1024
这个数字,想必计算机行业从业人员应该不会陌生,甚至
10月24日
还被当做
程序员日
,如果你问一个程序员
1GB
等于多少
MB
,他大概率会不假思索回答:
1024
。
没错,对于稍微对计算机或者网络有了解的人,一般都认为
1024
是数据容量单位换算的倍数,例如
1GB = 1024MB
、
1MB = 1024KB
、
1KB = 1024B
…然而实际情况并非如此,里面有很多历史遗留问题。
bit/比特
是
binary digit
(二进制数位)的简称,中文音译读作
比特
,也可以叫
二进制位
、
位
、
位元
。指二进制中的一位,即
0
或
1
,是计算机内部数据储存的
最小单位
,也可缩写为
b
。
我们电脑中存储的各种文件,网络请求发送的数据包,本质上都是
0
和
1
的组合。 多个
bit
组合在一起就可以表示出不同的值
| bit数量 | 可表示的值(二进制) |
|---|---|
| 1 |
0、1 (2 1 ) |
| 2 |
00、01、10、11 (2 2 ) |
| 3 |
000、001、010、011、111、110、100、101 (2 3 ) |
N位bit可以组合表示出2
N
个不同的值。
byte/字节
中文译为
字节
,也可以叫
位组
、
位元组
。可缩写为B
字节的定义
是一种计算机领域中的
信息计量单位
,是针对
通信与数据存储
时的一个概念。当我们使用字节来描述某一段信息或数据时,我们并不用去考虑该段信息是属于何种数据类型。
byte一词的由来
byte
一词是
Werner Buchholz
于1956年6月在
IBM Stretch
计算机的早期设计阶段发明的,其英文
byte
来源于
Bite
(咬)一词,为了与
bit
做一区分,特地变‘i’为’y‘,成为我们今天所看到的
byte
,也可简写为大写
B
字节在诞生伊始,其目的仅是
表示用于编码单个字符所需要的比特(bit)数量
,并且在不同的应用中或使用不同的编码方式时,这一数量的大小也不尽相同。
1字节 = 8 比特 ?
当我们提起字节
(byte)
这一概念时,很多人都会下意识的想到
“一个字节等于八个比特”
这一公理。那么一个字节是否真的就等于八个比特呢?
历史上字节长度曾基于硬件为
1-48
比特不等,之后有一段时间则常使用
6比特
或
9比特
为一字节。
如果计算机完全以二进制工作,并且只对二进制数字进行了计算,那么就不会有字节。但如果要使用字符,我们就必须对这些符号进行编码。
在计算机出现早期,我们只需要使用计算机来处理整数运算,所以也只需要编码数字0-9十个字符,再加上加号’+‘与减号’-‘两个算数运算符,共计11种字符,此时我们只需4比特来进行编码就足够表示了。再后来我们又需要对字母进行处理,大小写字母加上数字,再加上例如逗号等标点符号,这时大概有了70多种字符,此时我们需要7比特来进行编码才能够表示完全。
而之所以最后确定
8bit
是
1Byte
,而不是
7bit
,可能是因为当时
IBM
的
360系统
使用
8位字符
,并且
byte
这个词被大量使用,且
8是2的幂次方
,比7更加适合
2进制
的计算机(Powers of 2 are magic!),所以最后大家就都接受了
1byte=8bit
。
Octet
Octet
定义为由八个比特组成的信息单位,中文译作
八位组
。
在今天的语境下,一般认为
1byte = 8bit
,但是上面说了,其实严格来说
1byte
并不等于
8bit
,所以
Octet
诞生了,用来表示八位字节,即
8bit
。
Octet
可简写为
o
,
1MB
可写为
1Mo(兆八位字节)
,
1KB
可写为
1Ko(千八位字节)
,不过这种写法一般在
byte
代表的
bit
数量不明确,可能出现歧义,需要明确
1byte = 8bit
时使用!
发展
随着科技和硬件的发展,内存变得越来越大,使用
byte
为单位来标识容量将会显得很大,比如
4096byte
,不利于阅读,于是人们想到了进位,就像
m
进位到
km
(1km=1000m)、
g
进位到
kg
(1kg=1000g),那么按理说
byte
也可以像其他国际制单位一样,以
10进制的1000
(10
3
)进位,即
1kB = 1000B
,那么为什么最后却变成以
2进制的1024
(2
10
)进位呢?
注意:严格来说
k
在
IS(国际单位制)
中代表千,即10
3
,书写应为小写,非正式场合也可以使用大写
K
,但在日常书写中,大写
K
更普遍被人们使用
1024进制的由来
那当初到底为什么出现了
1024
呢?其实这个问题和计算机内存的
寻址系统
有关。
所谓
寻址
,就是
寻找内存里面特定的地址
,就像按编号找到众多储物柜中的某一个。
CPU
里面有一个东西叫
“地址总线”
,这个东西用来
编码
要访问的
内存地址
,也就是储物柜的编号,例如
001
、
010
。
地址总线就是一堆电线,一个CPU有N根地址线,那么可以说这个CPU的地址总线的宽度为N。跟CPU里的其他元件一样,每一根都只能表示
0
或者
1
,也就是说,它也是用二进制来工作的。那么,地址总线有多少根,就决定了CPU能编码多少内存地址,这个范围就叫做CPU的寻址能力。
我们可以算一下,如果地址总线数量是1,能编码的内存地址就是
0
或者
1
、也就是2个,即2
1
,;地址总线数量是2,能编码的内存地址就是
00
、
01
、
10
、
11
,也就是4个,即2
2
;以此类推,地址总线数量是
N
,CPU的寻址能力就是2
N
既然CPU的寻址能力是按
2的幂
计算的,也就是说CPU只能编码2
N
个内存地址,那么内存的容量也就应该按
2的幂
来设计,这样才能跟CPU的寻址能力匹配。比如说,一块CPU的地址总线数量为10,它的寻址能力是2
10
次幂,也就是1024,即
0000000000
、
0000000001
、
0000000010
、
0000000011
…
1111111111
。如果设计内存的人按1000、2000、3000这样来设计内存容量,那永远也找不到合适的对不对?于是,内存容量就都被设计成了
2的幂
,以这里的10个总线为例,就是内存容量需要是1024的倍数。
上面说到,最早人们也是考虑像其他国际制单位一样,以
1000
进位,但是因为内存寻址的机制,最后选择了
2的幂
,即
1024
,而且那时候内存容量也小,以
MB
为单位,1024又比较接近1000,
1MB=1024KB
还是
1MB=1000KB
,误差并不是很大,所以就将1024看做近似1000使用。
混乱出现
你可能疑问,既然大家都是以二进制的
1024
为基准进行进位,哪儿来的误差?恰巧,问题就出现在这里。磁盘(软盘、硬盘)从一开始就没有类似
内存寻址
这个问题,因为:
第一
,磁盘的寻址和CPU的架构没有关系(磁盘访问由操作系统负责);
第二
,磁盘的基本存储单位是“扇区”,而不是单个字节,一个扇区的容量不是固定的。这就意味着,磁盘容量没必要非要按
2的幂
去凑整,而是可以怎么方便就怎么来。
IBM个人电脑上用的软盘为了迎合内存容量的二进制习惯,规定一个扇区的容量是
512字节
,那么两个扇区的容量就是
1024字节
,也就是
1kB
。因此,我们以前用的
360kB
、
720kB
的软盘,它们的
1kB
都代表
1024
字节,但后来出现的
高密度软盘
,容量写的是
1.44MB
,按
1MB=1024KB
换算应该是
1.44*1024=1474KB
,但实际上它的容量是720kB软盘的两倍,即
1440KB
,是按
1MB=1000KB
换算的,在这个节骨眼上,软盘厂商居然玩起了精分,让1KB=1024B,而
1MB=1000KB
,真是又一笔糊涂账
相比之下,硬盘厂商就专一多了。硬盘因为容量大,一开始就是
MB
尺度了。从20世纪70年代起,硬盘厂商在标示容量时就是按
1000
进位计算的,而这种标准沿用了几十年,到今天也依然是雷打不动。
这笔糊涂账让做操作系统的很是为难。毕竟,
内存容量和磁盘容量的算法不一样
,你让操作系统怎么显示才好呢?结果呢,当初几乎所有的操作系统都采用了内存的
二进制标准
,也就是按
1024
进位,那么磁盘容量也就跟着保持一致,也按照1024进位来计算,于是
系统显示
的容量就和
硬盘上标示
的容量有差距了。
还有更混乱的,在
windows
系统中,系统以
1024
对硬盘容量进行换算显示,而在
MAC OS
和
Linux
中系统又是以
1000
进行换算的,好嘛,真是乱上加乱!!!
如果分别以
1024
和
1000
进行换算,误差在
24/1000=2.4%
,在那个计算机还不发达的年代,似乎并不会有太大的问题,但是随着计算机的发展,硬盘容量越来越大,单位也由
MB
发展到
GB
、
TB
,
在
TB
这个量级,误差已经被放大到
9.95%
,这也是为什么我们买的标识为
500GB
硬盘在电脑上显示
小于500GB
的原因。
1956年IBM公司制造出世界上第一块硬盘350RAMAC,不是GB为单位,而是以MB为单位,大小为5MB。
改变
1KB
有时是
1000
字节,有时又是
1024
字节,这件事实在是太混乱了。而根据
国际单位(SI)
的规定,
k、M、G
等等这些前缀之间的倍率关系都是
1000
,那么用
1024
就明显和
SI是矛盾
的。于是,
国际电工委员会(IEC)
想了一个方案,说那这样好了,凡是需要表示
1024
进位的,就用另外一套写法:
Kibibyte
(giga binary byte的缩写)、
Mebibyte
、
Gibibyte
,可简写为
Ki、Mi、Gi
,
i
为
binary(二进制)
缩写,换算关系如下:
| 2进制 | 10进制 |
|---|---|
| 1Kibibyte = 1KiB = 1024B | 1Kilobyte = 1KB = 1000B |
| 1Mebibyte = 1Mib = 1024Kib | 1Megabyte = 1MB = 1000KB |
| 1Gibibyte = 1Gib = 1024Mib | 1Gigabyte = 1GB = 1000MB |
| 1Tebibyte = 1Tib = 1024Gib | 1Terabyte = 1TB = 1000GB |
后来,
IEC
的这个方案变成了
国际标准(ISO)
,所以严格来说,表示1024进位的时候一定要用IEC的这套新的前缀。比如硬盘若以
1000
进位,则应标注为
500BiB
。然而实际情况是,现在硬盘厂商是按
1000
换算且标识为
GB
或
TB
,是对的,而电脑系统却是以
1024
进行换算,但又显示的是
GB
或
TB
;内存条是按
1024
换算的,但是标识的是
GB
,标识单位错误


Mac OS
倒是以
1000
进位的,但是单位却是
GB
,害,真让人哭笑不得😂
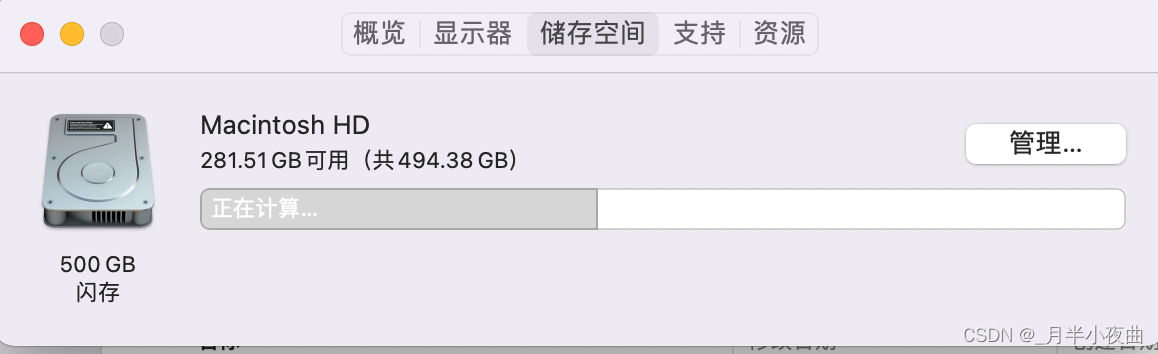
不过好像
Linux
系统做的好一点
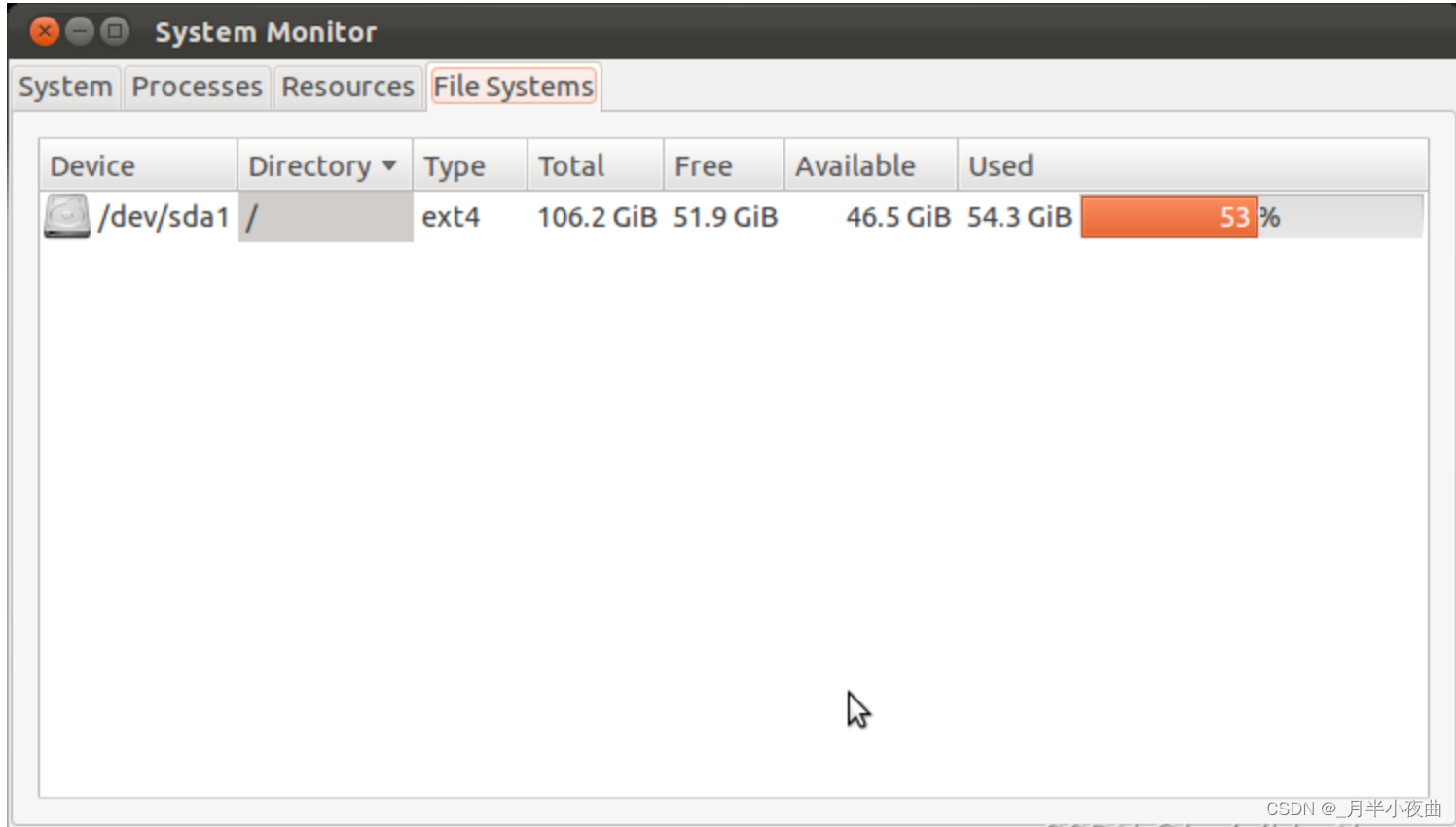
没办法,这都是历史遗留问题,大家都用习惯了,希望有一天可以统一标准!!!
其他
在通信行业,我们经常听到
千兆宽带
这个词,或者看到宣传页上写的
1000M宽带
,家里装了
500M
的宽带,但是下载游戏却只有每秒几十兆,这是怎么回事呢?
通信行业的基础是传输,而传输的基本单位是二进制码元,也就是bit,以通信中传输速率的单位是
bps(bit per second)
,也就是
bit/s
(每秒多少比特)。传输是的速率可能为任意整数,不一定为2的倍数,所以没有必要使用
K=1024
这种人类不擅长的二进制,而是使用
K=1000
的十进制形式,即 1B= 8b(这个是不变的),1KB = 1000B,1MB = 1000KB,1GB = 1000MB。
所以在描述带宽时,1000兆宽带的正确写法应该是
1000Mbps
或者
1Gbps
,这里的
b
为小写,代表
bit
,
M
和
G
代表
百万
(10
6
),所以
1000Mbps
带宽就代表理论上,每秒可传输1000/8 * 10
6
= 125 * 10
6
B =125 * 10
3
KB = 125MB的数据,也就是理论上网速最快为
125MB/s
,这里计算除以8其实就是将
b
换算为
B
,最后除1000换算成
KB
和
MB

一个字节(Byte)一定等于八个比特(Bit)吗
一字节为什么等于八比特?
KB和kb,傻傻分不清楚
电脑里的1kB到底是1000字节还是1024字节?
KB/KiB,MB/MiB,GB/GiB,它们的区别