMT
Etag: "547fa7e369ef56031dd3bff2ace9fc0832eb251a"
Keep-Alive: timeout=5, max=1000
Last-Modified: Tue, 19 Jul 2016 00:59:33 GMT
Server: Apache
Transfer-Encoding: chunked
Vary: Cookie, Accept-EncodingREST:也是因为HTTP拓展到Web应用,原来HTTP只读(其他逻辑都在服务器)的方式已经不能被满足了。所以新的HTTP使用模式(representational state transfer)被设计出来,它让我们可以通过不同的请求方式(API)来查看/操作数据,而不是服务器进行修改,这就是我们的REST模式
HTTP 2.0
由于网页应用的复杂度越来越高,更多的请求被使用HTTP协议进行传输。而使用
HTTP 1.1
面对一些场景会有着性能问题,比如说:
-
队头阻塞
:HTTP 1.1无法通过单个链接进行并发请求,所以浏览器需要开启多个链接加快进程。 -
昂贵的链接
:由于1和浏览器的域名链接限制,导致网站请求资源的性能瓶颈。 -
HTTP管线化
:当有一个大/慢的请求,使用管线化技术会导致后续请求都受影响。
HTTP管线化瓶颈:就像在超市收银台或者银行柜台排队时一样,你并不知道前面的
顾客
是干脆利索的还是会跟收银员/柜员磨蹭到世界末日(不管怎么说,服务器(即收银员/柜员)是要按照顺序处理请求的,如果
前一个请求非常耗时(顾客磨蹭)
,那么后续请求都会受到影响。
为了解决这些问题,
HTTP 2.0
应运而生,
HTTP 2.0
拥有以下特性:
- 二进制分帧(由文本协议转化为二进制协议)
-
多路复用(并行的请求可以在同一链接中进行,解除了
HTTP 1.x
的顺序和阻塞约束) - 压缩headers(去除了传输重复数据,比如协议之类的只会传输一次)
- 支持服务器推送缓存
- 支持Alt-Svc(允许给定资源的位置和资源鉴定),允许更智能的CDN缓冲机制
- 支持Client-Hints(通过传输屏幕分辨率、设备尺寸… 传输合适的响应式资源,如:对应图片资源)
- cookie引入安全前缀以保证cookie没有被修改过
其中最重要的特性就是
多路复用
,它解决了
HTTP 1.1
中的队头阻塞问题。那么
HTTP 2.0
的多路复用是如何实现的呢?
首先明确一个概念:HTTP 2.0的
多路复用
和HTTP 1.1开启
keep-alive
是不一样的,keep-alive虽然开启之后也可以使用一条TCP链接,但是本质上还是属于一问一答的形式,也就是一条传输完才可以传输下一条。而HTTP 2.0中的
多路复用
就不一样了,多路复用可以并发好几个请求在一条TCP链接中进行传输,也就是一个域名下面的多个资源一起请求和传输。
那么聪明的小伙伴一定有问题了:那么多条请求传输,
HTTP 2.0
是如何做到数据不会相互污染呢?这就要得益于HTTP 2.0的两个重要概念:帧(frame)和流(steam)。
这是HTTP帧:
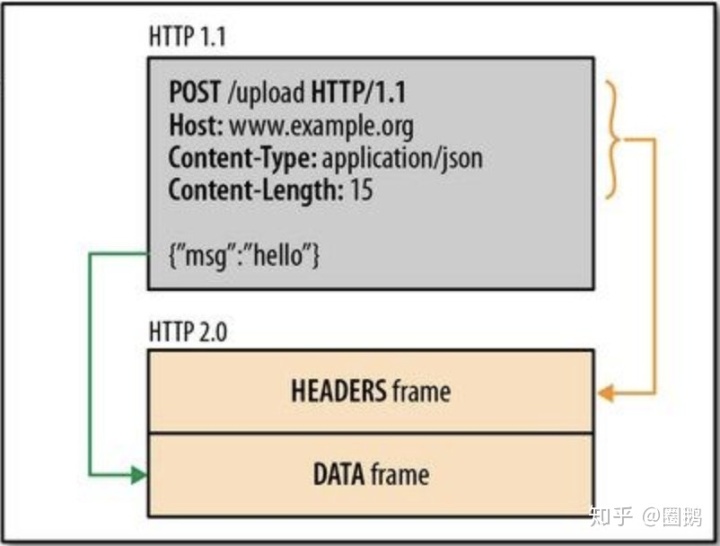
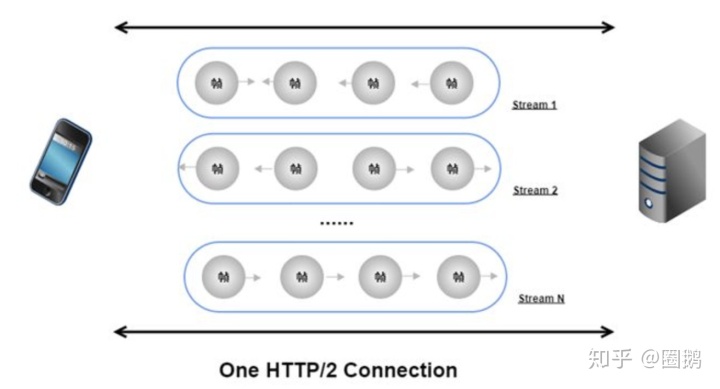
这是HTTP流:
我们之前有说过
HTTP 2.0讲文本协议转化为二进制协议
,我们的
HTTP 2.0
传输就是基于二进制帧的。在
HTTP 2.0
中每条TCP链接里面会存在多条双向数据流,里面的每个数据流都会有一个唯一标识和优先级。而流里面就是由我们的二进制帧组成,二进制帧里面会有头部信息标识来标明自己属于哪一条数据流。
通过这个技术,可以避免 HTTP 旧版本中的队头阻塞问题,极大的提高传输性能。
那为什么HTTP1.1版本不可以呢?
原因是:HTTP/1.1 不是二进制传输,而是通过文本进行传输。由于没有流的概念,在使用并行传输(多路复用)传递数据时,接收端在接收到响应后,并不能区分多个响应分别对应的请求,所以无法将多个响应的结果重新进行组装,也就实现不了多路复用。
HTTPS
从上面我们可以看到HTTP协议随着不断的演进,传输的效率变得越来越高。但是除了提高传输效率,我们的传输安全性也是一个不可忽略的大问题,我们之前在介绍HTTP请求时曾说过:
HTTP请求本质上
是把HTTP报文通过被包裹在TCP报文内的方式,发送到服务端指定端口的过程。
那么如果我们的请求被拦截,HTTP报文就会被读取/修改,就会导致我们的信息泄露。
为了避免这种情况的发生,我们想到了一个方法:
把HTTP报文先进行一次加密(SSL/TSL),然后再把加密后的HTTP报文放进TCP报文中,这样就算是请求被拦截,但是由于HTTP报文已经被加密,别人也就获取不到我们的真实信息了
,这就是HTTPS。
SSL和TSL的加密方式分为:对称加密和非对称加密,其中原理会涉及到私钥、公钥的概念。想要更详细的了解可以参考这里
HTTP状态码与状态描述
HTTP状态码是HTTP中很重要的概念知识,通过HTTP状态码的返回我们可以快速的定位响应状态,接下来我们大体的对于状态码进行一个大体介绍:
- 1XX:消息,代表进行中状态
- 100:表明部分请求服务器已接收,需继续发送剩余响应
- 2XX:已完成状态
- 200:成功
- 202:成功但未处理
- 204:成功但无返回
- 3XX:转发/重定向
- 301:永久移动的转发/重定向
- 302:临时移动的转发/重定向
- 304:not Modified未修改,缓存
- 4XX:请求/客户端错误
- 400:服务器不理解请求语法
- 403:服务器拒绝访问
- 404:资源找不到
- 412:未满足前提条件
- 5XX:服务端错误
- 500:未知错误
- 503:服务器过载/维护中
HTTP缓存
试想一下,如果客户端发起的每个请求都需要服务器进行计算响应,那并发数将会收到极大的限制。此时缓存可以说是一个十分重要的优化手段,合理的缓存策略可以极大的减少请求的开销。接下来我们就来介绍一下HTTP缓存。
宏观上HTTP缓存可以分为两大类:
私有缓存(强缓存)
和
共享缓存(协商缓存)
。
私有缓存可以大致理解为是我们本地浏览器所做的缓存,当这个窗口被关闭后里面的缓存就失效了,由于这个缓存是存在于我们本地的浏览器中,并不一定与别人的客户端进行共享,所以叫做私有缓存。
而共享缓存可以理解为是服务器的缓存,无论是哪个用户请求回来都会读取这部分缓存内容,所以叫做共享缓存。
私有缓存
- Pragma:HTTP 1.0中的缓存兼容字段
- Expires:缓存有效时间,会与本机时间进行对比,超出则请求资源(但是由于对比的是本机时间,所以不一定准确)
Expires: Wed ,21 Oct 2015 07:28:00 GMT
-
当
Expires
为0,则表示资源已过期 -
若存在
Cache-Control
头且值为
max-age
或
s-max-age
,则Expires字段失效 - Cache-Control:缓存策略
- no-store:无缓存
- no-cache:缓存,但是需要服务器验证(验证Last-Modified、ETag等字段)
- max-age:相对过期时间,单位为s
共享缓存
- (响应)Last-Modified:文件的最后修改时间
- (请求)If-Modified-Since:比较资源最后的更新时间是否一致,一致304,不一致200
- (请求)If-Unmodified-Since:日期之后,且未更新才接受,否则412(断点续传)
- (响应)Etag:资源特定标识
- (请求)If-Match:比较Etag是否一致,一致200,不一致412
- (请求)If-None-Match:比较Etag是否不一致,不一致200,一致304
缓存优先级
私有缓存 > 共享缓存
Cache-Control > Expires > Pragma > Tag > Last-Modified
引用
https://www.zhihu.com/question/306768582/answer/595200654
https://github.com/Advanced-Frontend/Daily-Interview-Question/issues/14
https://segmentfault.com/a/1190000020801458?utm_source=tag-newest