10张表导入的ktr文件–》可以参考一下
链接:https://pan.baidu.com/s/1Ho9xrXItA5vSaMpH40NhKA
提取码:evzq
复制这段内容后打开百度网盘手机App,操作更方便哦
导出parquet输出文件
1、在mysql创建10张表,并且导入数据
2、在hive中创建10张表(注意表是否分区)
3、使用kettle把mysql的数据导入到hive中
使用到的组件
表输入、
字段选择、
parquet output
流程图

1、表输入配置
表输入sql语句
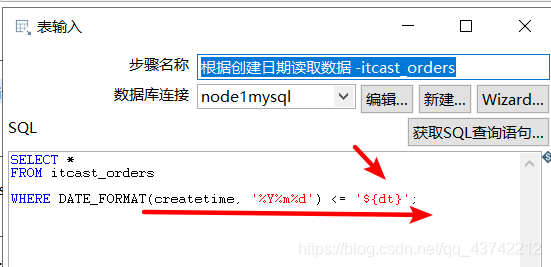
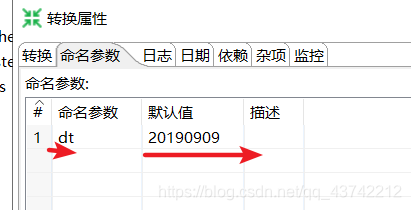
注意:${dt}是设置好的命名参数(双击空白处就能设置命名参数)
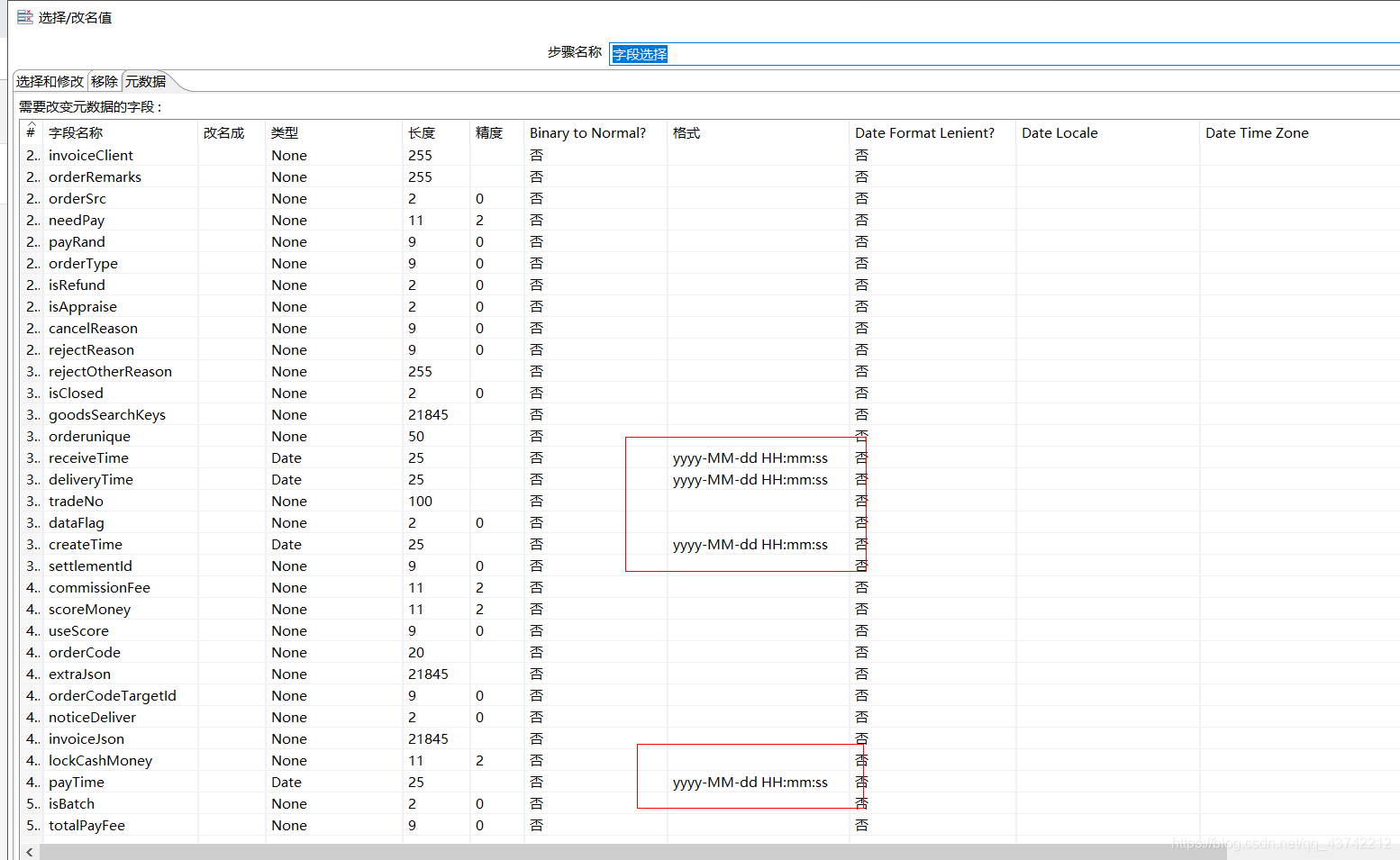
2、字段选择
注意:字段选择的字段顺序和字段类型要和创建的表一致
字段选择指定日期格式
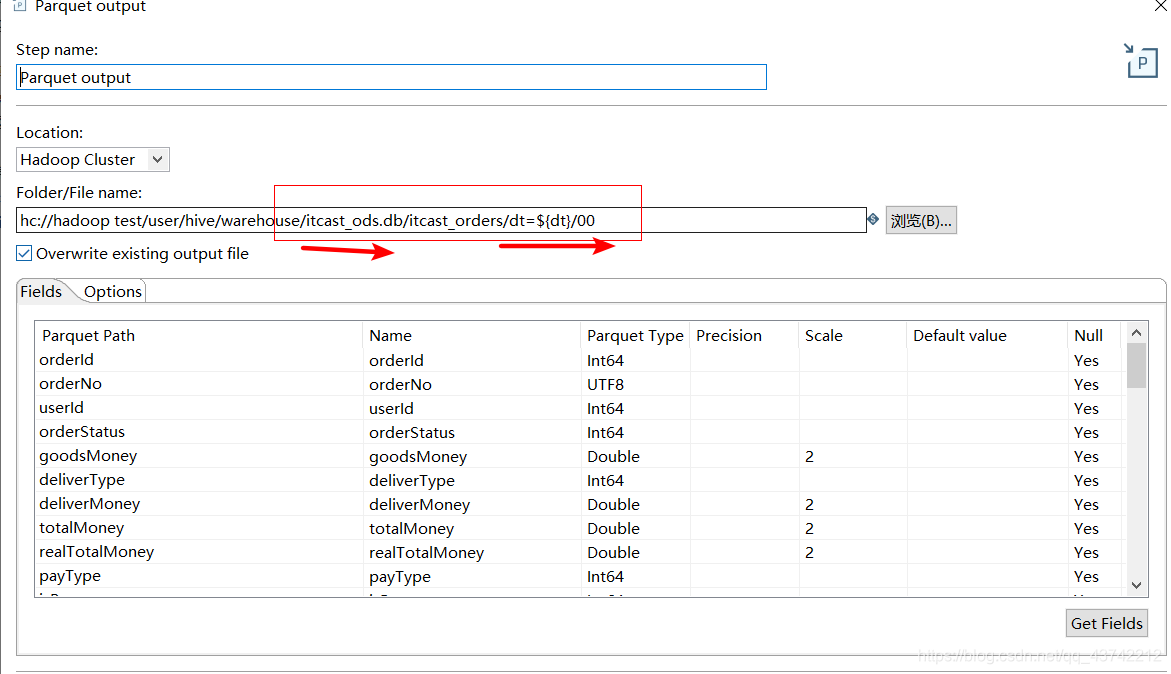
3、Parquet output
建表语句
create table`itcast_order_goods`(
ogId bigint,
orderId bigint,
goodsId bigint,
goodsNum bigint,
goodsPrice double,
payPrice double,
goodsSpecId bigint,
goodsSpecNames string,
goodsName string,
goodsImg string,
extraJson string,
goodsType bigint,
commissionRate double,
goodsCode string,
promotionJson string,
createtime string
)
PARTITIONED BY ( `dt` string)
STORED AS PARQUET;
注意:PARTITIONED BY ( `dt` string)是表指定字符串dt分区
STORED AS PARQUET;是指定导入的文件格式为PARQUET
这里创建的表语句是指定dt分区的
注意:1、在运行之前在hive对应的数据库下创建表,这里是hive里的test数据库创建表)
2、如果创建的表设置了分区,浏览对应的hdfs路径要变成表名/dt=字符串/文件名
,没有设置分区也就不需要/dt=字符串(本项目设置分区)
3、设置分区需要修复分区,没有不需要修复分区
配置文件路径,有分区:
设置snappy压缩输出
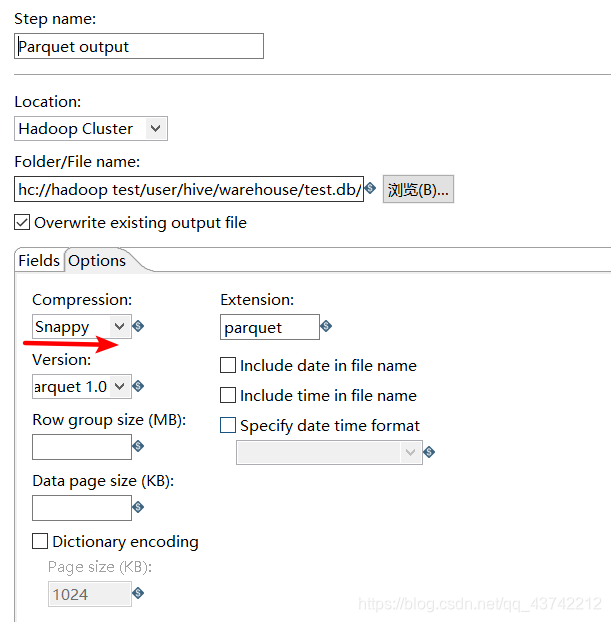
(如果hive表设置了分区,输出的parquet路径也要对应,同时要修复分区)
修复分区
流程图
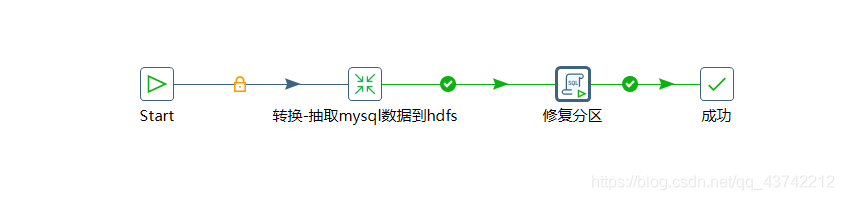
修复分区
设置hive数据库
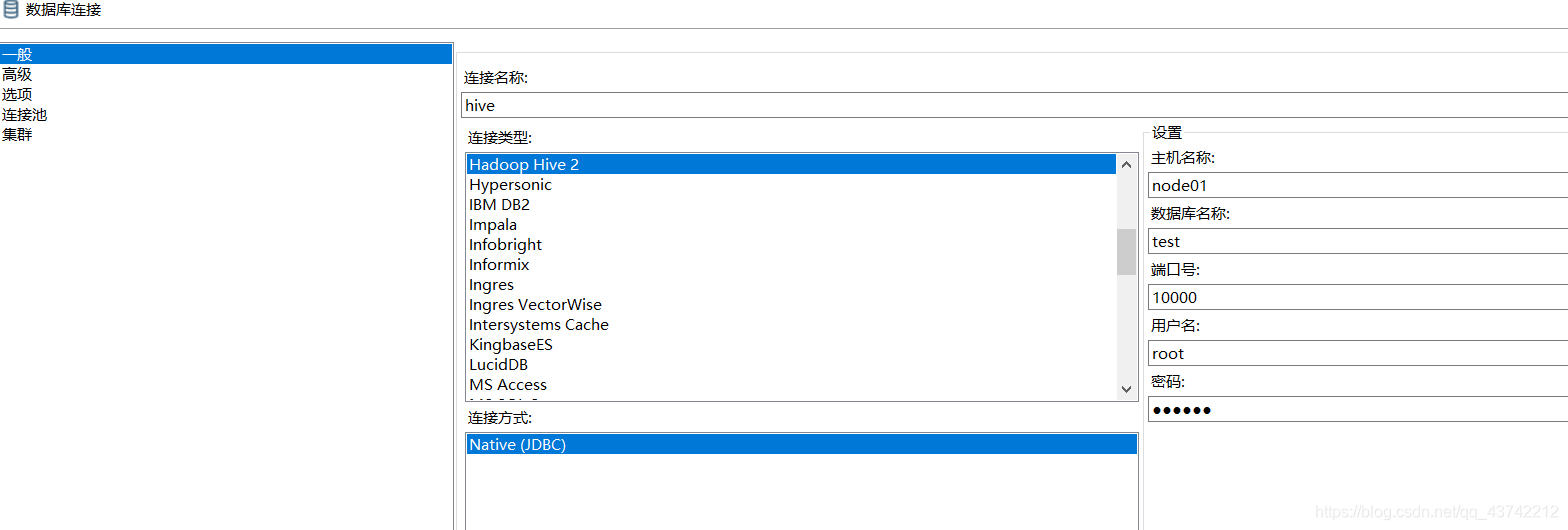
设置hive要修复的数据库下的表

版权声明:本文为qq_43742212原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。