前言

前面我们介绍了
pg_auto_failover
的安装,和客户端如何配置failover。今天我们来学习一下pg_auto_failover的状态机。
pg_auto_failover日志在哪里看
配置Monitor、Primary Node、Secondary Node的时候,输出的日志可以打在终端上。可是后面想找日志居然找不到了。这倒是让我们很意外的。研究了一番,发现日志其实输出在
/var/log/message
里面,如果系统错误比较多,这可不方便我们看。不过我们做成了systemd服务之后,可以使用
journalctl
命令来查看。
使用
journalctl -u 服务名
可以显示日志。以下是Monitor节点最新日志的输出。
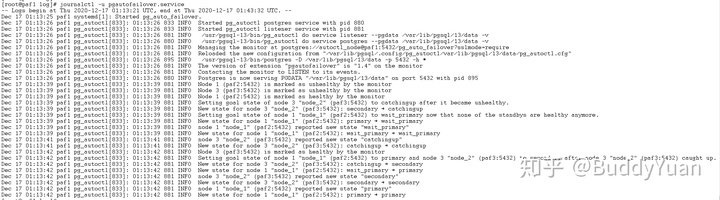
Monitor也叫状态机是个什么原理
Monitor也叫状态机是pg_auto_failover的核心机制。最简单的理解就是通晓各个节点当下的状态。首先各个节点的守护进程会发送事件给状态机,状态机根据发送过来的事件信息,为每个节点分配当前状态和目标状态。节点的当前状态是其功能的有力保证。而目标状态是告诉我们将要尝试的转换。
所以状态机很重要,它只有才全面了解了当前集群的状态。才会在出问题的时候做出决策。
但是问题来了,它是个单节点运行的。如果出现单点故障会怎么样?
我们来模拟一下,下面是状态机上显示的集群状态。
[postgres@paf1 ~]$ pg_autoctl show state
Name | Node | Host:Port | LSN | Reachable | Current State | Assigned State
-------+-------+------------+-----------+-----------+---------------------+--------------------
node_1 | 1 | paf2:5432 | 0/321CFB8 | yes | primary | primary
node_2 | 3 | paf3:5432 | 0/321CFB8 | yes | secondary | secondary我们直接将状态机shutdown,进行硬件维护。
当状态机关闭后,在Primary Node节点执行查看集群状态,就会显示无法连接到状态机。
[postgres@paf2 ~]$ pg_autoctl show state
02:22:51 10678 WARN Failed to connect to "postgres://autoctl_node@paf1:5432/pg_auto_failover?sslmode=require", retrying until the server is ready
02:22:51 10678 ERROR Connection to database failed: timeout expired
02:22:51 10678 ERROR Failed to connect to "postgres://autoctl_node@paf1:5432/pg_auto_failover?sslmode=require" after 1 attempts in 2 seconds, pg_autoctl stops retrying now
02:22:51 10678 ERROR Failed to retrieve current state from the monitor
通过
journalctl
命令查看Primary Node的日志,大量报无法连接Monitor的错误。
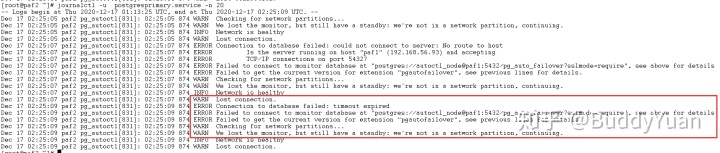
此时主库和备库仍然可以连,并且集群状态无异常
[postgres@paf2 ~]$ psql -h 192.168.56.94
psql (13.1)
SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, bits: 256, compression: off)
Type "help" for help.
postgres=# x
Expanded display is on.
postgres=# select usename,application_name,client_addr,backend_start,state,sync_state from pg_stat_replication ;
-[ RECORD 1 ]----+------------------------------
usename | pgautofailover_replicator
application_name | pgautofailover_standby_3
client_addr | 192.168.56.95
backend_start | 2020-12-17 01:13:38.252427+00
state | streaming
sync_state | sync
[postgres@paf2 ~]$ psql -h 192.168.56.95
postgres=# x
Expanded display is on.
postgres=# select status,receive_start_lsn,written_lsn,flushed_lsn,latest_end_lsn,slot_name from pg_stat_wal_receiver;
-[ RECORD 1 ]-----+-------------------------
status | streaming
receive_start_lsn | 0/3000000
written_lsn | 0/321CFB8
flushed_lsn | 0/321CFB8
latest_end_lsn | 0/321CFB8
slot_name | pgautofailover_standby_3可以发现状态机挂了对集群使用完全没有一丁点影响。但是此时如果集群里面的机器在挂一台,是没有办法自动进行故障转移的,因为我们失去了状态机。
状态机的转换示例
这段是官方文档的例子,描述了一个集群从诞生到高可用性的过渡的各种状态。
1.首先假定我们的状态机已经部署。
2.
Primary Node
运行初始化后,节点上的监控进程将当前状态注册为
init
,目标状态注册为
single
。
init
代表着状态机除了知道节点存在,对节点其他情况一无所知,因为监控进程还没有连续的报告节点的运行状态。
Name | Node | Host:Port | LSN | Reachable | Current State | Assigned State
-------+-------+------------+-----+-----------+---------------------+--------------------
node_4 | 4 | paf2:5432 | 0/0 | unknown | init | single
3.当
Primary Node
上的守护进程持续向状态机报告运行状态后,Monitor会将当前状态分设置为
single
。这也就是说状态机认为这是一个单机,单机是没有故障转移的。此时集群中还没有其他节点,Monitor将的
Primary Node
目标状态也分配为
single
.
Name | Node | Host:Port | LSN | Reachable | Current State | Assigned State
-------+-------+------------+-----------+-----------+---------------------+--------------------
node_4 | 4 | paf2:5432 | 0/1613300 | unknown | single | single
4.当开始初始化
Secondary Node
,Monitor就会将
Primary Node
的目标状态分配为
wait_primary
,此时在等待
Secondary Node
进行同步。为了完成从
single
到
wait_primary
的转换,
Primary Node
会将
Secondary Node
节点的主机名和IP添加到pg_hba.conf中允许连接。
Secondary Node
此时会转换为
wait_standby
,其目标状态也是
wait_standby
。需要等到
Primary Node
授予其连接权限。
Name | Node | Host:Port | LSN | Reachable | Current State | Assigned State
-------+-------+------------+-----------+-----------+---------------------+--------------------
node_4 | 4 | paf2:5432 | 0/1613338 | yes | single | wait_primary
node_5 | 5 | paf3:5432 | 0/0 | unknown | wait_standby | wait_standby
5.一旦连接权限授予后,监控器将
Secondary Node
的就会将目标分配为
catchingup
,此时从
wait_standby
到
catchingup
的过程中将会运行pg_basebackup,编辑recovery.conf以及在
热备
节点中重新启动PostgreSQL。
Name | Node | Host:Port | LSN | Reachable | Current State | Assigned State
-------+-------+------------+-----------+-----------+---------------------+--------------------
node_4 | 4 | paf2:5432 | 0/2000060 | yes | wait_primary | wait_primary
node_5 | 5 | paf3:5432 | 0/0 | unknown | wait_standby | catchingup
6.当
Secondary Node
节点处于热备模式,并能够连接
Primary Node
时,
Secondary Node
的目标状态就会变成
secondary
。
Primary Node
的目标状态也会变成
primary
。Postgres从
Primary Node
传输WAL日志,然后在
Secondary Node
上重做它们。然后
Secondary Node
会向Monitor汇报pg_stat_replication.sync_state和WAL replay lag。
Name | Node | Host:Port | LSN | Reachable | Current State | Assigned State
-------+-------+------------+-----------+-----------+---------------------+--------------------
node_4 | 4 | paf2:5432 | 0/30000D8 | yes | primary | primary
node_5 | 5 | paf3:5432 | 0/30000D8 | yes | secondary | secondary
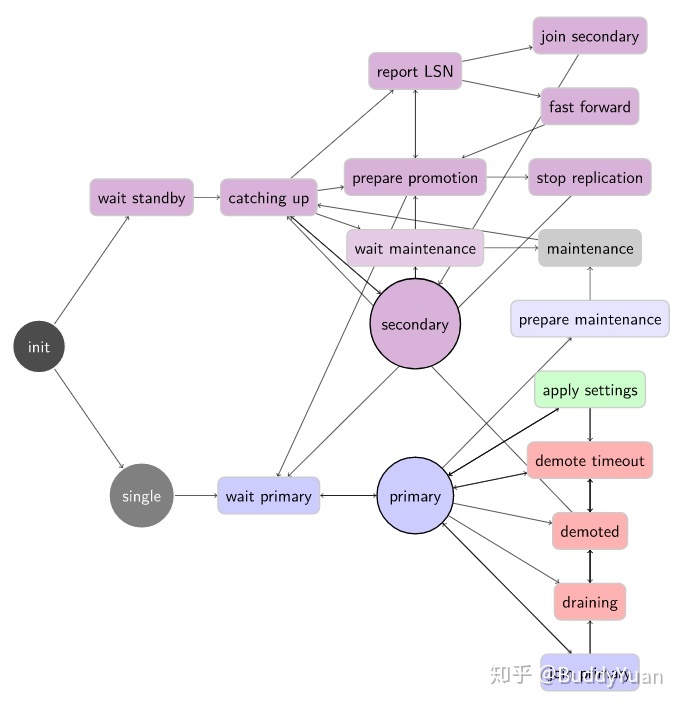
状态机的图示
官方提供了一张状态机的图,不过官方说这张图缺少了指向
single
状态的链接。
It’s missing links to the
single
state, which can always been reached when removing all the other nodes.
不是很理解官方这个意思。删除所有其他节点的时候始终都能reached?
所以我决定来模拟一下删除节点操作。写一个shell循环,在Monitor上执行查看状态。
while true;
do
pg_autoctl show state ;
sleep 1;
done
当我删除
Secondary Node
的时候。可以看到基本上很快就从
primary
变成了
single
。
pg_autoctl drop node --pgdata /var/lib/pgsql/13/data/ --destroy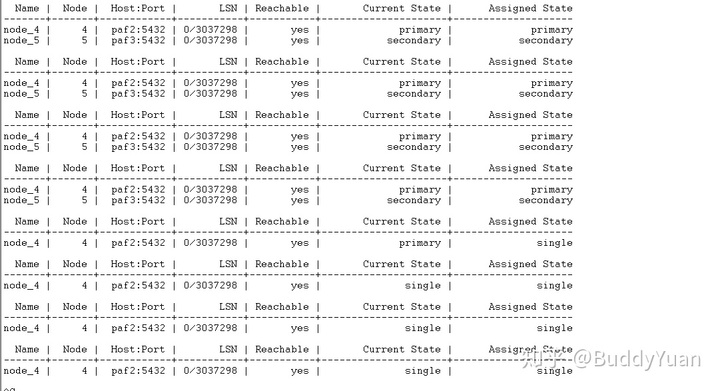
总结
我的理解其实状态机就是监控收集集群中各个节点的状态,并根据预设好的决策系统对各种状态进行控制,例如,如果主库现在down机了,状态机无法接收到主库的信息,就会执行决策,采取故障转移的策略。
而我们需要做的事情就是了解各种状态。下一回我们会详细介绍这些状态。这样有利于我们对集群出现问题后好做一个把控。