Python Error List 错误列表
这是一份学习或者使用Python过程中的错误总结列表,随着实验进行,此列表将不断更新.
No.1
IndentationError: expected an indented block
>>> if the_world_is_flat :
... print("Be careful not to fall off!")
File "<stdin>", line 2
print("Be careful not to fall off!")
^
IndentationError: expected an indented block
解决方式,…符号表示多行的继续,需要在行开头添加间隔,使用空格符号添加即可:
>>> if the_world_is_flat :
... print("Be careful not to fall off!")
...
Be careful not to fall off!
>>>
No2 .
NameError: name ‘pi’ is not defined
如果一个变量没有赋值就使用,则python会提示没有定义,而报错.
No3 . IndentationError: unindent does not match any outer indentation level
对于while等包括语句块的语句,需要利用缩进来区分同一块代码,因此同一个层次的代码,缩进量需要相同,这里print语句和随后的赋值语句缩进量不同,因而导致错误.
例如:
>>> a,b = 0,1;
>>> while b < 20 :
... print(b,end=',');
... a,b= b,a+b;
File "<stdin>", line 3
a,b= b,a+b;
^
解决办法,对于同一个层次代码,使用相同的缩进量.
No4 .TypeError: parrot() got multiple values for argument ‘voltage’
传递函数参数时,为同一个参数赋了多个值,一般发生在使用positional 和keyword argument时的错误,例如定义函数parrot如下:
def parrot(voltage, state='a stiff', action='voom', type='Norwegian Blue'):
print("-- This parrot wouldn't", action, end=' ')
print("if you put", voltage, "volts through it.")
print("-- Lovely plumage, the", type)
print("-- It's", state, "!")
调用方式:
parrot(110, voltage=220) # duplicate value for the same argument
中,为voltage重复传递参数值,因此造成错误.
解决办法,即是确保参数的正确传递,且不要因为positional或者keyword参数引起重复.
No.5 TypeError: ‘list’ object cannot be interpreted as an integer
类型错误,不能将list对象转换为一个整数.
错误代码,例如如下例子:
args = [3,6]
print(list(range(args)))
range函数本应该需求,一个整数,或者一对范围,或者三个整数类型,才能构造一个iterable,这里直接将args这个列表传递给它是不行的,需要通过解压缩机制,更正后代码为:
args = [3,6]
print(list(range(*args))) # call with arguments unpacked from a list
使用*args对列表进行解压缩,后传递给range构造一个itetable.
No.6 元组在list comprehension中没有使用括号引起的语法错误
>>> [x,x**2 for x in range(6)]
File "<stdin>", line 1
[x,x**2 for x in range(6)]
^
SyntaxError: invalid syntax
在使用list comprehension时,如果遇到元组,必须用括号括起来,否则引起语法错误.
解决办法,书写如下:
>>> [(x,x**2) for x in range(6)]
[(0, 0), (1, 1), (2, 4), (3, 9), (4, 16), (5, 25)]
No.7 list comprehension中generator object引起错误
这个错误及细节描述摘自: stackoverflow
python-print-a-generator-expression
<pre name="code" class="python">>>> x*x for x in range(10)
File "<stdin>", line 1
x*x for x in range(10)
^
SyntaxError: invalid syntax
像x*x for x in range(10)这种语句,在python中称之为generator expression,这种表达式不能直接写成一行,需要用括号括起来,例如:
>>> (x*x for x in range(10))
<generator object <genexpr> at 0xb6ffb414>
但是在函数调用中,可以省去外层括号,例如:
>>> sorted(x*x for x in range(10))
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
我们可以通过如下方式利用generator expression,构造集合\列表\字典对象如下:
set:
>>> {x*x for x in range(10)}
{0, 1, 64, 4, 36, 9, 16, 49, 81, 25}
>>> set(x*x for x in range(10))
{0, 1, 64, 4, 36, 9, 16, 49, 81, 25}
dict:
>>> dict((x,x*x) for x in range(10))
{0: 0, 1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81}
>>> {x:x*x for x in range(10)}
{0: 0, 1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81}
list:
>>> list(x*x for x in range(10))
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
>>> [x*x for x in range(10)]
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
No.8 TypeError: ‘tuple’ object does not support item assignment
python中的元组是不可变的,因此不能对元组元素直接赋值;但是,元素可以包含可变对象,可变对象是可以修改的.
例如下面代码中,对t[0]赋值出现错误,但是对t[3][0]赋值却是可行的.
>>> a = [4,5,6]
>>> t = 1,2,3,a
>>> t
(1, 2, 3, [4, 5, 6])
>>> t[0] = -1
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
>>> t[3][0] = -1
>>> t
(1, 2, 3, [-1, 5, 6])
No.9 ValueError: too many values to unpack (expected 2)
python要求对于序列的解包(unpack),等号左边必须有足够的元素来接收右边序列的元素,也就是左边元素个数要与右边相等.
>>> t = 12345,54321,'Hello!'
>>> x,y = t
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: too many values to unpack (expected 2)
>>> x,y,z = t
>>> print(x,y,z)
12345 54321 Hello!
这里,t包含三个元素的元组,因此解包时左边也需要3个元素来接收,使用x,y,z三个元素接收即可解决.
No.10 python3.4 ImportError: No module named ‘_mysql’
Ubuntu 默认安装有python2.7 和python3.4,使用
sudo apt-get install python-mysqldb
安装完毕后,python2.7可以正常工作如下:
Python 2.7.6 (default, Mar 22 2014, 22:59:38)
[GCC 4.8.2] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import _mysql
>>> import sys
>>> con = _mysql.connect('localhost','root','root','testdb')
>>> con.query("SELECT VERSION()")
>>> result = con.use_result()
>>> print("MySQL version: ",result.fetch_row()[0])
('MySQL version: ', ('5.5.40-0ubuntu0.14.04.1',))
但是python3.4却不能正常工作,如下:
Python 3.4.0 (default, Apr 11 2014, 13:05:18)
[GCC 4.8.2] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import _mysql
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ImportError: No module named '_mysql'
解决办法:
MySQLdb 的C底层库,没有移植到python3,因此有两个选择
这里安装mysql-connector-python-1.1.7,可以从
Connector-Python下载.
tar xvf mysql-connector-python-1.1.7.tar.gz
cd mysql-connector-python-1.1.7
sudo python3 setup.py install 利用上述命令,即可安装完毕,安装完毕后,可以利用命令import mysql.connector测试.
OK.
更多细节参考:
Python3连接MySQL数据库
和
ubuntu python3 django开发环境配置
No.11 TypeError: unsupported operand type(s) for +: ‘Vector’ and ‘Vector’
自定义类,如果要实现加法符号的运算,需要重载__add__方法,如下例子:
# overloading method example
class Vector:
def __init__(self,a,b):
self.a = a
self.b = b
def __str__(self): # override to give printable string representation
return 'Vector(%d,%d)'%(self.a,self.b)
def __add__(self, other): # overload operator plus
return Vector(self.a+other.a,self.b+other.b)
v1 = Vector(2,10)
v2 = Vector(5,2)
print(v1+v2)
重载后将输出:
Vector(7,12)
No.12 AttributeError: can’t set attribute
python中允许定义只读属性,例如如下代码定义的只读属性voltage:
class Parrot:
def __init__(self):
self._voltage = 100000
@property
def voltage(self):
"""Get the current voltage."""
return self._voltage
尝试给voltage赋值如下:
p = Parrot()
print(p.voltage)
print(hex(id(p.voltage)))
p.voltage = 200000
出现错误:
p.voltage = 200000
AttributeError: can’t set attribute
No.13 UnicodeDecodeError: ‘utf8’ codec can’t decode byte 0x8b in position 1: invalid start byte
网络爬虫程序中,使用urllib2 response read读取响应内容后,解析出错。
可以查看下响应头如下:
回应头:
HTTP/1.1 200 OK
Server: ASERVER/1.2.9-3
Date: Sun, 04 Jan 2015 13:38:26 GMT
Content-Type: text/html; charset=utf-8
Transfer-Encoding: chunked
Connection: keep-alive
Vary: Accept-Encoding
X-Author: sq_zhuyi
Set-Cookie: uuid=8c63fb4f-bc8f-4b2a-905c-6d06b72a0664; expires=Mon, 05-Jan-2015 13:37:19 GMT; path=/
Cache-Control: private
Content-Encoding: gzip
X-Powered-By-Anquanbao: MISS from nup-dg-wy-sb4
可以看出content-encoding为gzip,因此解决办法即使利用gzip解压数据,修正后的代码如下:
def read_data(resp):
# 读取响应内容
if response.info().get('Content-Encoding') == 'gzip':
buf = StringIO.StringIO(resp.read())
gzip_f = gzip.GzipFile(fileobj=buf)
return gzip_f.read()
else:
return resp.read()
#使用read_data读取响应内容
page_content = read_data(response)
然后利用html中读取的charset解码即可,例如:
encoding = response.headers['content-type'].split('charset=')[-1]
print page_content.decode(encoding)
然后可以显示内容啦.

No 14 .URL中中文的编码与解码问题
中文编码如果不能搞定,确实有些烦恼,下面的例子帮你搞定它们。
这个例子首先解析出
百度知道
url参数还原成中文,然后合成了一个与原来类似的url,并通过它读取网页内容。
完整的代码如下:
# -*- coding: utf-8 -*-
# 使用python2.7
import urllib
import urllib2
import sys
# 编码url
print sys.stdin.encoding # utf-8或其他 下面utf-8即是指这个默认编码
# 原始url
# http://zhidao.baidu.com/search?lm=0&rn=10&pn=0&fr=search&ie=gbk&word=买苹果手机
url = 'http://zhidao.baidu.com/search?lm=0&rn=10&pn=0&' \
'fr=search&ie=gbk&word=%C2%F2%C6%BB%B9%FB%CA%D6%BB%FA'
print url
# 解析url
print urllib.unquote(url.decode('utf-8').encode('gbk')).decode('gbk')
# 编码url中文参数
quote_param = urllib.quote('买苹果手机'.decode('utf-8').encode('gbk'))
print quote_param
# 函数urlencode不会改变传入参数的原始编码
# 也就是说需要在调用之前将post或get参数的编码调整好
param = urllib.urlencode({'lm': 0, 'rn': '1',
'pn': 0, 'fr': 'search',
'ie': 'gbk', 'word': u'买苹果手机'.encode('gbk')})
generate_url = 'http://zhidao.baidu.com/search?'+param
print generate_url
response = urllib2.urlopen(generate_url)
print response.read().decode('gbk')[0:280]
程序输出:
UTF-8
http://zhidao.baidu.com/search?lm=0&rn=10&pn=0&fr=search&ie=gbk&word=%C2%F2%C6%BB%B9%FB%CA%D6%BB%FA
http://zhidao.baidu.com/search?lm=0&rn=10&pn=0&fr=search&ie=gbk&word=买苹果手机
%C2%F2%C6%BB%B9%FB%CA%D6%BB%FA
http://zhidao.baidu.com/search?fr=search&word=%C2%F2%C6%BB%B9%FB%CA%D6%BB%FA&pn=0&lm=0&rn=1&ie=gbk
<!DOCTYPE html>
<!--STATUS OK-->
<html>
<head>
<meta http-equiv="X-UA-Compatible" content="IE=9" />
<meta http-equiv="content-type" content="text/html;charset=gbk" />
<meta property="wb:webmaster" content="3aababe5ed22e23c" />
<title>
百度知道搜索_买苹果手机
</title>
No.15
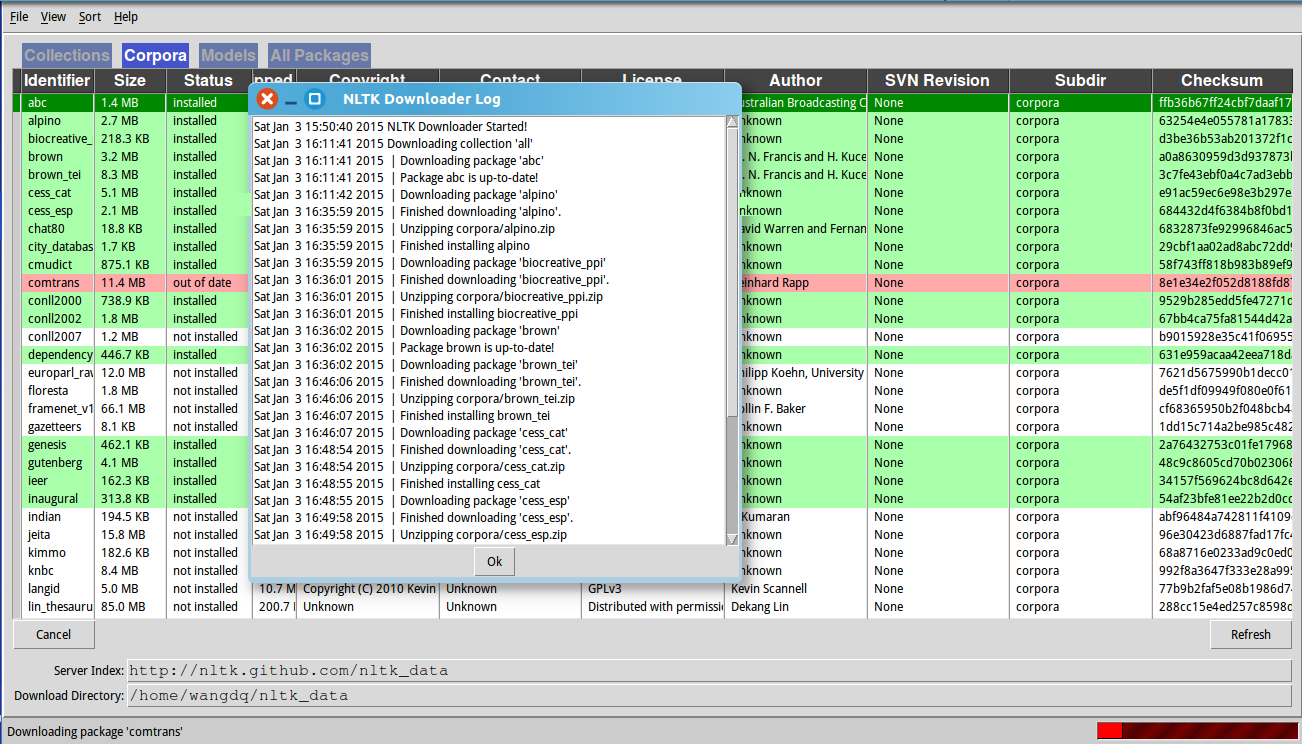
python无法从googlecode下载nltk data (book所包含的)
解决办法:
默认downloader使用的default url是: nltk.googlecode.com/svn/trunk/nltk_data/index.xml,可能网络无法访问该资源,在downloader界面中可以输入替代url,例如:http://nltk.github.com/nltk_data/.
然后选择book,下载如下图所示:
No.16 TypeError: expected a character buffer object
在使用python写入文件时,使用函数write时,应该使用write(str)进行,否则出现上述错误。
python2.7.9 文档描述如下:
f.write(string)
writes the contents of
string
to the file, returning
None
.
>>>
f
.
write
(
‘This is a test
\n
‘
)
写入其他类型时,需要进行类型转换:
To write something other than a string, it needs to be converted to a stringfirst:
>>> value = ('the answer', 42)
>>> s = str(value)
>>> f.write(s)
No.17 ValueError: math domain error
例如:
>>> from math import log
>>> log(-1)
Traceback (most recent call last):
File "<pyshell#59>", line 1, in <module>
log(-1)
ValueError: math domain error对一个负数求log,则会出现如上错误。这个属于像除0一类的求值错误。
No.18 java 调用 Jython 中中文乱码解决
这是我在ubuntu平台下测试通过的一种解决方法,这也是效率不高的方法,思路是: 将java传入的字符串转换为utf-8字节数组,然后在python中重新生成utf-8字符串即可,具体平台可能稍微有所不同。
这里给出一个例子,用于搜索中文关键字,并返回结果。
java代码如下:
package javaPython;
import java.io.UnsupportedEncodingException;
import org.python.core.PyFunction;
import org.python.core.PyObject;
import org.python.core.PyString;
import org.python.util.PythonInterpreter;
/**
* 这是Jython处理中文一个尝试
* 在ubuntu下测试成功 windows下可能需要设置默认utf-8编码等工作
* 效率不高 有待改进
* @author wangdq
* 2015-03-10
*/
public class Demo {
public static void main(String[] args) throws UnsupportedEncodingException {
String string = "Jython处理中文,还是有点烦恼!";
String text = stringToBytes(string);
//System.out.println(text);
PythonInterpreter interpreter = new PythonInterpreter();
interpreter.execfile("simple.py");
PyFunction func = (PyFunction)interpreter.get("search",PyFunction.class);
PyObject pyobj = func.__call__(new PyString(text));
System.out.println("结果: " + pyobj.toString());
}
/**
* String转换为Ascii字节 例如 '你好' 转换为: 228 189 160 229 165 189
*/
public static String stringToBytes(String content) throws UnsupportedEncodingException {
byte[] b = content.getBytes("UTF-8");
String text = "";
for(byte t:b) {
int n = 0;
if(t < 0)
n = 256+t; //中文转换为utf-8时 >255 变成负数
else
n = t;
text += n+" ";
}
return text.trim();
}
}
python代码:
#! /usr/bin/env python
# -*- coding: utf-8 -*-
import re
def search(text):
bytes = [int(x) for x in text.split(" ")]
b = "".join(map(chr,bytes)) # 转换为str
b = b.decode('utf-8')
if re.search(ur'中文', b):
return b+"-中存在关键字:'中文'".decode('utf-8')
else:
return b+"-中没有找到关键字:'中文'".decode('utf-8')
程序运行结果:
结果: Jython处理中文,还是有点烦恼!-中存在关键字:’中文’