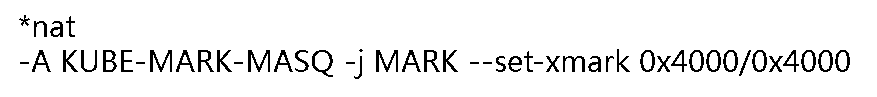本次分析的kubernetes版本号:v1.2.1-beta.0。
Kubernetes中kube-proxy组件负责维护NODE节点上的防火墙规则和路由规则,Kube-proxy有两种实现方式,一种是通过iptables,一种是通过userspace,在1.2中将使用iptables作为首选,可以大幅提升性能,下面看看kube-proxy组件是如何操作iptables的。
kube-proxy要求NODE节点操作系统中要具备/sys/module/br_netfilter文件,而且还要设置bridge-nf-call-iptables=1,如果不满足要求,那么kube-proxy只是将检查信息记录到日志中,kube-proxy仍然会正常运行,但是这样通过Kube-proxy设置的某些iptables规则就不会工作。
在源代码中有检查iptables版本是否低于1.4.11的校验,如果iptables版本低于1.4.11,那么不能使用-C/–check这个参数,这样可以保证kube-proxy对iptables版本的向下兼容性。
Iptables默认的数据包流向图如下图所示:
在iptables模式下,kube-proxy使用了iptables的filter表和nat表,并且对iptables的链进行了扩充,自定义了KUBE-SERVICES、KUBE-NODEPORTS、KUBE-POSTROUTING和KUBE-MARK-MASQ四个链,另外还新增了以“KUBE-SVC-”和“KUBE-SEP-”开头的数个链。
在iptables表中,通过iptables-save可以看到在filter表和nat表中创建好的这些链,下面是示例:
Kube-proxy配置iptables的过程通过syncProxyRules函数来执行的,首先在filter表和nat表中检查并创建KUBE-SERVICES和KUBE-NODEPORTS两个链,然后在filter表中插入一条iptables规则,将OUTPUT链的数据包导入KUBE-SERVICES链,另外在nat表中插入两条iptables规则,将OUTPUT链和PREROUTING链的数据包导入KUBE-SERVICES链;接着在NAT表中创建KUBE-POSTROUTING链,然后再NAT表中插入一条iptables规则,将POSTROUTING链的数据包导入KUBE-POSTROUTING链。
在iptables表中,通过iptables-save可以看到在nat表中创建好的规则,下面是这些规则的示例:
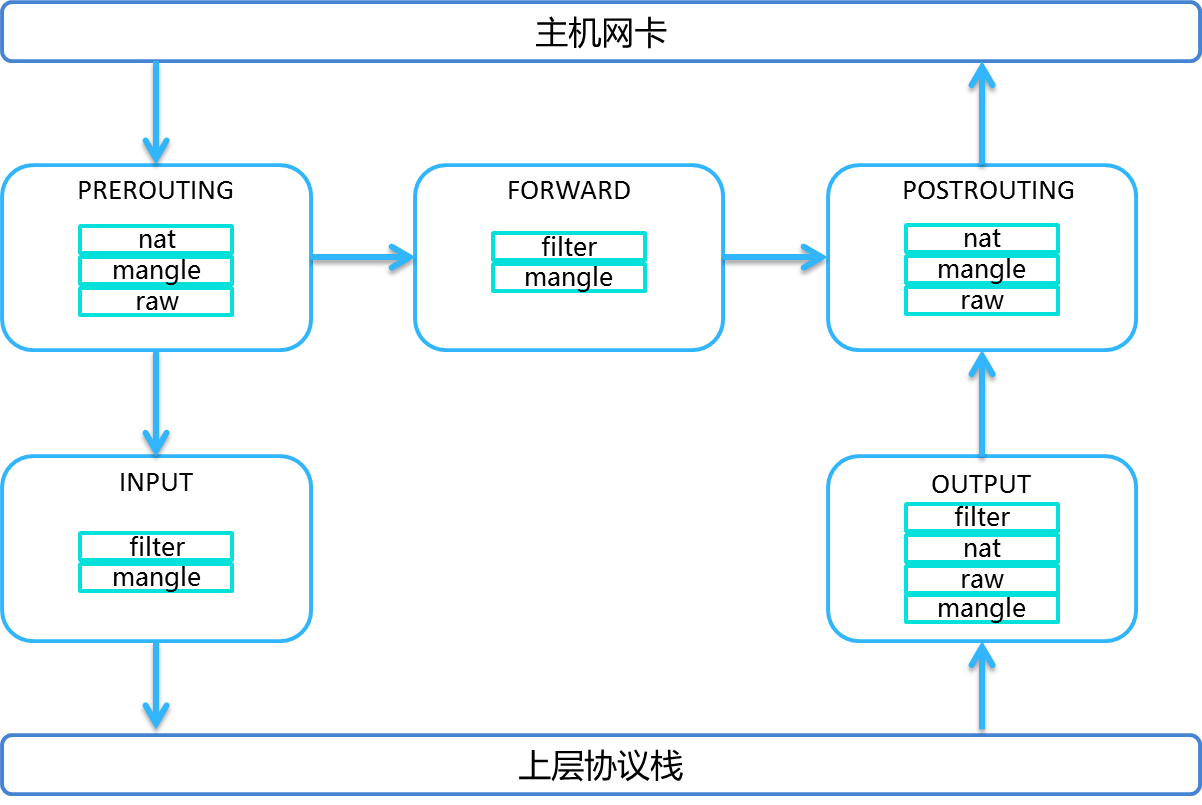
syncProxyRules函数在创建完上面iptables自定义链和规则后,调用操作系统命令iptables-save –t filter和iptables-save –t nat将filter表和nat表中内容保存到程序缓存中,在程序缓存中添加KUBE-MARK-MASQ链。
对于KUBE-MARK-MASQ链中所有规则设置了kubernetes独有MARK标记,在KUBE-POSTROUTING链中对NODE节点上匹配kubernetes独有MARK标记的数据包,进行SNAT处理。
在iptables表中,通过iptables-save可以看到在nat表中创建好的规则,下面是规则示例:
Kube-proxy接着对每个服务创建“KUBE-SVC-”链,并在nat表中将KUBE-SERVICES链中每个目标地址是service的数据包导入这个“KUBE-SVC-”链;如果service使用到了NODE节点端口,那么将KUBE-NODEPORTS链中每个目的地址是NODE节点端口的数据包导入这个“KUBE-SVC-”链;如果service没有配置endpoint,那么REJECT所有数据包,这意味着没有endpoint的service是无法被访问到的。如果service已经配置了endpoint,那么对每个endpoint创建“KUBE-SEP-”开头的链,并在“KUBE-SVC-”链中创建iptables规则,将所有“KUBE-SVC-”链中的数据包都导入“KUBE-SEP-”开头的链中,接着在每个“KUBE-SEP-”链中创建iptables规则,其中一条规则就是对所有由endpoint发出的数据包都导入KUBE-MARK-MASQ链中,如果一个service有多个endpoint,那么就采用随机方法将数据包导入不同的“KUBE-SEP-”开头的链中,其实如果一个service对应多个endpoint(相当于一个service对应多个POD),其实就意味着要实现负载均衡,默认情况下是采用随机的方法从“KUBE-SVC-”链向“KUBE-SEP-”链转发数据包,但是如果service的sessionAffinity配置成了ClientIP,那么在一定时间范围内向“KUBE-SVC-”链请求的数据包都会发给固定的“KUBE-SEP-”链,通过这种方式实现业务应用的会话保持。
接着删除程序缓存中已经不存在的“KUBE-SVC-”链和“KUBE-SEP-”链,最后添加一条iptables规则目的地址是本地的数据包导入KUBE-NODEPORTS链中。
在iptables表中,通过iptables-save可以看到在nat表中创建好的“KUBE-SVC-”链和“KUBE-SEP-”链,以及这些链中的规则,下面是这些规则示例:
如果一个service后端有多个POD,那么在iptables表中通过iptables-save可以看到,下面是使用负载均衡后的规则示例:
通过上面规则示例可以看到service如何向后端POD负载均衡分发数据包。
在负载均衡实际使用中,最常用的还有会话保持功能,也就是说一个客户端同服务器端建立会话连接之后,要保证这个会话连接,通过iptables来实现就需要使用recent模块,kube-proxy会使用“-m recent –rcheck –seconds 180 –reap”命令来实现会话保持,目前还无法配置会话保持的持续时间,因为kube-proxy在代码中写成了180秒,期待以后可以作为参数传入。
Kube-proxy将程序缓存中的iptables规则通过iptables-restore命令更新到NODE节点操作系统中。
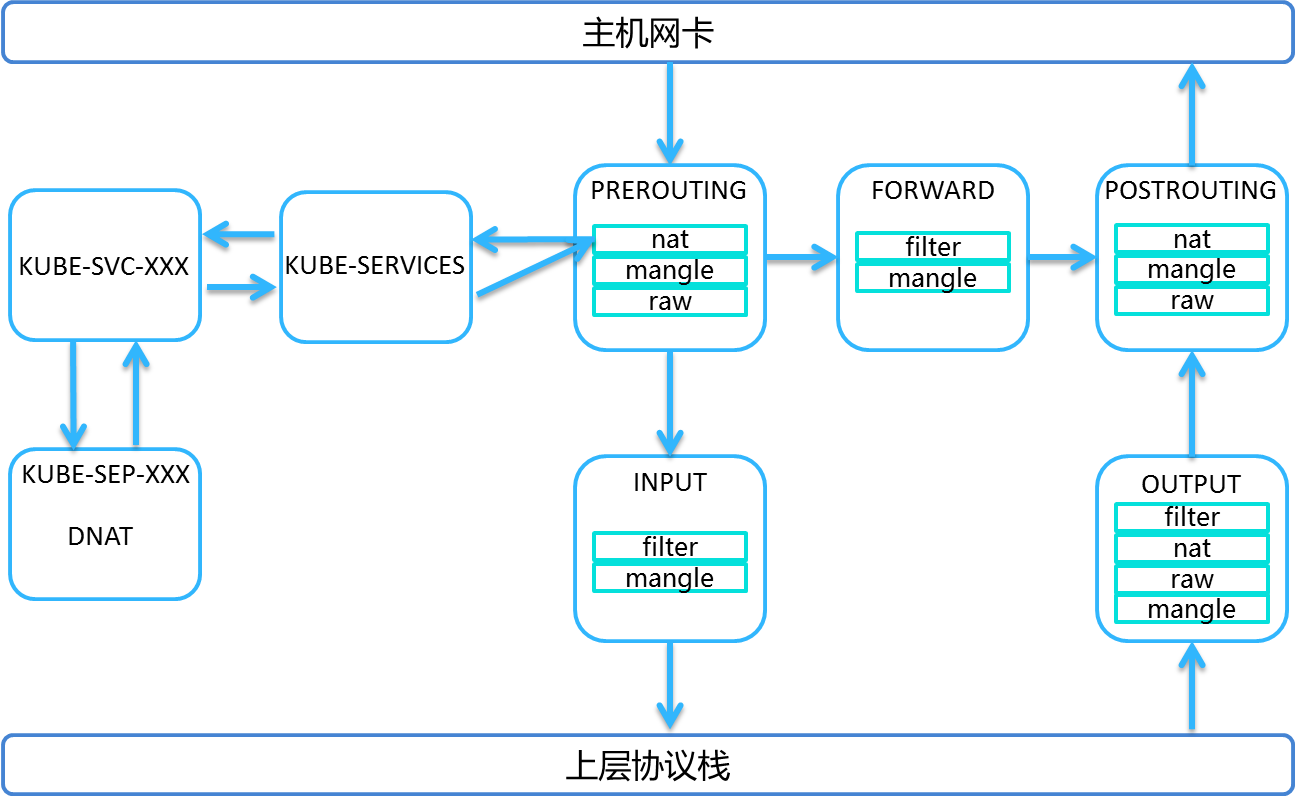
Kube-proxy配置后的Iptables数据包流入图如下:
从这张图上可以看到,从主机网卡上得到的数据包在经过PREROUTING链的nat表时,被导入kube-proxy的KUBE-SERVICES链,然后被导入KUBE-SVC-XXX链,这里的XXX表示十六位字符,是由SHA256 算法生成哈希值后通过base32进行编码,然后取16位,最后数据包被导入KUBE-SEP-XXX,数据包被DDAT到一个POD上,然后返回到PREROUTING链中,如果不需要路由,那么发送给本地上层协议栈,否则路由出主机网卡。
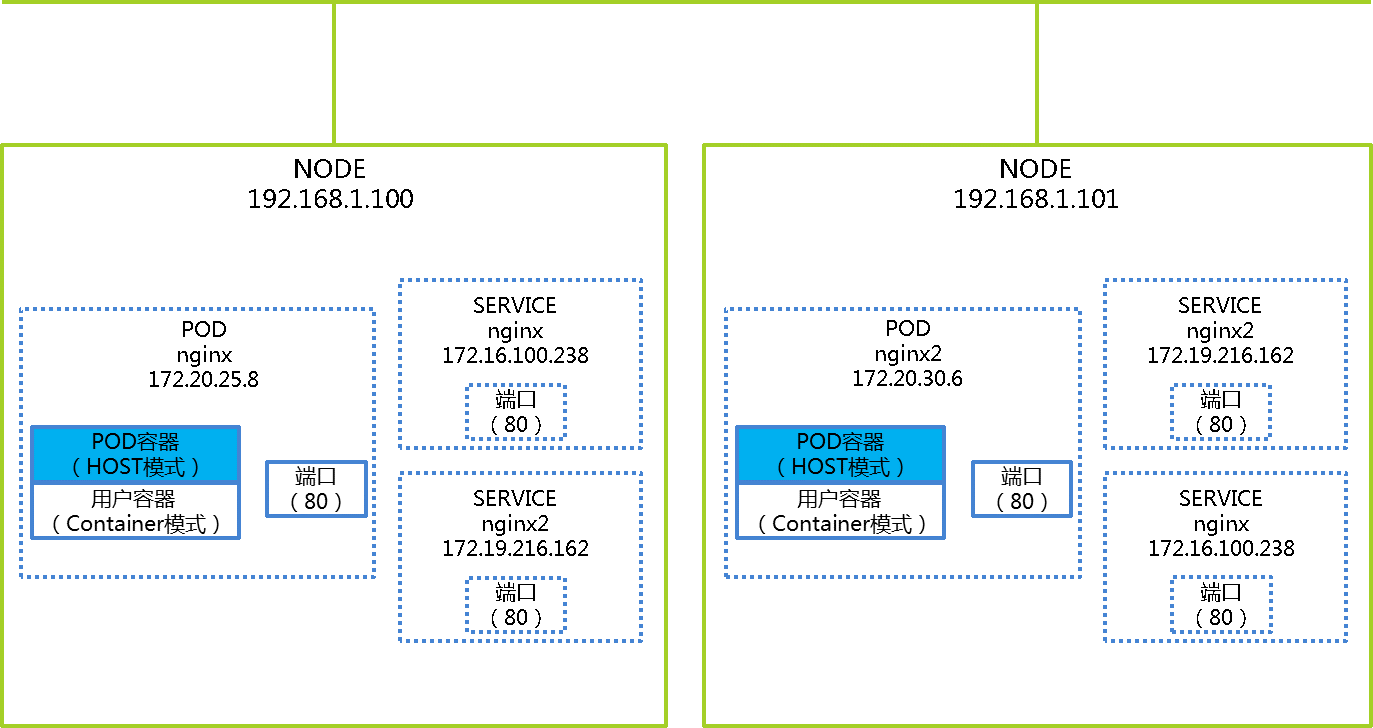
下面是kubernetes环境下NODE节点、service、POD和Docker容器的示意图,用于形象的展现这四者之间的关系。
在这个kubernetes环境下有两个NODE节点,IP分别是192.168.1.100和192.168.1.101,有两个ClusterIP模式的service,IP分别是172.16.100.238和172.19.216.162,每个service对应一个POD,在每个POD中。
从上图中可以看到在每个NODE节点上都会存在service,service在物理上是不存在的,只是在iptables中,POD在物理上也是不存在的,只是一个概念,这个概念是由POD中POD容器来实现的,POD容器是物理存在的。在ClusterIP模式下,POD容器采用HOST模式创建,用户容器采用Container模式创建,也就是说用户容器同POD容器共享网络命名空间、IPC命名空间和文件系统命名空间,通过引入POD容器来实现逻辑上POD概念。
在名称是nginx的POD上,用户容器如果要访问名称是nginx2的service,经过NODE节点192.168.1.100上的iptables表路由到了NODE节点192.168.1.101上,在NODE节点192.168.1.101上通过iptables里面kube-proxy创建的规则就会目标重定向给名称是nginx2的POD,最后这个POD上面的用户容器收到访问请求。
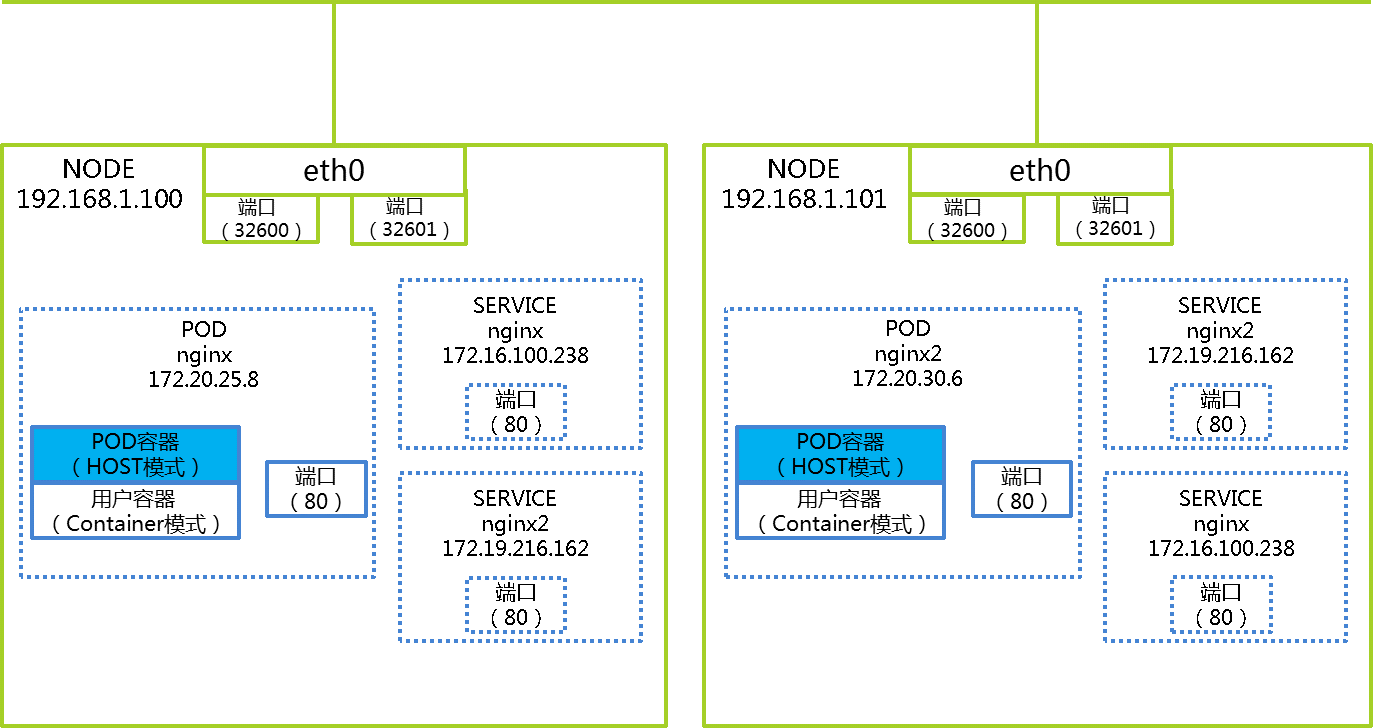
下面是使用NodePort模式的service示意图:
如果service使用ClusterIP模式,由于service是个虚拟的概念,所以service对应的IP其实也是个虚拟IP,在真是的外部物理网络中是无法访问的,所以只能在kubernetes集群中使用,在这张图上service使用了NodePost模式,从图中就可以清楚的看到kube-proxy在NODE节点上创建端口,kubernetes默认在30000-32767之间选择端口号给service,并且建立从NODE节点上物理端口到service的iptables规则,这样kubernetes外部应用就可以通过访问NODE节点IP和端口来实现访问service的目的。