我们都知道对大规模数据进行复杂的数据分析通常需要耗费大量的时间,这时就需要我们的数据消减技术了。
数据消减技术的主要目的就是从原有巨大数据集中获得一个精简的数据集,并使这一精简数据集保持原有数据集的完整性。这样在精简数据集上进行数据挖掘就会提高效率,并且能够保证挖掘出来的结果与使用原有数据集所获得的结果基本相同。
数据消减的主要策略有以下几种。
| 名称 | 说明 |
|---|---|
| 数据立方合计 | 这类合计操作主要用于构造数据立方(数据仓库操作)。 |
| 维数消减 | 主要用于检测和消除无关、弱相关,或冗余的属性或维(数据仓库中属性)。 |
| 数据压缩 | 利用编码技术压缩数据集的大小。 |
| 数据块消减 | 利用更简单的数据表达形式,如参数模型、非参数模型(聚类、采样、直方图等),来取代原有的数据。 |
| 离散化与概念层次生成 | 所谓离散化就是利用取值范围或更高层次概念来替换初始数据。利用概念层次可以帮助挖掘不同抽象层次的模式知识。 |
数据立方合计
图 1 展示了在 3 个维度上对某公司原始销售数据进行合计所获得的数据立方。它从时间(年代)、公司分支,以及商品类型 3 个角度(维)描述了相应(时空)的销售额(对应一个小立方块)。
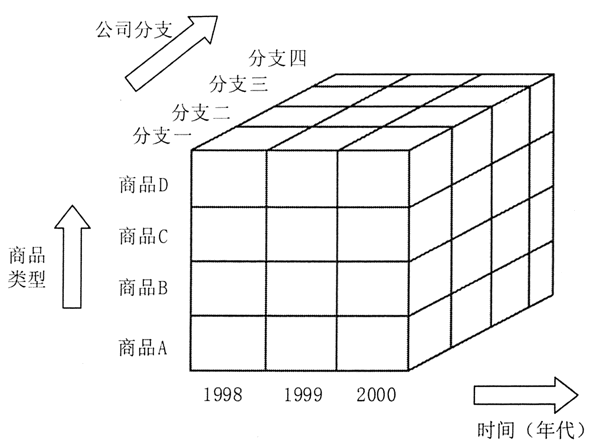
图 1 数据立方合计描述
每个属性都可对应一个概念层次树,以帮助进行多抽象层次的数据分析。例如,一个分支属性的(概念)层次树,可以提升到更高一层的区域概念,这样就可以将多个同一区域的分支合并到一起。
在最低层次所建立的数据立方称为基立方,而最高抽象层次对应的数据立方称为顶立方。
顶立方代表整个公司三年中,所有分支、所有类型商品的销售总额。显然每一层次的数据立方都是对低一层数据的进一步抽象,因此它也是一种有效的数据消减。
维数消减
数据集可能包含成百上千的属性,而这些属性中的许多属性是与挖掘任务无关的或冗余的。
例如,挖掘顾客是否会在商场购买电视机的分类规则时,顾客的电话号码很可能与挖掘任务无关。但如果利用人类专家来帮助挑选有用的属性,则困难又费时费力,特别是当数据内涵并不十分清楚的时候。无论是漏掉相关属性,还是选择了无关属性参加数据挖掘工作,都将严重影响数据挖掘最终结果的正确性和有效性。此外,多余或无关的属性也将影响数据挖掘的挖掘效率。
维数消减就是通过消除多余和无关的属性而有效消减数据集的规模的。
这里通常采用属性子集选择