主要介绍一些分类网络,并计算了FLOPS,参数个数和感受野信息,方便大家查询。
很多本人没有用过,另外也没有认真校对,有可能有错误
。
感受野的公式应该有错误,大家可以忽略
1 VGG-16
VGG[1]是非常经典的模型,是2014 ImageNet的亚军,其中当属VGG16应用最广泛。核心思想:小核,堆叠。主要分成5个stages,22333,13个卷积层,16的意思应该是加上3个FC层。每个stage后面都跟着一个pool来减小尺寸,参数方面fc占了很多,所以后面大多用conv或者global pool来代替。在做分割时,一般会把第四个pool的stride设成1,然后stage 5的conv用dilation conv来增加尺寸。192的感受野还是比较小的,并且按照一些论文的分析实际的感受野一般会比理论上的小很多,因此如果用它来做检测等任务的话,感受野也许这个是个问题。


2 Inception-V4
inception v1(Googlenet)应该是获得了image net 2014的冠军 vgg应该是亚军(有可能是vgg19),这个V4[2]版本是在2016年出来。在15年初还出现了一篇对深度学习网络影响比较大的论文,所以基本后面的网络都会在conv后面加BN,在caffe里一般会用两个层组合来实现这个功能bn/scale.所以画的图中用bsr来表示batchNormalization和relu的组合.Inception结构中嵌入了多尺度信息,集成了多种不同感受野上的特征,另外一个思想是将cross channelcorrelation和spatial corrections分离开。一般用1*1的pointwise conv去提取cross channel的信息,然后3*3或者其他大核去提取空间信息。可以从架构图中看出来Incetpion还是比较乱的,要设置的参数太多。

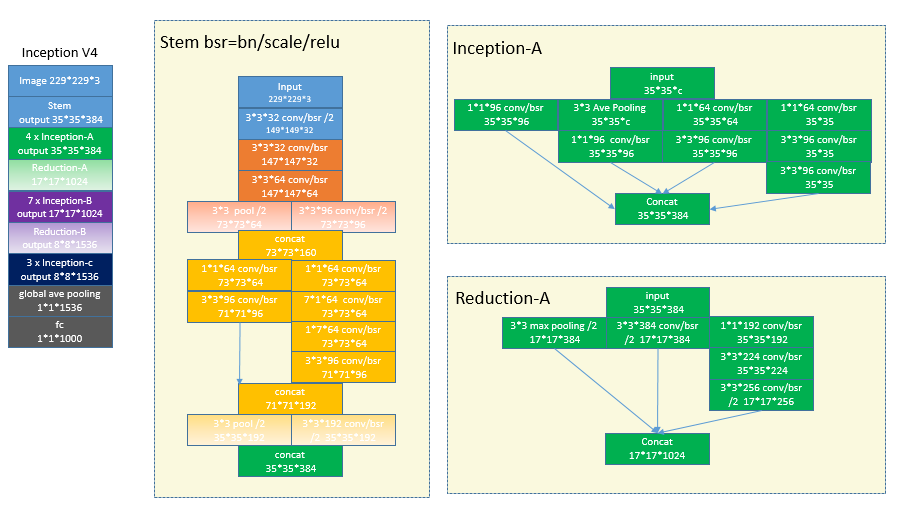
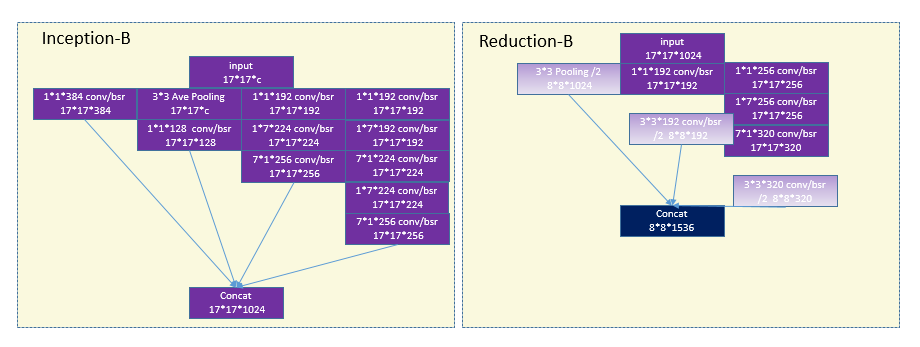
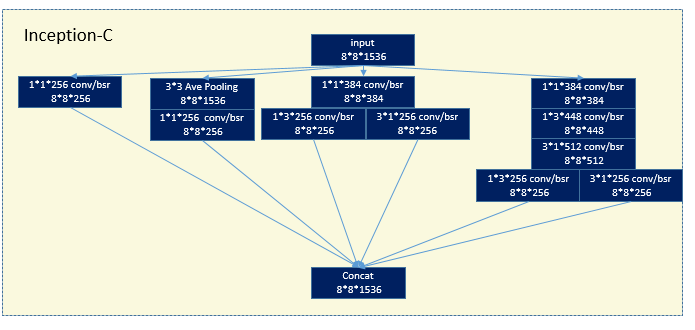

3 ResNet
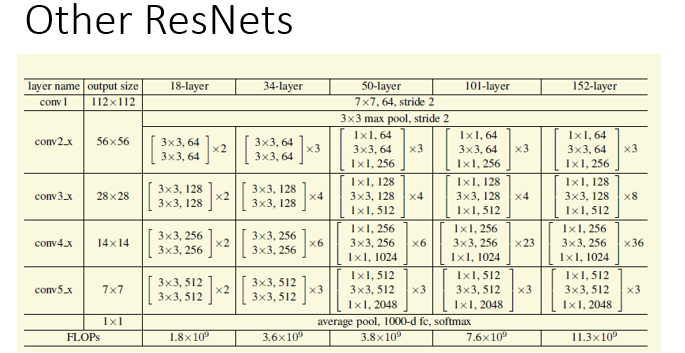
ResNet[3]是2015年image net的冠军。同等条件下,ResNet的速度和精度都会比VGG要好。个人觉得ResNet还是受到了Inception的启发,采用了多路的架构。但是ResNet有很好的解释性,它的核心是下面的ResUnitB.每一个这样的buildingblock都有一条通路加input通过某种方式叠加在输出中,就好比output = input+branch2,其中input和output类似,那么branch2就类似于一个残差的东西,因此就叫做残差网.之前没有注意细节,有次被人问到才注意到bottleneck的c是输出目标的1/4,我一直以为是输入的c,虽然这个在大多的情况是对的,但是在每个stage最开始变化c的时候就有问题了。



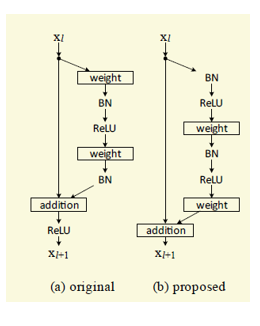
4 Identity mappings ResNet
在原始的ResNet中,左边的通道经过了Relu,因此并不是一个纯粹的等价映射通道,所以在这篇论文中作者利用了full pre-activation构建了一个Identity mapping[4]的building block来替换原有的,以便于信息和梯度传播,不过后面会介绍的WRN论文指出网络小于100层的用preActivation影响不太大。
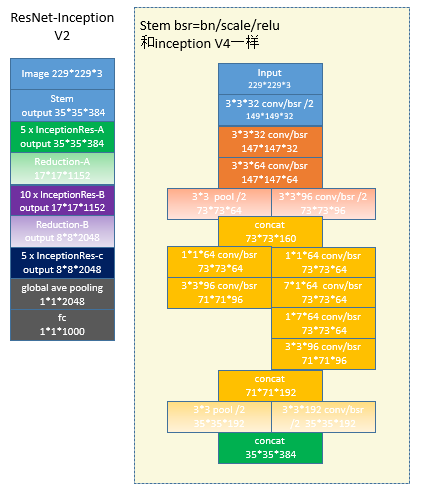
5 ResNet-InceptionV2
结合了Resnet和inception的思想[2]
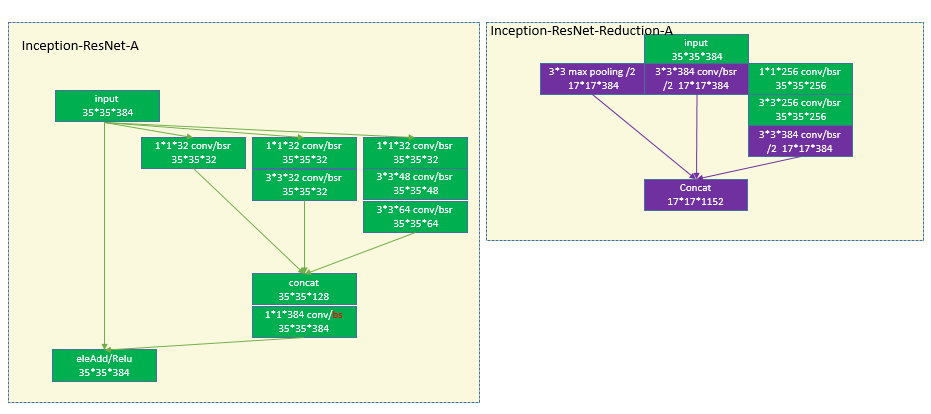
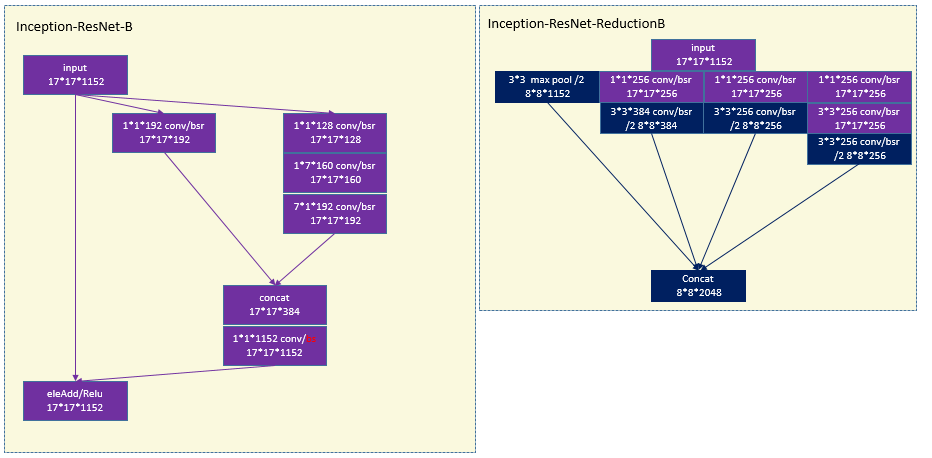

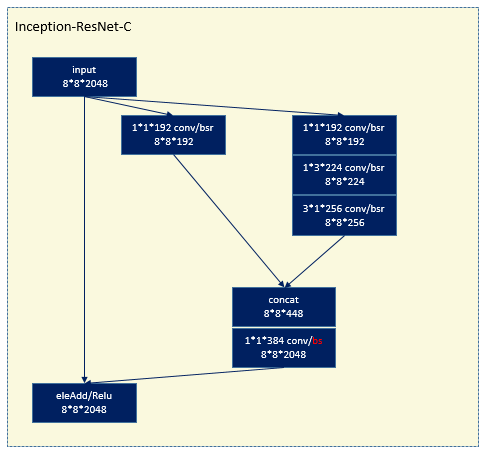
6 WRN (wide residual network)
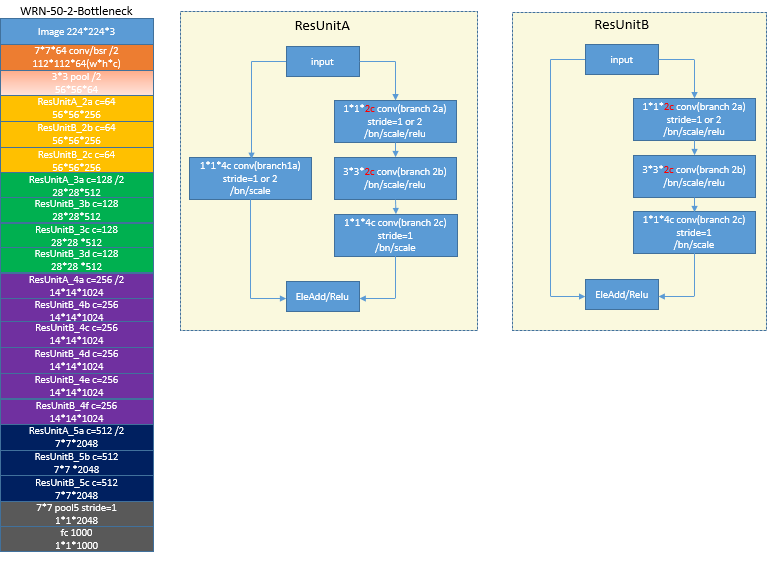
WRN[5]的思想非常简单,主要把ResNet的building block的channel增大,把网络变宽,从而能用不是很深的网络也能达到很好的效果.具体地说,比如对应于ResNet的1-3-1这样bottleneck架构,WRN就是把前两个卷积的通道数量增加了一倍,参考的是caffe版本,未对照是否与原作者的有出入.同时这篇论文还指出了bottleneck的架构也许更适用于imagenet,其他一些数据库可能使用其他的building block更合适些。

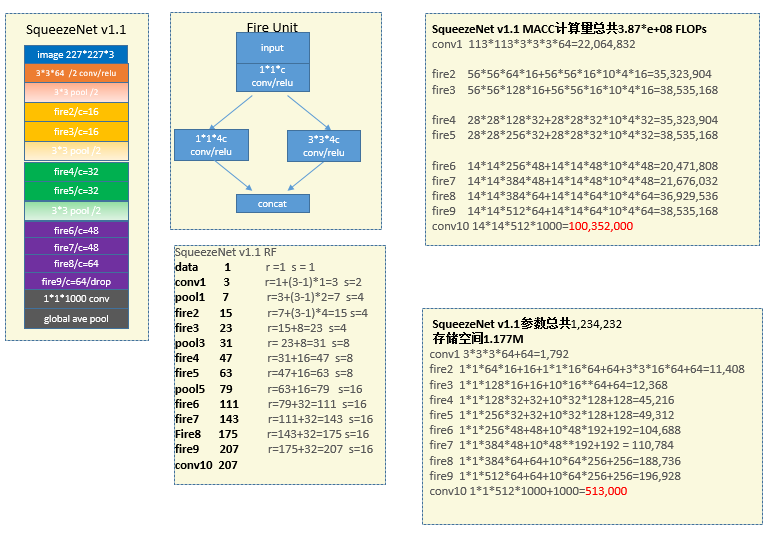
7 SqueezeNet V1.1
在把网络做宽做深的同时,为了一些物联网、移动应用,学术界也在研究精简网络架构,在不损失很多精度下减小model size和提高速度。当然有些分支是利用裁剪,权重量化等方法,不在这里的讨论范围。
SqueezeNet[6]主要利用三个思想。第一个是大量使用1*1卷积,这会造成空间关系提取的困难,因此在每一个fire unit有还有3*3的通路,其实也是inception的思想,一个提取空间,一个提取cross channel;第二个,通过bottleneck的方式降低3*3输入测channel数量;第三个,推迟下采样,使得后面的feature map的分辨率大一些。个人觉得还是降的挺快的,不过确实不想其他网络降到了32倍,squeezeNet只降到16倍。注意论文中作者还利用了其他方法对模型进行压缩,压到了0.5M.
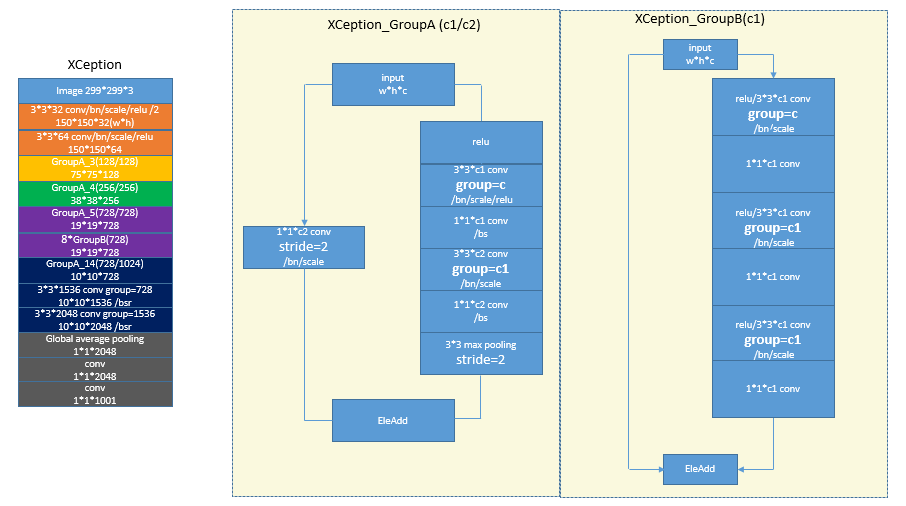
8 Xception
Xception[7]开始使用depthwise conv的方式提高速度和降低model size.它基于这样的假设,空间的联系和cross channel的联系可以完全独立。所以它用了3*3的depthwise conv的核提取空间关系,而用1*1的pointwise conv提取corss channel特征。另外它的building block应该也受到了[4]的影响,采用了Identity mapping的架构,而且感觉它的分辨率降得很快。Xception用的是keras或者tensorflow的实现,featuremap的大小是向上取整.下图中groupA3右侧多了个relu,画图方便,也不影响结果

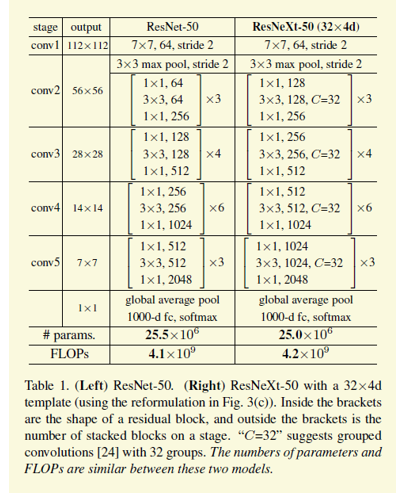
9 ResNetXt
ResNetXt[8]结合了WRN和group conv的思想。下图中的c就是group的数量。
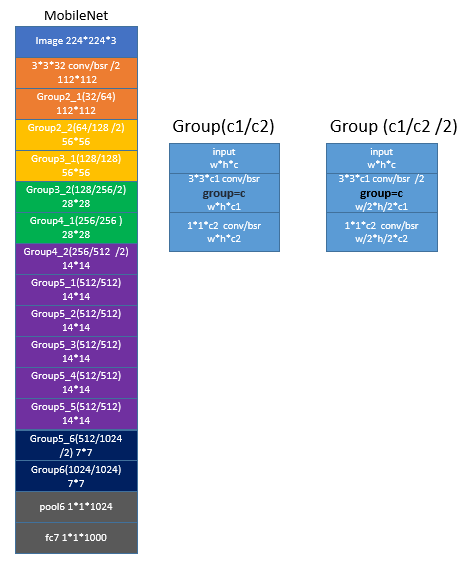
10 MobileNet
MobilieNet[9]的思想跟Xception一致,不过它的building block变简单了,没有采用residual结构

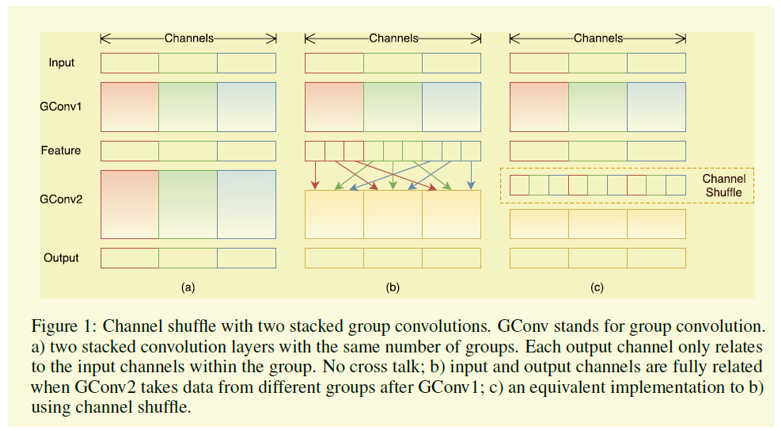
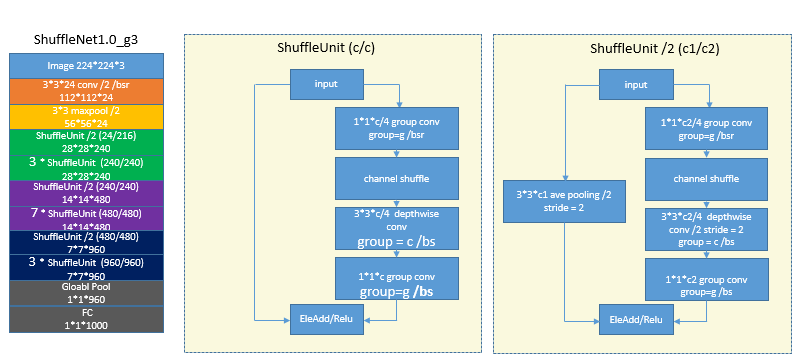
11 ShuffleNet
像上面的几种网络采用group conv后,很多计算都集中在1*1的conv,如果1*1的conv也能用group的话那对模型压缩和速度都有好处,但是不利于精度,因为cross channel的很多信息丢了,那怎么能提取cross channel的一些特征,作者就提出了shuffle的概念[10],比如原来有两组,第一组是1234通道,第二组是5678,那么重排后第一组是1526,第二组是3748,这样就还能拿到这些信息。

12 DenseNet
跟resnet的的基础模块不同,虽然也用了bottleneck的结构,densnet[11]用concat代替element add,因此输出的通道数量都比输入要多一些,论文中这个值一般是32。未优化下Densenet训练时特别耗显存.

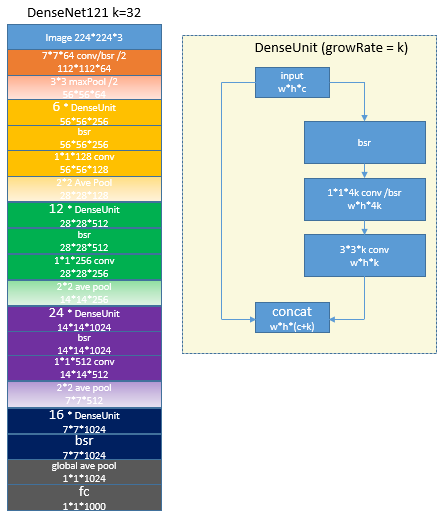

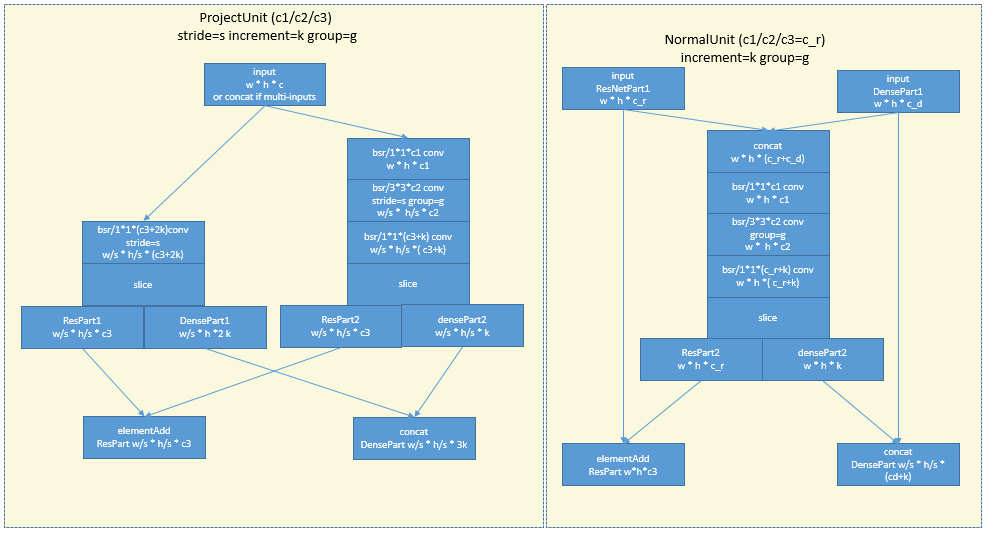
13 Dual PathNetwork
Dual Path Network[12]结合了ResNet和DenseNet.一个path照着ResNet把不同分支的特征element add,另外一个path照着ResNet把不同分支的特征concat.因此叫双路网络。

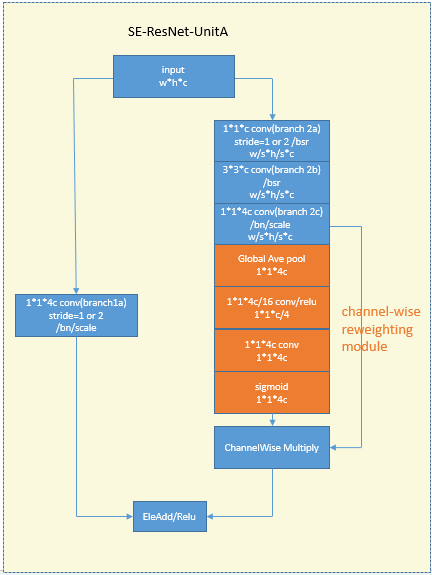
14 SENet
SENet[13]设计了一个gating(reweighting)模块让网络可以自学习各个channel的权重。下图展示的是将SE block加入到了ResNet UnitA中的情况。大体的意思还是比较好理解。
15
Deformable Convolutional Networks【未开始】
参考
[1]Simonyan K, Zisserman A. Verydeep convolutional networks for large-scale image recognition[J]. arXivpreprint arXiv:1409.1556, 2014.
[2]Szegedy C, Ioffe S, Vanhoucke V,et al. Inception-v4, Inception-ResNet and the Impact of Residual Connections onLearning[C]//AAAI. 2017: 4278-4284.
[3]He K, Zhang X, Ren S, et al.Deep residual learning for image recognition[C]//Proceedings of the IEEEconference on computer vision and pattern recognition. 2016: 770-778.
[4]He K, Zhang X, Ren S, et al.Identity mappings in deep residual networks[C]//European Conference on ComputerVision. Springer International Publishing, 2016: 630-645.
[5]Zagoruyko S, Komodakis N. Wide residualnetworks[J]. arXiv preprint arXiv:1605.07146, 2016
[6]Iandola F N, Han S, Moskewicz M W, et al.SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and< 0.5 MBmodel size[J]. arXiv preprint arXiv:1602.07360, 2016.
[7]Chollet F. Xception: Deep Learning with DepthwiseSeparable Convolutions[J]. arXiv preprint arXiv:1610.02357, 2016.
[8]Xie S, Girshick R, Dollár P, et al. Aggregated residualtransformations for deep neural networks[J]. arXiv preprint arXiv:1611.05431,2016.
[9]Howard A G, Zhu M, Chen B, et al. Mobilenets: Efficientconvolutional neural networks for mobile vision applications[J]. arXiv preprintarXiv:1704.04861, 2017.
[10]Zhang X, Zhou X, Lin M, et al. ShuffleNet: An Extremely EfficientConvolutional Neural Network for Mobile Devices[J]. arXiv preprintarXiv:1707.01083, 2017.
[11]Huang G, Liu Z, Weinberger K Q, et al. Densely connectedconvolutional networks[J]. arXiv preprint arXiv:1608.06993, 2016.
[12]Chen Y, Li J, Xiao H, et al. Dual PathNetworks[J]. arXiv preprint arXiv:1707.01629, 2017.
[13]Hu J, Shen L, Sun G. Squeeze-and-Excitation Networks[J]. arXivpreprint arXiv:1709.01507, 2017.