这里写自定义目录标题
- selenium自动化测试框架在爬虫的应用
- selenium大幅降低爬虫的编写难度
- 大幅降低速度
一、selenium概述
1. 运行操作
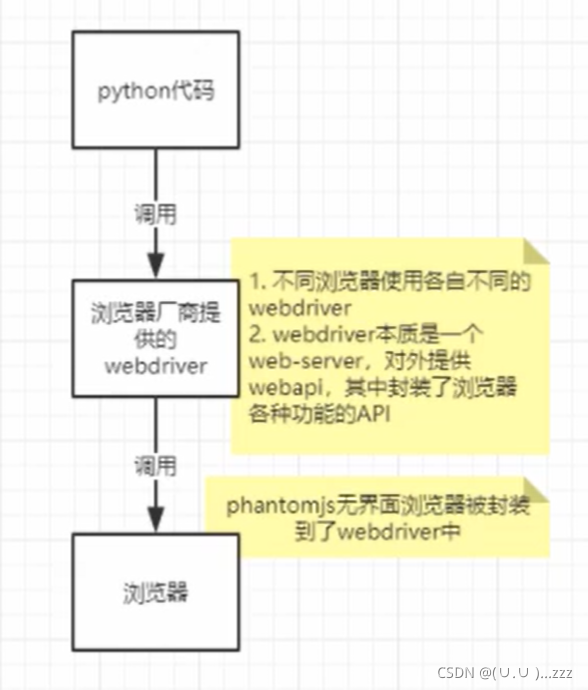
- selenium是一个web自动化测试工具
- 开发使用 有头浏览器,部署使用无界面浏览器
- webdriver本质是一个web-server,对外提供API,封装了浏览器的各种功能
-
代码调用webdriver操作浏览器
2. 安装webdriver
查看浏览器版本,安装对应的驱动
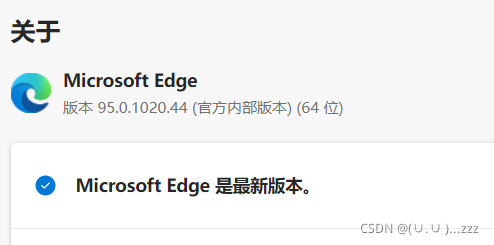
https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
然后将其中的.exe文件复制到浏览器的安装路径下。
浏览器安装路径:C:\Program Files (x86)\Microsoft\Edge\Application
利用python的脚本语言,指定浏览器的驱动。(一定要指定到驱动的名称,即复制进浏览器安装路径里的.exe文件的名称。如果只到application,python脚本运行会报错。)
import time
from selenium import webdriver
# 通过指定msedgdriver的路径来实例化driver对象,msedgedriver放在当前目录
# msedgedriver添加环境变量了,但是不知道为什么不指定路径就会报错
driver = webdriver.Edge('C:\Program Files (x86)\Microsoft\Edge\Application\msedgedriver')
# driver = webdriver.Edge()
# 控制浏览器访问url地址
driver.get("https://www.baidu.com/")
# 百度搜索框中搜索python
driver.find_element_by_id('kw').send_keys('python')
# 点击搜索python
driver.find_element_by_id('su').click()
time.sleep(6)
# 6s后退出浏览器
driver.quit
二、元素定位
1. driver对象的常用属性、方法
driver.page_source
当前标签浏览器选然后的源码
driver.current_url
响应的源码(不是请求的源码
driver.close()
关闭标签
driver.quit()
关闭浏览器
driver.forward()
页面前进
driver.back()
页面后退
driver.screenshot(img_name)
页面截图
import time
from selenium import webdriver
driver = webdriver.Edge('C:\Program Files (x86)\Microsoft\Edge\Application\msedgedriver')
url = 'http://www.baidu.com'
driver.get(url)
print(driver.page_source)
driver.save_screenshot('baidu.png')
2. 定位方法
#通过xpath进行元素定位
driver.find_element_by_xpath('//*[@id="kw"]').send_keys('python3')
# 通过css选择器 元素定位:复制selector #kw
driver.find_element_by_css_selector('#kw').send_keys('德赫')
# 通过name属性值进行元素定位
driver.find_element_by_name('wd').send_keys('Draco')
# 通过class属性进行元素定位
driver.find_element_by_class_name('s_ipt').send_keys('')
# 通过链接文本
driver.find_element_by_link_text('hao123').click # 报错,停在百度
driver.find_element_by_partial_link_text('hao123').click() # 跳到123
# 通过tag定位
# 目标元素是当前html中唯一标签,或众多定位标签中第一个的时候
print(driver.find_element_by_tag_name('title'))
-
find_elements
返回列表,匹配不到返回空列表 -
find_element
返回第一个匹配到的对象。匹配不到抛出异常
三、selenium其他用法
1. 句柄
工具、智能指针
# 获取当前所有标签页的句柄 构成的列表
current_windows = driver.window_handles
# 根据句柄列表索引下标进行切换
driver.switch_to.window(current_windows[0])
58同城跳转到租房页
from selenium import webdriver
driver = webdriver.Edge('C:\Program Files (x86)\Microsoft\Edge\Application\msedgedriver')
url = 'https://cd.58.com/'
driver.get(url)
# 验证当前url、句柄
print(driver.current_url)
print(driver.window_handles)
# https://cd.58.com/
# ['CDwindow-4560EDDD575AF11C521237B39D55F43B']
# 定位 点击租房按钮
el = driver.find_element_by_xpath('/html/body/div[3]/div[1]/div[1]/div/div[1]/div[1]/span[1]/a')
el.click()
print(driver.current_url)
print(driver.window_handles)
#
# https://cd.58.com/
# ['CDwindow-1C5285AC304F92464CCEF628E0E0ADCA', 'CDwindow-A2AB402B3B27B0BE9BCD11BC75D1883E']
# 两次验证发现url一样,句柄多了一个,但是url并未跳转,操作权还在首页
# 移动句柄
driver.switch_to.window(driver.window_handles[-1])
el_list = driver.find_element_by_xpath('/html/body/div[6]/div[2]/ul/li/div[2]/h2/a')
print(el_list)
2. frame
切换框架
driver.switch_to.frame()
from selenium import webdriver
driver = webdriver.Edge('C:\Program Files (x86)\Microsoft\Edge\Application\msedgedriver')
url = 'https://qzone.qq.com/'
driver.get(url)
# 切换框架
driver.switch_to.frame('login_frame')
# 直接点击头像登录
driver.find_element_by_id('img_out_qq号').click()
# 若未切换框架,则定位不到框架内的,报错
3. selenium对cookie的处理
get.cookies() # 拿到所有cookies
获取cookies,转成字典
from selenium import webdriver
driver = webdriver.Edge('C:\Program Files (x86)\Microsoft\Edge\Application\msedgedriver')
url = 'https://www.baidu.com/'
driver.get(url)
print(driver.get_cookies())
# 返回的是一个列表,每个元素是一个字典
cookies = {data['name']:data['value'] for data in driver.get_cookies()}
print(cookies)
# 删除一条cookie
driver.delete_cookie("domain")
# 删除所有cookie
driver.delete_all_cookies()
# xs python大小写知意
4. selenium控制浏览器执行js代码
滚轮下滑才会触发
from selenium import webdriver
driver = webdriver.Edge('C:\Program Files (x86)\Microsoft\Edge\Application\msedgedriver')
url = 'https://cd.lianjia.com/'
driver.get(url)
# 要点击的button在下面,没有拖动滚轮触发
# js实现拖动
js = 'scrollTo(0,500)' # 一般宽屏,只移3纵轴
driver.execute_script(js)
el_button = driver.find_element_by_xpath('/html/body/div[2]/div/div[1]/div[2]/div[1]/a[2]')
el_button.click()
5. 页面等待
-
强制等待
time.sleep()
-
隐式等待
driver.implicity_wait(10)
- 显示等待
- 手动分析
6. selenium开启无界面模式
from msedge.selenium_tools import Edge, EdgeOptions
url = 'http://www.baidu.com'
# 创建配置对象
opt = EdgeOptions()
# 添加配置参数
opt.add_argument('--headless')
opt.add_argument('--diaable-gpu')
# 创建浏览器对象
# 添加配置对象
#
driver = Edge(options=opt)
driver.get(url)
driver.save_screenshot('baidujietu.png')
emmmm不知道哪里问题,还是会跳出来浏览器,仿佛参数没用
7. 用selenium爬取斗鱼直播相关信息
from selenium import webdriver
from msedge.selenium_tools import Edge
import time
class Douyu(object):
def __init__(self):
self.url = 'https://www.douyu.com/directory/all'
self.driver = webdriver.Edge()
def parse(self):
room_list = self.driver.find_elements_by_xpath('//*[@id="listAll"]/section[2]/div[2]/ul/li/div')
# print(room_list)
data_list = []
for room in room_list:
temp = {}
self.driver.execute_script('scrollTo(0,1000000)')
time.sleep(10)
temp['title'] = room.find_element_by_xpath('./a[1]/div[2]/div[1]/h3').text
temp['type'] = room.find_element_by_xpath('./a[1]/div[2]/div[1]/span').text
temp['owner'] = room.find_element_by_xpath('./a[1]/div[2]/div[2]/h2').text
temp['hot'] = room.find_element_by_xpath('./a[1]/div[2]/div[2]/span').text
data_list.append(temp)
return data_list
def sava_data(self, data_list):
for data in data_list:
print(data)
def run(self):
# url
# driver
# get
self.driver.get(self.url)
while True:
# parse
data_list = self.parse()
# save
self.save_data(data_list)
# next
# 分析下一页和尾页情况
# 下一页:dy-Pagination-item-custom
# 在尾页的下一页:dy-Pagination-disabled dy-Pagination-next
# //*[@class="dy-Pagination-item-custom"]
# try:
el_next = self.driver.find_element_by_xpath('//*[contains(text(),"下一页")]')
print(el_next)
el_next.click()
if __name__ == '__main__':
douyu = Douyu()
douyu.run()