分类算法有很多,比较常用且简单、易于理解和解释的决策树算上一个(
有关决策树算法的应用可以参考本公众号9月19和20日的文章:基于R语言的数据挖掘之决策树
)。在学习机器学习过程中,我又碰见
一个规则分类算法
,该算法跟决策树类似,也可以返回具体分类规则,而且结果往往比决策树更简洁、更容易理解,这里与大家共享。
两个重要的规则学习算法
一、单规则算法
1、算法思想
如果一个数据集含有N个变量,该算法会从中挑选出一个最为重要的变量最为规则变量。挑选的依据是:遍历所有的变量,计算各变量的规则错误率,错误率最低的变量作为最佳规则变量。为理解该算法的思想,这里举一个简单的例子。
一个女孩要嫁人,她会综合考虑男方的三个因素:年龄、收入和职业。具体如下表所示:
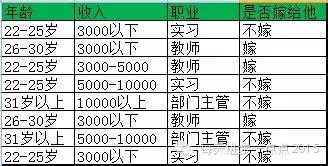
如果使用单规则算法来判别此女孩是否嫁人,可以参考下表:
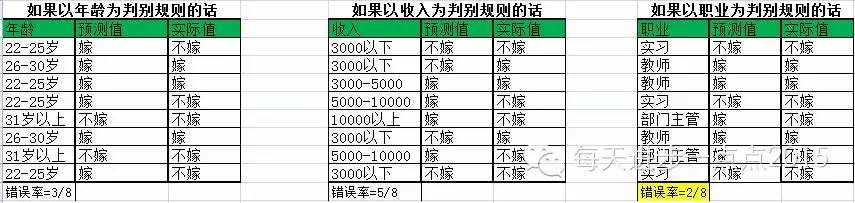
通过遍历每个变量,发现以职业为判别规则的话,错误率最低,所以职业这个变量就是被挑选出来的最佳规则变量。
2、
单规则算法优缺点
优点:
1)可以生成一个单一的、易于理解的、人类可读的经验法则
2)往往表现得出奇的好
3)可作为更复杂算法的一个基准
缺点:
只使用一个最佳规则变量,过于简单
3、R中的实现函数
单规则算法可以使用RWeka包中的OneR()函数加以实现,具体函数格式如下:
OneR(formula, data, subset, na.action,
control = Weka_control(), options = NULL)
formula模型以公式的形式表达,类似于y~x1+x2+x3;
data指定要分析的数据对象;
subset可以选取data数据集中的子集作为训练样本;
na.action
缺失值的处理方法,默认将剔除缺失数据的观测;
control可为模型添加附加条件。
二、RIPPER算法
由于单规则算法只是依赖于一个变量作为判别依据,这似乎显得非常单薄,而且还存在两个致命的缺陷,即处理大数据时效率低下;对噪声数据的分类不准确。由此,科学家又发展了该单规则算法,提出重复增量修建算法,即RIPPER算法。
该算法可以组合多个变量生成判别规则,而且还可以不断的自我修剪和优化
。
1、
RIPPER算法优缺点
优点:
1)生成易于理解且人类可读的规则
2)能很好的处理大数据集和噪声数据集
3)通常会产生比决策树更简单的规则
缺点:
处理数值型数据不太理想,所以规则算法一般要求数据集以名义变量为主或全是名义变量。
2、R中的实现函数
RIPPER算法仍然需要RWeka软件包,具体可以使用JRip()函数加以实现。该函数的具体语法如下:
JRip(formula, data, subset, na.action,
control = Weka_control(), options = NULL)
参数解释与OneR()函数一致,这里不再赘述。
三、应用–毒蘑菇识别
本文案例数据来源于http://archive.ics.uci.edu/ml/datasets/Mushroom,该数据包含21个离散的解释变量和1个二分类的因变量,总共有8124条记录。
1、单规则算法实现
#下载并加载RWeka软件包
if(!suppressWarnings(require(‘RWeka’))){
install.packages(‘RWeka’)
require(‘RWeka’)
}
#读取数据
mushrooms <- read.csv(file = file.choose(), header = TRUE,
sep = ‘,’, stringsAsFactors = TRUE)
#查看数据结构
str(mushrooms)
#生成训练数据集和测试数据集
set.seed(1234)
index <- sample(x = 1:2, size = nrow(mushrooms), replace = TRUE, prob = c(0.7,0.3))
train <- mushrooms[index == 1,]
test <- mushrooms[index == 2,]
#构建单规则算法模型
model_oner <- OneR(formula = type ~., data = train)
#查看单规则算法模型的最佳规则变量
model_oner
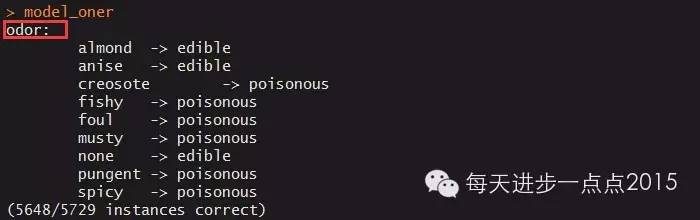
发现变量odor(气味)是最佳规则变量。
#查看单规则模型返回的概览
summary(model_oner)
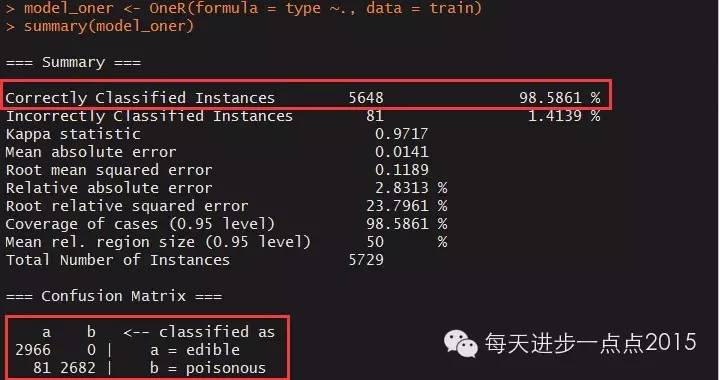
从上图结果看,训练集本身的正确判断率达到98.6%
#对测试集进行预测
pred_oner <- predict(object = model_oner, newdata = test[,-1])
#测试集上的混淆矩阵
Freq_oner <- table(pred_oner, test[,1])
Freq_oner
#预测精度
accuracy_oner <- sum(diag(Freq_oner))/sum(Freq_oner)
accuracy_oner
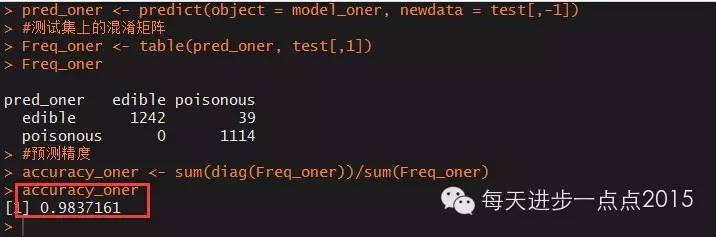
同样,模型在测试集上的准确率也超过了98%。
2、RIPPER算法实现
#构建RIPPER算法模型
model_ripper <- JRip(formula = type ~., data = train)
#查看RIPPER算法的返回规则
model_ripper
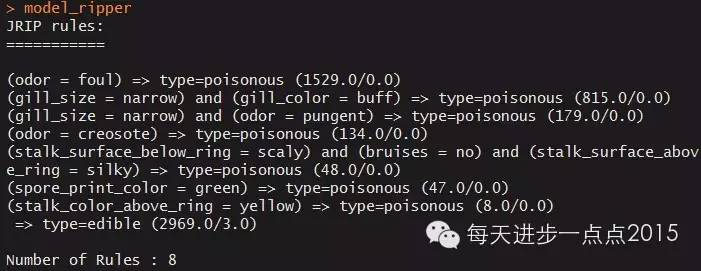
结果返回共产生8条规则。
#查看RIPPER模型返回的概览
summary(model_ripper)
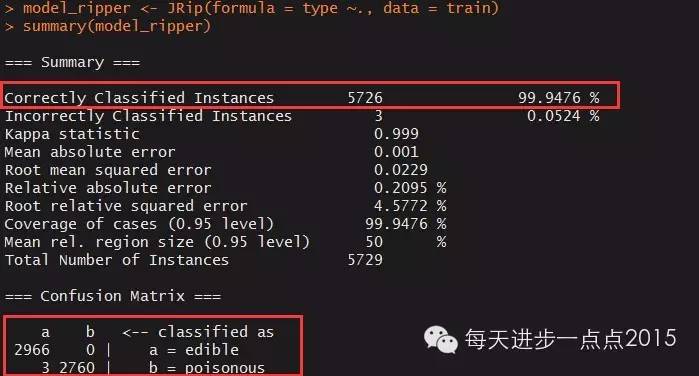
模型在训练集中的准确率几乎为100%,比单规则算法更准确
#对测试集进行预测
pred_ripper <- predict(object = model_ripper, newdata = test[,-1])
#测试集上的混淆矩阵
Freq_ripper <- table(pred_ripper, test[,1])
Freq_ripper
#预测精度
accuracy_ripper <- sum(diag(Freq_ripper))/sum(Freq_ripper)
accuracy_ripper
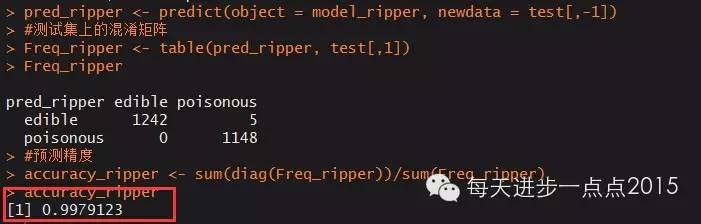
模型同样在测试数据集中也表现的非常好,准确率几乎100%。
数据集和脚本下载
文中的脚本和数据集可以到下方链接下载:
http://yunpan.cn/c3eHMekBhJL2u 访问密码 296f
总结:文章涉及到的R包和函数
read.csv()
sample()
RWeka包
OneR()
JRip()
predict()
参考文献
机器学习与R语言