据说是CVPR2019的满分论文,因为导师项目的方向正好与这篇论文很接近,所以翻译了下
论文地址:
https://arxiv.org/abs/1811.10092
///
///
摘要
:视觉-语言导航(VLN/vision-language navigation)是引导具身智能体(embodied agent)在真实三维环境中执行自然语言指令的任务。在这篇论文中,我们研究的是如何解决这一任务的三大关键难题:
跨模态基础标对
(cross-modal grounding)、
不适定反馈
(ill-posed feedback)和
泛化
(generalization)问题。首先,我们提出了一种全新的
增强型跨模态匹配(RCM)
方法,能够通过强化学习(RL)在局部和全局增强跨模态基础标对。尤其需要指出,我们使用了一个
匹配度评估器(matching critic)
来提供一种内部奖励,以激励指令和轨迹之间的全局匹配;我们还使用了一个
推理导航器(reasoning navigation)
,以在局部视觉场景中执行跨模态基础标对。
1 引言
VLN 有一些独特的挑战。第一,根据视觉图像和自然语言指令进行推理可能很困难。如图 1 所示,为了到达目标点,智能体需要将指令「落地」到局部视觉场景中,还要将这些用词序列表示的指令匹配成全局时间空间中的视觉轨迹。第二,除了严格遵照专家演示之外,反馈是相当粗糙的,因为「成功」反馈仅在智能体到达目标位置时提供,而完全忽视该智能体是遵照了指令(比如图 1 中的路径 A)还是采用了一条随机路径到达目标(比如图 1 中的路径 C)。如果智能体停止的时间比应该的略早一些(比如图 1 中的路径 B),即使匹配指令的「好」路径也可能被认为是不成功的。不适定的反馈有可能会偏离最优策略学习。第三,已有的研究成果深受泛化问题之苦,使得智能体在见过的和未见过的环境中的表现会有很大差距。
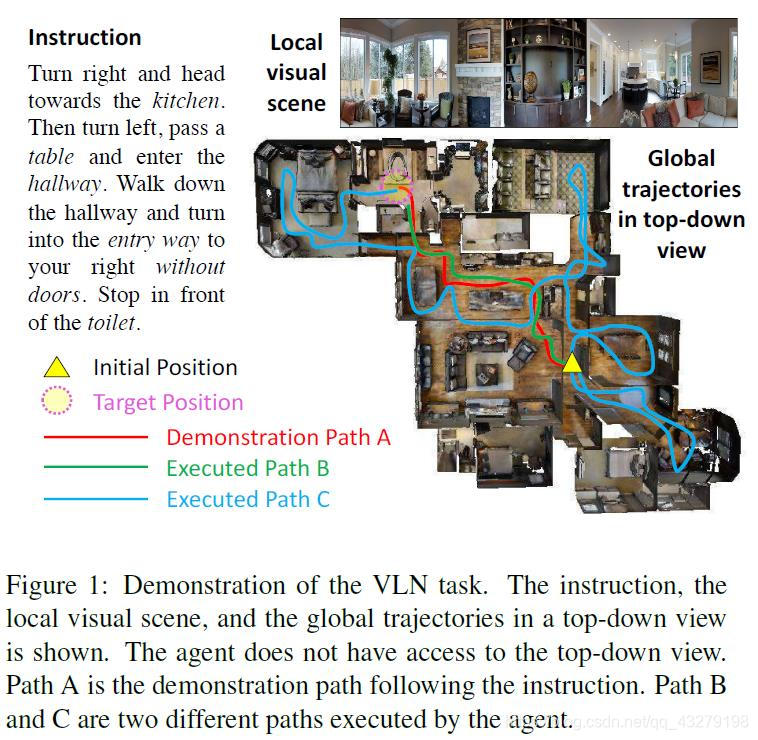
在这篇论文中,我们提出结合强化学习(RL)和模仿学习(IL)的能力来解决上述难题。首先,我们引入了一种全新的增强型跨模态匹配(RCM)方法,可通过通过强化学习在局部和全局增强跨模态基础标对。尤其要指出,我们设计了一种推理导航器,可在局部视觉场景与文本指令中学习跨模态基础标对,这样能让智能体推断应该关注哪个子指令以及应该看哪里。从全局的角度看,我们为智能体配备了匹配度评估器(matching critic),可以根据由路径重建原始指令的概率来评估所执行的路径,我们称之为循环重建奖励(cycle-reconstruction reward)。局部而言,这种循环重建奖励能提供一种细粒度的内部奖励信号,可鼓励智能体更好地理解语言输入以及惩罚与指令不匹配的轨迹。举个例子,如果使用我们提出的这种奖励,则路径 B 被认为优于路径 C(见图 1)。
使用来自匹配度评估器的内部奖励和来自环境的外部奖励进行训练,推理导航器可以学习将自然语言指令「落地」到局部空间视觉场景和全局时间视觉轨迹上。我们的 RCM 模型在 Room-to-Room(R2R)数据集上显著优于已有的方法并实现了新的当前最佳表现。
我们的实验结果表明模型在见过的和未见过的环境中的表现差距很大。为了缩小这一差距,我们提出了一种有效的解决方案,即使用自监督来探索环境。这项技术很有价值,因为它可以促进终身学习以及对新环境的适应。举个例子,家用机器人可以探索其到达的新家庭,并通过学习之前的经历迭代式地提升导航策略。受这一事实的启发,我们引入了一种自监督模仿学习(SIL)方法,以探索不含有标注数据的未见过的环境。智能体可以学习模仿自己过去的优良经历。具体而言,在我们的框架中,导航器会执行多次 roll-out,其中优良的轨迹(由匹配度评估器确定)会被保存在重放缓冲区中,之后导航器会将其用于模仿。通过这种方式,导航器可以近似其最佳行为,进而得到更优的策略。总结起来,我们有四大
贡献
:
1.我们提出了一种全新的增强型跨模态匹配(RCM)框架,能让强化学习同时使用外部奖励和内部奖励;其中我们引入了一种循环重建奖励作为内部奖励,以强制执行语言指令和智能体轨迹之间的全局匹配。
2.我们的推理导航器可学习跨模态的背景,基于轨迹历史、文本背景和视觉背景来做决策。
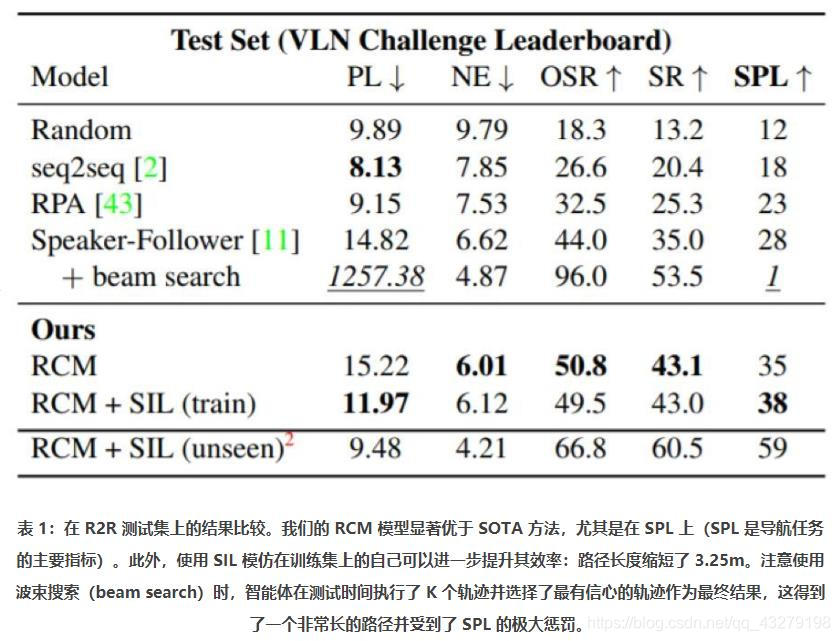
3.实验表明 RCM 能在 R2R 数据集上达到新的当前最佳表现,在 VLN Challenge 的 SPL 方面(该任务最可靠的指标)也优于之前的最佳方法,排名第一。
4.此外,我们引入了一种自监督模仿学习(SIL)方法,可通过自监督来探索未曾见过的环境;我们在 R2R 数据集上验证了其有效性和效率。
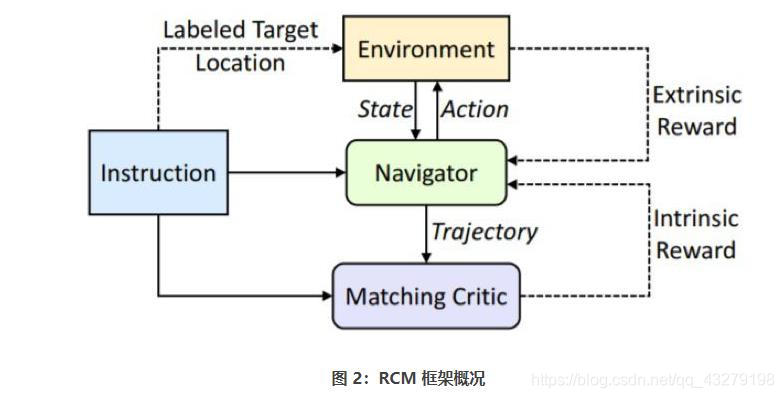
2 增强型跨模态匹配(RCM)
这里我们研究的是一种智能体,它们需要学习通过遵循自然语言指令而在真实的室内环境中导航。如图 2 所示,RCM 框架主要由两个模块构成:
推理导航器
π
Θ
\pi_{\Theta }
π
Θ
和
匹配度评估器
V
β
V_{\beta }
V
β
。给定
起始状态s0
和
自然语言指令(一个词序列)
χ
=
x
1
,
x
2
,
.
.
.
,
x
n
\chi = x1,x2,…,xn
χ
=
x
1
,
x
2
,
.
.
.
,
x
n
,推理导航器要学习执行一个
动作序列a1,a2,…,aT
∈
A
\in A
∈
A
,这些序列会生成一个
轨迹
τ
\tau
τ
,以便到达由指令指示的目标位置
S
t
a
r
g
e
t
S_{target}
S
t
a
r
g
e
t
。导航器在智能体执行动作过程中会与环境交互以及感知新的视觉状态。为了提升泛化能力以及增强策略学习,我们引入了两个
奖励函数
:一个由环境提供的外部奖励和一个源自我们的匹配度评估器的内部奖励。其中外部奖励度量的是每个动作的成功信号和导航误差,内部奖励度量的是语言指令
χ
\chi
χ
与导航器轨迹
τ
\tau
τ
之间的对齐情况。
2.1 RCM模型细节
2.1.1 跨模态推理导航器
导航器
π
Θ
\pi_{\Theta }
π
Θ
是一个基于策略的代理,它将输入指令
χ
\chi
χ
映射到一系列操作
{
a
t
}
t
=
1
T
\left \{ a_{t} \right \}_{t=1}^{T}
{
a
t
}
t
=
1
T
。在每一步t时,导航器从环境接收一个状态st,并需要将文本指令根植于局部的视觉场景中。因此,我们设计了一个跨模态推理导航器,该导航器可以学习轨迹历史、文本指令的重点和局部视觉注意,从而形成一个跨模态推理路径,在步骤t处鼓励两种模态的局部动力学(encourage the local dynamics of both modalities at step t 这句不知道怎么翻译- -)。
图3为第t步时导航器的展开版本。与[13]类似,我们为导航器配备了全景视图,全景视图被分割为m个不同视点的图像块,因此从视觉状态st中提取的全景特征可以表示为
{
v
t
,
j
}
j
=
1
m
\left \{ v_{t,j} \right \}_{j=1}^{m}
{
v
t
,
j
}
j
=
1
m

History Context
导航器运行一个步骤后,可视场景将相应地更改。LSTM将轨迹的到第t步的历史记录
τ
1
:
t
\tau _{1:t}
τ
1
:
t
编码为历史上下文(History context)向量ht:
(1)
h
t
=
L
S
T
M
(
[
v
t
,
a
t
−
1
]
,
h
t
−
1
)
h_{t}=LSTM\left ( \left [ v_{t},a_{t-1} \right ] ,h_{t-1}\right )\tag{1}
h
t
=
L
S
T
M
(
[
v
t
,
a
t
−
1
]
,
h
t
−
1
)
(
1
)
a
t
−
1
a_{t-1}
a
t
−
1
是在前面的步骤中采取的行动,
v
t
=
∑
j
α
t
,
j
v
t
,
j
v_{t}=\sum_{j}\alpha _{t,j}v_{t,j}
v
t
=
∑
j
α
t
,
j
v
t
,
j
表示全景特征的加权和,
α
t
,
j
\alpha _{t,j}
α
t
,
j
为视觉特征
v
t
,
j
v_{t,j}
v
t
,
j
的注意力权重(attention weight),代表它对于前面的“history context”
h
t
−
1
h_{t-1}
h
t
−
1
的重要性
注意:我们在后面采用了the dot-product attention(谷歌发表的文章”Attention is all you need”)[45],我们将其表示为(以上面的视觉特性为例):
(2)
v
t
=
a
t
t
e
n
t
i
o
n
(
h
t
−
1
,
{
v
t
,
j
}
j
=
1
m
)
=
∑
j
s
o
f
t
m
a
x
(
h
t
−
1
W
h
(
v
t
,
j
W
v
)
T
)
v
t
,
j
v_{t}=attention\left ( h_{t-1},\left \{ v_{t,j} \right \}_{j=1}^{m} \right ) \\=\sum_{j}softmax(h_{t-1}W_{h}\left ( v_{t,j}W_{v} \right )^{T})v_{t,j}\tag{2}
v
t
=
a
t
t
e
n
t
i
o
n
(
h
t
−
1
,
{
v
t
,
j
}
j
=
1
m
)
=
j
∑
s
o
f
t
m
a
x
(
h
t
−
1
W
h
(
v
t
,
j
W
v
)
T
)
v
t
,
j
(
2
)
W
h
W_{h}
W
h
和
W
v
W_{v}
W
v
是可学习的投影矩阵。
Visually Conditioned Textual Context(视觉条件下的文本语境)
记住过去可以识别当前的状态,从而理解接下来应该关注哪些单词或子指令。因此,我们进一步学习了文本上下文
c
t
t
e
x
t
c_{t}^{text}
c
t
t
e
x
t
使其适应历史上下文(history context)
h
t
h_{t}
h
t
。我们让语言编码器LSTM将语言指令
χ
\chi
χ
编码为一组文本特征
{
w
i
}
i
=
1
n
\left \{ w_{i} \right \}_{i=1}^{n}
{
w
i
}
i
=
1
n
,然后在每个时间步,文本语境的计算为:
(3)
c
t
t
e
x
t
=
a
t
t
e
n
t
i
o
n
(
h
t
,
{
ω
i
}
i
=
1
n
)
c_{t}^{text}=attention\left ( h_{t},\left \{ \omega _{i} \right \}_{i=1}^{n} \right )\tag{3}
c
t
t
e
x
t
=
a
t
t
e
n
t
i
o
n
(
h
t
,
{
ω
i
}
i
=
1
n
)
(
3
)
注意,
c
t
t
e
x
t
c_{t}^{text}
c
t
t
e
x
t
更重视与轨迹历史和当前视觉状态更相关的单词。
Textually Conditioned Visual Context(文本条件下的视觉语境)
知道从哪里看需要对语言教学有一个动态的理解;所以我们根据文本语境
c
t
t
e
x
t
c_{t}^{text}
c
t
t
e
x
t
计算可视语境
c
t
v
i
s
u
a
l
c_{t}^{visual}
c
t
v
i
s
u
a
l
(3)
c
t
v
i
s
u
a
l
=
a
t
t
e
n
t
i
o
n
(
c
t
t
e
x
t
,
{
v
j
}
j
=
1
m
)
c_{t}^{visual}=attention\left ( c_{t}^{text},\left \{ v _{j} \right \}_{j=1}^{m} \right )\tag{3}
c
t
v
i
s
u
a
l
=
a
t
t
e
n
t
i
o
n
(
c
t
t
e
x
t
,
{
v
j
}
j
=
1
m
)
(
3
)
Action Prediction(行为预测)
最后,我们的行为预测考虑
h
t
h_{t}
h
t
,
c
t
t
e
x
t
c_{t}^{text}
c
t
t
e
x
t
和
c
t
v
i
s
u
a
l
c_{t}^{visual}
c
t
v
i
s
u
a
l
,并根据它们决定下一步的方向。它使用双线性点积计算每个可航方向的概率
p
k
p_{k}
p
k
,如下所示
(4)
p
k
=
s
o
f
t
m
a
x
(
[
h
t
,
c
t
t
e
x
t
,
c
t
v
i
s
u
a
l
]
W
c
(
u
k
W
u
)
T
)
p_{k}=softmax(\left [ h_{t},c_{t}^{text},c_{t}^{visual} \right ]W_{c}\left ( u_{k}W_{u} \right )^{T})\tag{4}
p
k
=
s
o
f
t
m
a
x
(
[
h
t
,
c
t
t
e
x
t
,
c
t
v
i
s
u
a
l
]
W
c
(
u
k
W
u
)
T
)
(
4
)
u
k
u_{k}
u
k
是表示第k个可导航方向的动作嵌入,通过连接一个外观特征向量(从该视角或方向周围的图像patch中提取的CNN特征向量)和一个四维方向特征向量
[
s
i
n
φ
;
c
o
s
φ
;
s
i
n
ω
;
c
o
s
ω
]
\left [ sin\varphi ;cos\varphi ;sin\omega ;cos\omega \right ]
[
s
i
n
φ
;
c
o
s
φ
;
s
i
n
ω
;
c
o
s
ω
]
,
φ
\varphi
φ
和
ω
\omega
ω
分别为航向角和导航角。
2.1.2 跨模态匹配评估器
除了外部环境的奖励信号外,我们还推导了匹配评估器
V
β
V_{\beta }
V
β
提供的一个内部奖励
R
i
n
t
r
R_{intr}
R
i
n
t
r
,以鼓励语言指令
χ
\chi
χ
和导航器
π
Θ
\pi_{\Theta }
π
Θ
轨迹
τ
=
{
<
s
1
,
a
1
>
,
<
s
2
,
a
2
>
,
.
.
.
,
<
s
T
,
a
T
>
}
\tau =\left \{ <s1,a1>,<s2,a2>,…,<sT,aT> \right \}
τ
=
{
<
s
1
,
a
1
>
,
<
s
2
,
a
2
>
,
.
.
.
,
<
s
T
,
a
T
>
}
之间的全局匹配:
(5)
R
i
n
t
r
=
V
β
(
χ
,
τ
)
=
V
β
(
χ
,
π
θ
(
χ
)
)
R_{intr}=V_{\beta }\left ( \chi ,\tau \right )=V_{\beta }(\chi ,\pi _{\theta }\left ( \chi \right ))\tag{5}
R
i
n
t
r
=
V
β
(
χ
,
τ
)
=
V
β
(
χ
,
π
θ
(
χ
)
)
(
5
)
实现这一目标的一种方法是测量循环重构奖励
p
(
χ
^
=
χ
∣
π
θ
(
χ
)
)
p\left ( \widehat{\chi} = \chi \right |\pi _{\theta }\left ( \chi \right ))
p
(
χ
=
χ
∣
π
θ
(
χ
)
)
,即给定轨迹下重构语言指令
χ
\chi
χ
的概率由
τ
=
π
θ
(
χ
)
\tau =\pi _{\theta }\left ( \chi \right )
τ
=
π
θ
(
χ
)
执行。
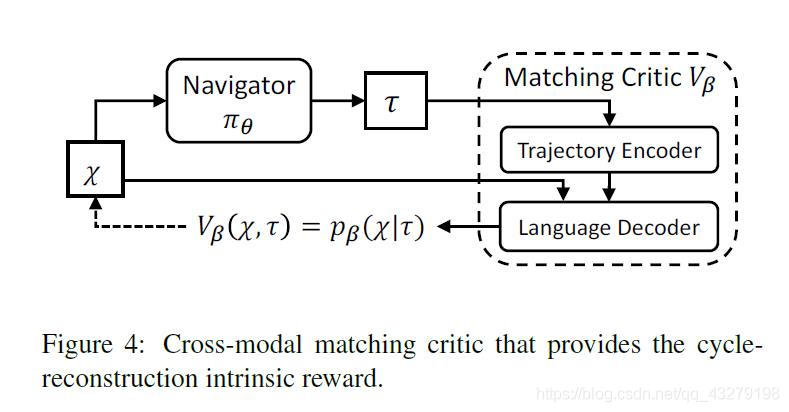
因此,如图4所示,我们采用基于注意力的序列到序列语言模型作为匹配评估器
V
β
V_{\beta }
V
β
,该模型使用轨迹编码器对轨迹
τ
\tau
τ
进行编码,并使用语言解码器生成指令
χ
\chi
χ
的每个单词的概率分布。因此内在奖励
R
i
n
t
r
=
p
β
(
χ
∣
π
θ
(
χ
)
)
=
p
β
(
χ
∣
τ
)
R_{intr}=p_{\beta }\left ( \chi |\pi _{\theta } \left ( \chi \right )\right )=p_{\beta }\left ( \chi |\tau \right )
R
i
n
t
r
=
p
β
(
χ
∣
π
θ
(
χ
)
)
=
p
β
(
χ
∣
τ
)
R
i
n
t
r
R_{intr}
R
i
n
t
r
被指令长度n归一化。在我们的实验中,匹配评估器被人类的演示预先训练(地面真实指令-轨迹
<
χ
∗
,
τ
∗
>
<\chi ^{*},\tau ^{*}>
<
χ
∗
,
τ
∗
>
)监督学习。
2.2 Learning
为了快速逼近一个较好的策略,我们使用演示动作进行带最大似然估计(MLE)的监督学习。训练损失
L
s
l
L_{sl}
L
s
l
定义为
(6)
L
s
l
=
−
E
[
l
o
g
(
π
θ
)
(
a
t
∗
∣
s
t
)
]
L_{sl}=-E\left [ log\left ( \pi _{\theta } \right )\left ( a_{t}^{*}|s_{t} \right ) \right ]\tag{6}
L
s
l
=
−
E
[
l
o
g
(
π
θ
)
(
a
t
∗
∣
s
t
)
]
(
6
)
a
t
∗
a_{t}^{*}
a
t
∗
是模拟器提供的演示动作,使用监督学习来启动agent可以确保在所看到的环境中有一个相对好的策略。但它也限制了agent在不可见环境中从错误操作中恢复的泛化能力,因为它只克隆专家演示的行为。
为了学习更好、更一般化的策略,我们转向强化学习,引入外部和内部的奖励函数,从不同的角度对策略进行细化。
Extrinsic Reward(外在奖励)
RL中的一个常见实践是直接优化评估指标。由于客观VLN的任务是成功地到达目标位置
s
t
a
r
g
e
t
s_{target}
s
t
a
r
g
e
t
,我们考虑了奖励设计的两个指标。第一个度量是与[50]相似的相对导航距离。我们将
s
t
s_{t}
s
t
和
s
t
a
r
g
e
t
s_{target}
s
t
a
r
g
e
t
之间的距离表示为
D
t
a
r
g
e
t
(
s
t
)
D_{target}(s_{t})
D
t
a
r
g
e
t
(
s
t
)
。然后立即奖励
r
(
s
t
,
a
t
)
r(s_{t},a_{t})
r
(
s
t
,
a
t
)
在状态
s
t
s_{t}
s
t
(t < T)采取行为
a
t
a_{t}
a
t
之后变为
(7)
r
(
s
t
,
a
t
)
=
D
t
a
r
g
e
t
(
s
t
)
−
D
t
a
r
g
e
t
(
s
t
+
1
)
,
t
<
T
r(s_{t},a_{t})=D_{target}\left ( s_{t} \right )-D_{target}\left ( s_{t+1} \right ),t<T\tag{7}
r
(
s
t
,
a
t
)
=
D
t
a
r
g
e
t
(
s
t
)
−
D
t
a
r
g
e
t
(
s
t
+
1
)
,
t
<
T
(
7
)
这表示在点采取行动后到目标位置的距离减小。我们的第二个选择把“成功”作为一个额外的标准。如果agent到达一个阈值内的点,该阈值由距离目标的距离d测量(在R2R数据集中,d预设为3m),则该agent被视为“成功”。
其中,最后一步T的即时奖励函数定义为
(8)
r
(
s
T
,
a
T
)
=
I
(
D
t
a
r
g
e
t
(
s
T
≤
d
)
)
r(s_{T},a_{T})=\mathbb{I}(D_{target}(s_{T}\leq d))\tag{8}
r
(
s
T
,
a
T
)
=
I
(
D
t
a
r
g
e
t
(
s
T
≤
d
)
)
(
8
)
I
\mathbb{I}
I
是一个决策函数。为了考虑行动对未来的影响,考虑到局部贪婪搜索,我们使用折现累积奖励而不是直接奖励来训练策略:
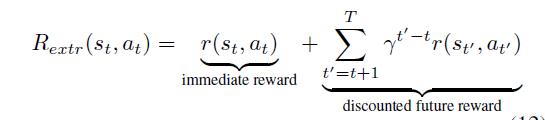
$\gamma $是一个折现因子(在实验中为0.95)
Intrinsic Reward(内在奖励)
如第2.1.2节所述,我们预先训练一个匹配评估器来计算循环重构内在奖励
R
i
n
t
r
R_{intr}
R
i
n
t
r
,促进语言指令X与轨迹的对齐。它鼓励agent尊重指令,并惩罚偏离指令指示的路径。
有外部奖励函数和内部奖励函数,RL损失可表示为
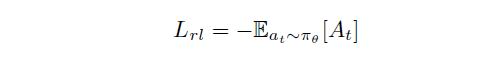
A
t
=
R
e
x
t
r
+
δ
R
i
n
t
r
A_{t}=R_{extr}+\delta R_{intr}
A
t
=
R
e
x
t
r
+
δ
R
i
n
t
r
,
δ
\delta
δ
是衡量内在奖励的超参数。基于REINFORCE algorithm[51],可得到基于奖励的不可微损失函数梯度为
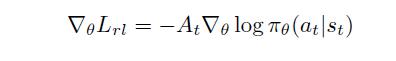
3 Self-Supervised Imitation Learning
最后一节介绍了通用视觉语言导航任务的有效RCM方法,其标准设置是在可见环境中训练agent,并在不需要探索的情况下在不可见环境中进行测试。在本节中,我们将讨论一种不同的设置,在这种设置中,agent可以在不使用基本事实演示的情况下探索不可见的环境。这是有实际好处的,因为它有助于终身学习和适应新环境。
为此,我们提出了一种自我监督模仿学习(SIL)方法来模仿智能体自身过去的良好决策。如图5所示,给定一个无相应的演示的自然语言指令
χ
\chi
χ
和基本真值的目标位置,导航器会得到一组可能的轨迹并将其中最佳的轨迹
τ
^
\hat{\tau}
τ
^
(由匹配度评估器确定)保存到重放缓冲区中。
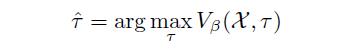
(15)
匹配评估器根据2.1.1节中介绍的循环重构奖励来评估轨迹。然后,通过利用回放缓冲区中的良好轨迹,该agent确实在自我监督下优化以下目标。目标位置未知,因此没有来自环境的监督。
L
s
i
l
=
−
R
i
n
t
r
l
o
g
π
θ
(
a
t
∣
s
t
)
L_{sil}=-R_{intr}log\pi _{\theta }(a_{t}|s_{t})
L
s
i
l
=
−
R
i
n
t
r
l
o
g
π
θ
(
a
t
∣
s
t
)
注意,
L
s
i
l
L_{sil}
L
s
i
l
可以被看作是策略梯度的损失,只是使用了off-policy Monte-Carlo return Rintr而不是on-policy return。
L
s
i
l
L_{sil}
L
s
i
l
也可以理解为作为“基本事实”的监督学习
τ
^
\hat{\tau }
τ
^
的损失
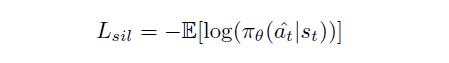
其中
a
t
^
\hat{a_{t} }
a
t
^
是使用方程式(15)存储在回放缓冲区中的操作。SIL方法与一个匹配评估器相结合,可以结合各种学习方法,通过模仿其本身的最佳值来逼近更好的策略。

训练细节
在之前的工作[3,50,13]中,我们提取了所有图像的ResNet-152 CNN feature[15],没有进行微调。使用预先训练好的Glove词嵌入进行初始化,然后在训练过程中进行微调。所有超参数都在验证集上进行调优。我们采用全景动作空间[13],其中的动作是从可能的候选方向中选择一个可导航的方向。我们设置动作路径的最大长度为10。指令的最大长度设置为80,较长的指令将被截断。我们用学习率为1e-4来训练匹配评估器,然后在策略学习中修正它。然后,我们通过学习速率为1e-4的监督学习损失来预热策略,然后切换到学习速率为1e-5的RL训练。可以通过自监督模仿学习进一步改进策略:在SIL的第一个epoch中,加载的策略产生10条轨迹,其中内在奖励最高的轨迹存储在回放缓冲区中;然后利用这些保存的轨迹对策略进行一定次数的微调(学习率为1e-5)。所有的训练都使用早期停止,Adam optimizer使用[24]优化所有的参数。为了避免过度拟合,我们使用L2权值衰减为0.0005,dropout比率为0.5。累积奖励的折现因子是0.95。内在奖励的权重
σ
\sigma
σ
设置为2。
网络结构
A 推理导航器
该语言编码器由大小为512的隐藏LSTM和大小为300的单词嵌入层组成。用于计算history context、the textual context和 the visual context三个注意模块的内部维度分别为256、512和256。该轨迹编码器是一个隐藏大小为512的LSTM。动作嵌入是尺寸为2048的视觉外观特征向量与尺寸为128的方向特征向量(4维方向特征
[
s
i
n
φ
;
c
o
s
φ
;
s
i
n
ω
;
c
o
s
ω
]
\left [ sin\varphi ;cos\varphi ;sin\omega ;cos\omega \right ]
[
s
i
n
φ
;
c
o
s
φ
;
s
i
n
ω
;
c
o
s
ω
]
是在[13]中使用的32倍)。该动作预测器由三个权重矩阵组成:
W
c
W_{c}
W
c
和
W
u
W_{u}
W
u
的投影维数均为256,然后通过输出层
W
o
W_{o}
W
o
和softmax层得到可能的导航方向的概率。
B 匹配评估器
匹配评估器由具有相同结构的基于注意力的轨迹编码器组成。作为导航器中的一个,它自己的word嵌入层大小为300,并且是一个基于注意力的语言解码器。该语言解码器由编码特征上的注意模块(投影维数为512)、隐藏大小为512的LSTM和将隐藏状态转换为词汇表中所有单词的概率的多层感知器(Linear
→
\rightarrow
→
Tanh
→
\rightarrow
→
Linear
→
\rightarrow
→
SoftMax)组成。
C 可视化内在奖励
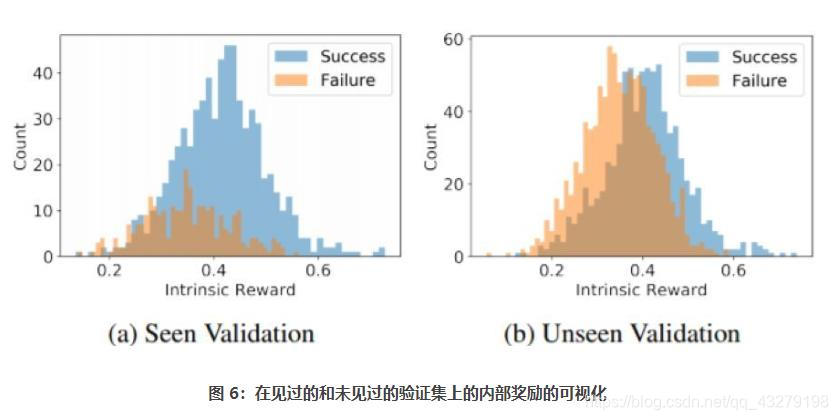
在图7中,我们在可见验证集和不可见验证集上绘制了内在奖励(由我们提交的模型产生)的直方图分布。一方面,内在的奖励与成功率在一定程度上是一致的,因为成功的例子比失败的例子获得了更高的平均内在奖励。另一方面,互补的内在奖励提供了更细粒度的奖励信号,增强了多模态接地,提高了导航策略学习。
实验和分析


总结
我们在这篇论文中提出了两种全新方法 RCM 和 SIL,从而结合了强化学习和自监督模仿学习两者的优势来解决视觉-语言导航任务。不管是在标准测试场景中,还是在终身学习场景中,实验结果都表明了我们方法的有效性和效率。此外,我们的方法在未见过的环境中的泛化能力也很强。请注意,我们提出的学习框架是模块化的,而且与具体模型无关,这让我们可以分别各自改进各个组件。我们还相信这些方法可以轻松泛化用于其它任务。