1.概述
在对Kafka使用层面掌握后,进一步提升分析其源码是极有必要的。纵观Kafka源码工程结构,不算太复杂,代码量也不算大。分析研究其实现细节难度不算太大。今天笔者给大家分析的是其核心处理模块,core模块。
2.内容
首先,我们需要对Kafka的工程结构有一个整体的认知度,Kafka 大家最为熟悉的就是其消费者与生产者。然其,底层的存储机制,选举机制,备份机制等实现细节,需要我们对其源码仔细阅读学习,思考与分析其设计之初的初衷。下面,我们首先来看看Kafka源码工程模块分布,截止当天日期,官方托管在 Github 上的 Kafka 源码版本为:0.10.2.1,其工程分布结构如下图所示:
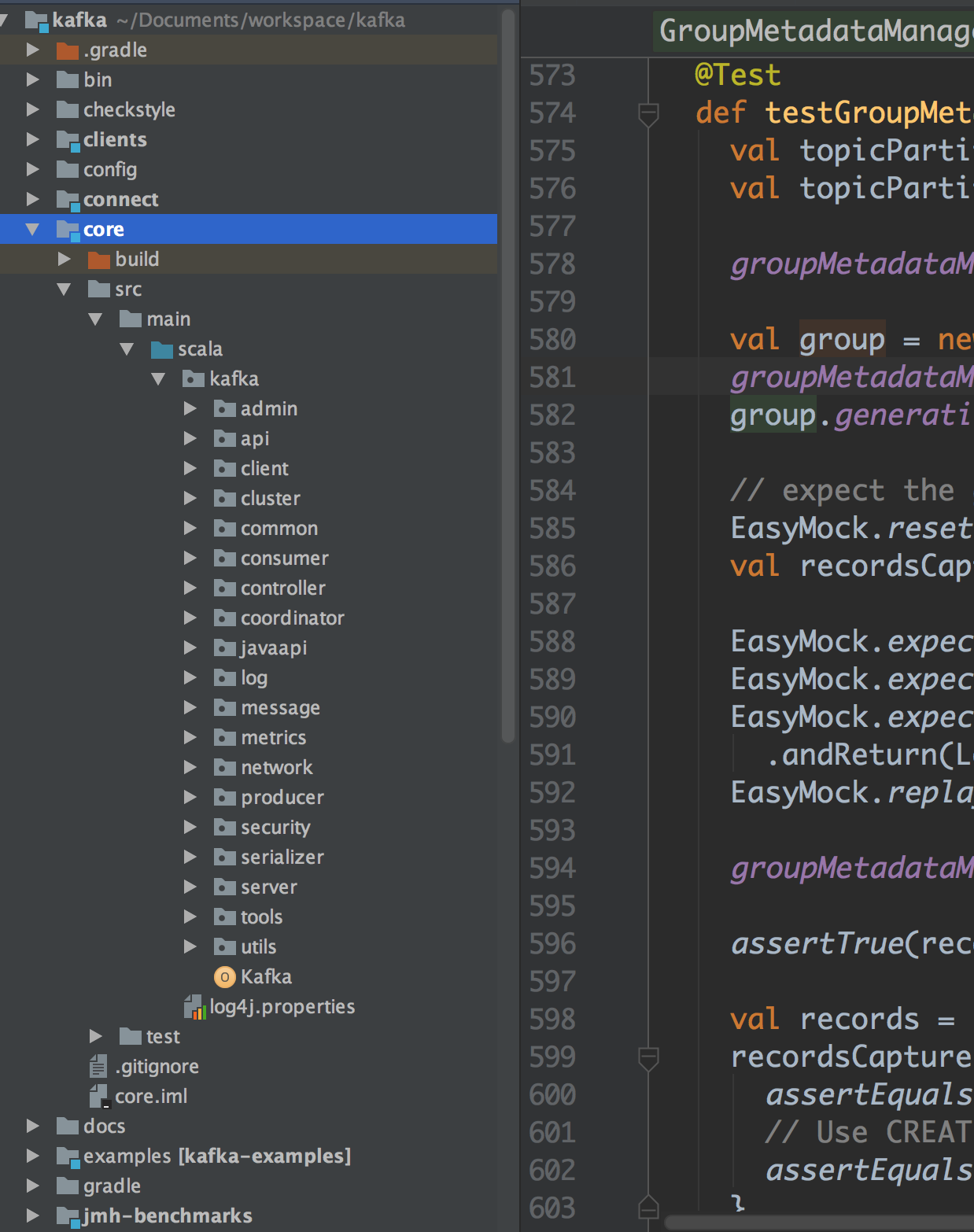
这里笔记只针对core模块进行说明,其他模块均是启动脚本,文档说明,测试类或是Java客户端的相关代码,本篇博客就不多做赘述了。
模块名
说明
admin
kafka的管理员模块,操作和管理其topic,partition相关,包含创建,删除topic,或者拓展分区等。
api
主要负责数据交互,客户端与服务端交互数据的编码与解码。
client
该模块下就一个类,producer读取kafka broker元数据信息,topic和分区,以及leader。
cluster
这里包含多个实体类,有Broker,Cluster,Partition,Replica。其中一个Cluster由多个Broker组成,一个Broker包含多个Partition,一个Topic的所有Partition分布在不同的Broker中,一个Partition包含多个Replica。
common
这是一个通用模块,其只包含各种异常类以及错误验证。
consumer
消费者处理模块,负责所有的客户端消费者数据和逻辑处理。
controller
此模块负责中央控制器的选举,分区的Leader选举,Replica的分配或其重新分配,分区和副本的扩容等。
coordinator
负责管理部分consumer group和他们的offset。
javaapi
提供Java语言的producer和consumer的API接口。
log
这是一个负责Kafka文件存储模块,负责读写所有的Kafka的Topic消息数据。
message
封装多条数据组成一个数据集或者压缩数据集。
metrics
负责内部状态的监控模块。
network
该模块负责处理和接收客户端连接,处理网络时间模块。
producer
生产者的细节实现模块,包括的内容有同步和异步的消息发送。
security
负责Kafka的安全验证和管理模块。
serializer
序列化和反序列化当前消息内容。
server
该模块涉及的内容较多,有Leader和Offset的checkpoint,动态配置,延时创建和删除Topic,Leader的选举,Admin和Replica的管理,以及各种元数据的缓存等内容。
tools
阅读该模块,就是一个工具模块,涉及的内容也比较多。有导出对应consumer的offset值;导出LogSegments信息,以及当前Topic的log写的Location信息;导出Zookeeper上的offset值等内容。
utils
各种工具类,比如Json,ZkUtils,线程池工具类,KafkaScheduler公共调度器类,Mx4jLoader监控加载器,ReplicationUtils复制集工具类,CommandLineUtils命令行工具类,以及公共日志类等内容。
3.源码环境
阅读Kafka源码需要准备以下环境:
JDK
IDE(Eclipse,IDEA或者其他)
gradle
关于环境的搭建,大家可以利用搜索引擎去完成,比较基础,这里就不多赘述了。然后在源码工程目录下执行以下命令:
gradle idea(编辑器为IDEA)
gradle eclipse(编辑器为Eclipse)
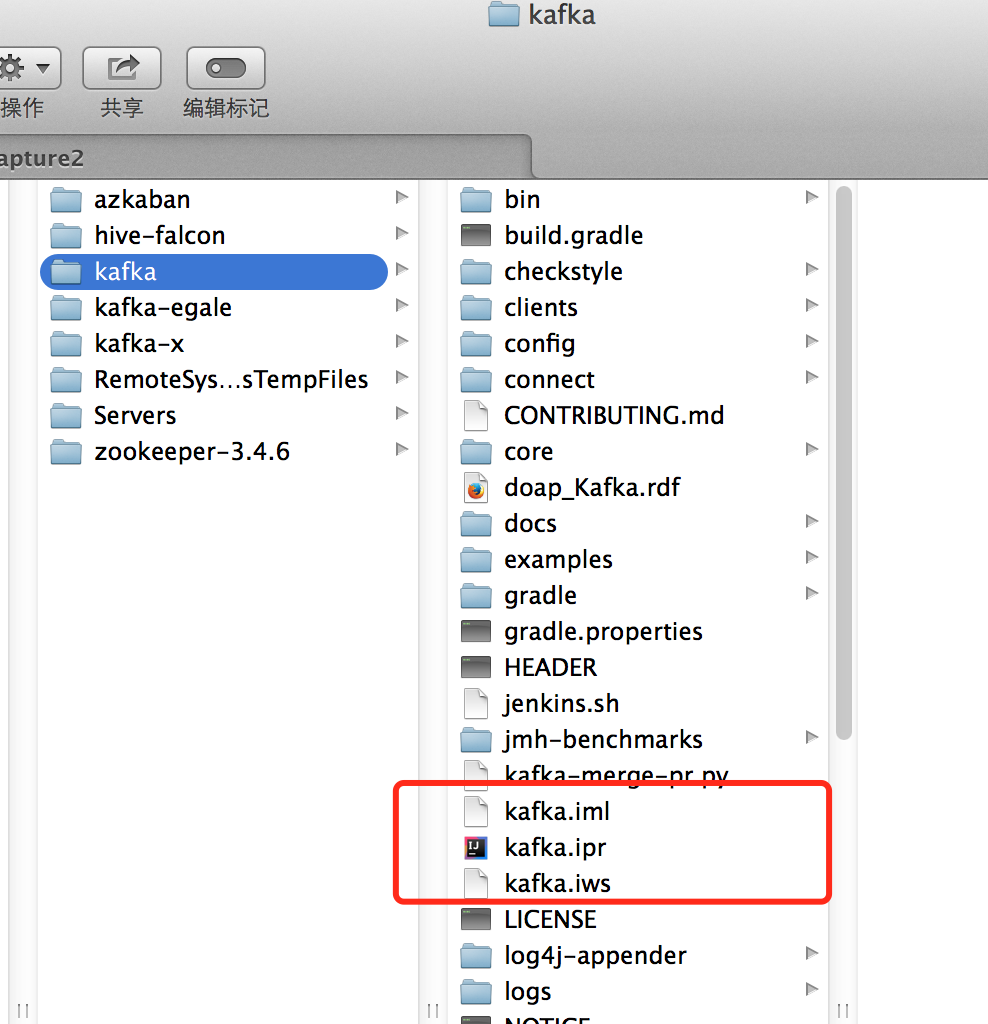
如何选择,可按照自己所使用的编辑器即可。这里笔者所使用的是IDEA,执行命令后,会在源码目录生成以下文件,如下图所示:
然后,在编辑器中导入该源码项目工程即可,如下图所示:
4.运行源码
这里,我们先在config模块下设置server.properties文件,按照自己的需要设置,比如分区数,log的存储路径,zookeeper的地址设置等等。然后,我们在编辑器中的运行中设置相关的启动参数,如下图所示:
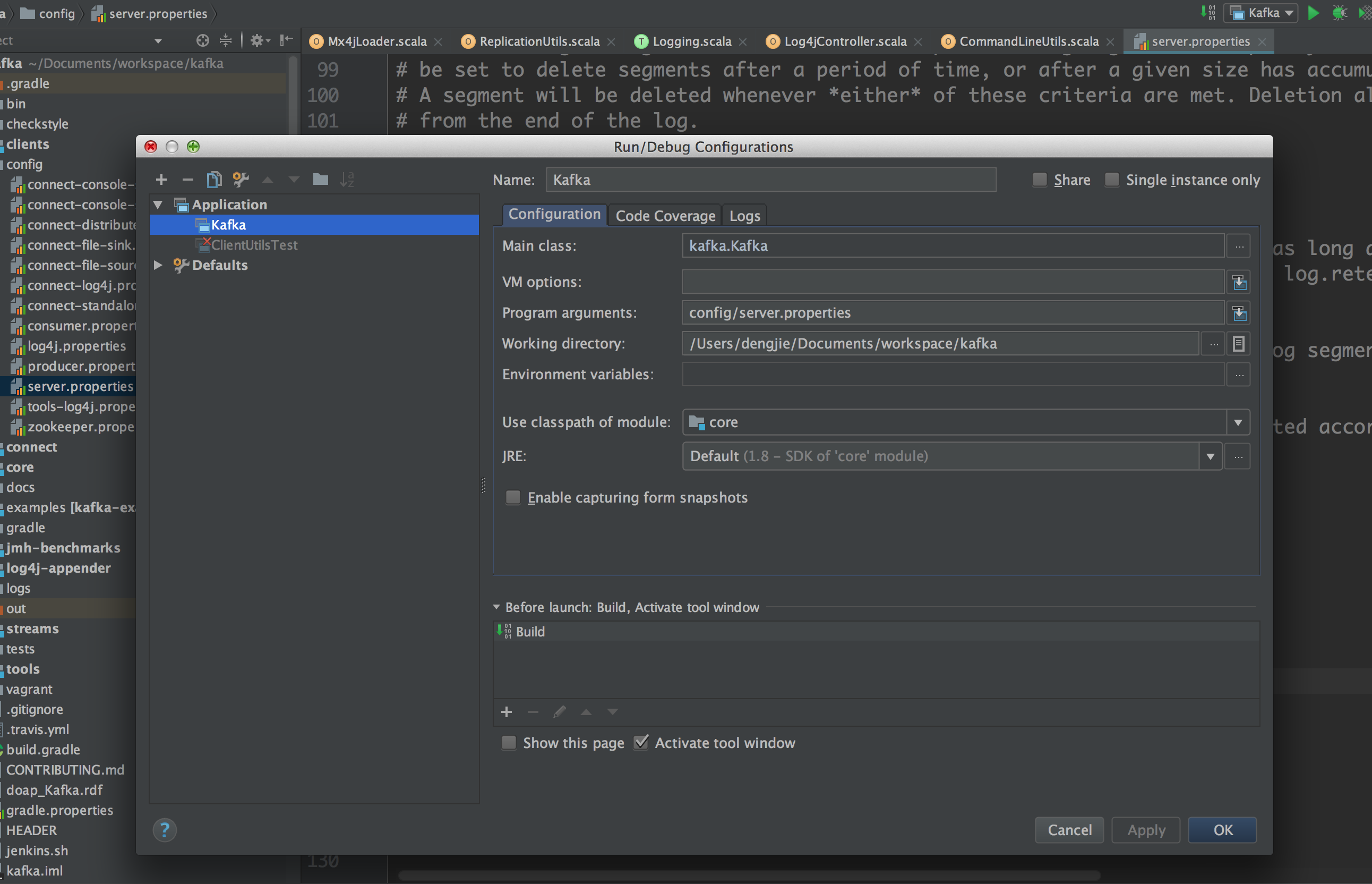
启动类Kafka.scala在core模块下,需要注意的是,这里在启动Kafka之前,确保我们之前在server.properties文件中所配置的Zookeeper集群已正常运行,然后我们在编辑器中运行Kafka源码,如下图所示:
5.预览结果
这里,我们做一下简单的修改,在启动类的开头打印一句启动日志和启动时间,部分运行日志和运行结果截图如下所示:
Start Kafka,DateTime[1494065094606]
[2017-05-06 18:04:54,830] INFO KafkaConfig values:
advertised.host.name= nulladvertised.listeners= nulladvertised.port= nullauthorizer.class.name=auto.create.topics.enable= trueauto.leader.rebalance.enable= truebackground.threads= 10broker.id = 0broker.id.generation.enable = truebroker.rack= nullcompression.type=producer
connections.max.idle.ms= 600000controlled.shutdown.enable= true
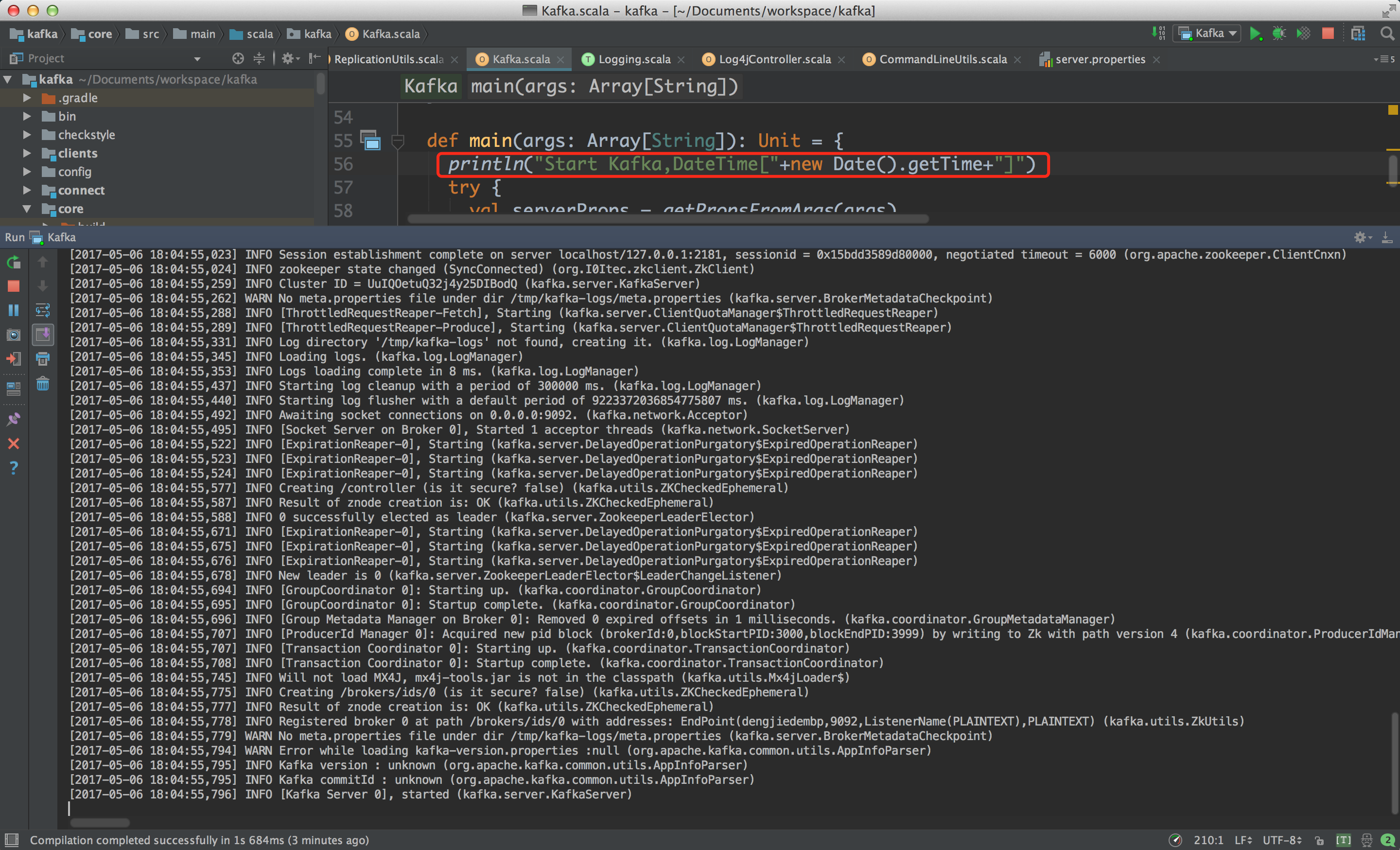
如上图,红色框即是我们简单的添加的一句代码。
编译源代码:
./gradlew releaseTarGz -x signArchives
6.总结
本篇博客给大家介绍了Kafka源码的core模块下各个子模块所负责的内容,以及如何便捷的去阅读源码,以及在编辑器中运行Kafka源码。后续,再为大家分析Kafka的存储机制,选举机制,备份机制等内容的实现细节。最后,欢迎大家使用Kafka-Eagle监控工具。
7.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!