数据分析概述
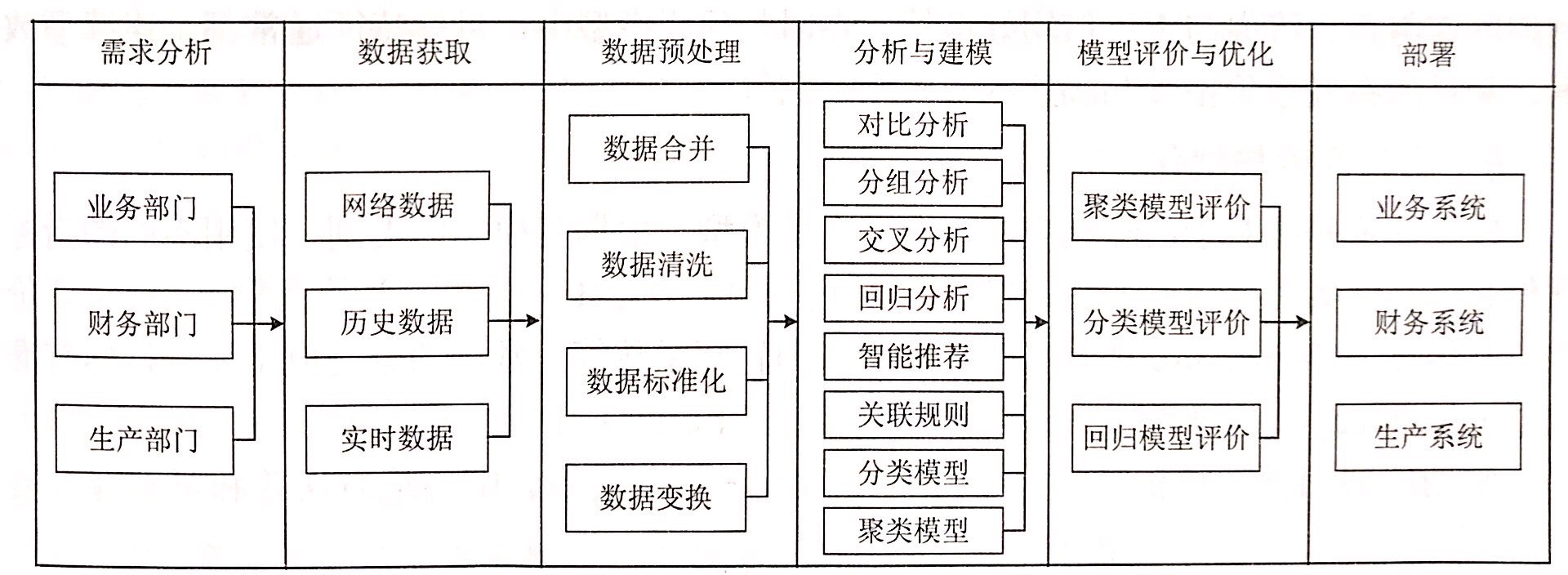
数据分析技能,被认为是数据科学领域中数据从业人员需要具备的技能之一。下图为数据分析流程:
Numpy数值计算的基础
ndarry——存储单一数据类型的多维数组(属性:ndim,sahpe,size,dtype)
ufunc——对数组进行处理的函数
1、数组的创建
将Python序列,通过函数转为数组——
numpy.array
numpy.array(object[, dtype, copy, order, subok, ndmin]))
python提供专门用于创建数组的函数——
Array creation
numpy.arange([start,] stop[, step,][, dtype]) #一维数组,指定步长,不含终值
numpy.linspace(start, stop[, num, endpoint, ...]) #一维数组,指定元素个数,包含终止
numpy.logspace(start, stop[, num, endpoint, base, ...])
#一维数组,指定原始个数,等比数列stop
numpy.ones(shape[, dtype, order]) #全一数组
numpy.zeros(shape[, dtype, order]) #全零数组
numpy.eye(N[, M, k, dtype]) #主对角线为一,其他为零的二维数组
numpy.diag(v[, k]) #除主对角线上元素外,其他为零的二维数组
使用numpy生成随机数——
numpy.random
numpy.random.random([size]) #生成[0.1-1.0)之间的随机数
numpy.random.rand(d0, d1, …, dn) #生成给定形状的服从均匀分布的随机数
numpy.random.randn(d0, d1, …, dn) #生成给定形状的服从正态分布的随机数
numpy.random.randint(low, high=None, size=None, dtype='l')
#生成给定上下限范围的随机数2、数组的访问
import numpy as np
arr = np.array([[1,2,3,4],[2,3,4,5],[3,4,5,6]])
arr[:-1,0::2] #这里2为步长,:-1包括开始不包括结束
#输出结果out: array([[1, 3],[2, 4]])
arr[[(0,1,0),(0,2,3)]] #这里取的为arr[0,0],arr[1,2],arr[0,3]
#输出结果out: array([1, 4, 4])
arr[1:,(0,1,3)] #整数函数索引,索引2,3行中第0,1,3列的元素
#输出结果out: array([[2, 3, 5],[3, 4, 6]])
arr[[True, False,True]] #布尔索引,索引0,2行中的元素
#输出结果out: array([[1, 2, 3, 4],[3, 4, 5, 6]])3、数组形态变换
使用reshape函数改变数组维度,要求指定位数和数组的元素数目吻合——
reshape
numpy.ndarray.reshape(shape, order='C')
numpy.reshape(arr,newshape,order ='C' )
eg:numpy.reshape(arr,(2,6))
arr.reshape(2,6) #两者等价,返回形状的数组,均不改变arr本身的形状
使用ravel和flatten展平数组——
arrays.ndarray
arr.ravel() #横向展平,结果为[1,2,3,4,2,3,4,5,3,...]
arr.flatten() #横向展平,结果为[1,2,3,4,2,3,4,5,3,...]
arr.flatten('F') #纵向展平,结果为[1,2,3,2,3,4,3,4,5,...]
对数组进行组合和分割——
numpy.hstack…
numpy.hstack(tup) #使用函数进行横向组合
numpy.vstack(tup) #使用函数进行横向组合
numpy.concatenate(tup,axis = 1) #使用函数进行横向组合
numpy.concatenate(tup,axis = 0) #使用函数进行横向组合
numpy.hsplit(ary, indices_or_sections) #使用函数进行横向切割
numpy.vsplit(ary, indices_or_sections) #使用函数进行纵向切割
numpy.split(ary, indices_or_sections, axis=0) #axis=0纵向切割 axis=1横向切割3、矩阵
Numpy对于多维数组,默认不行进行矩阵运算,矩阵运算时针对整改矩阵中每个元素进行的
创建矩阵函数——
numpy.mat
,
numpy.matrix
arr1 = [[1,2],[2,3]]
arr1*3
#输出结果out: [[1, 2], [2, 3], [1, 2], [2, 3], [1, 2], [2, 3]]
arr2 = np.matrix(arr1)
arr2 = arr2*3
#输出结果out: matrix([[3, 6],[6, 9]])
np.bmat("arr1 arr2; arr2 arr1")
#根据小矩阵创建大矩阵,输出结果
#out: matrix([[1, 2, 3, 6],[2, 3, 6, 9],[3, 6, 1, 2],[6, 9, 2, 3]])4、常用函数
排序,sort直接对数值进行排序;argsort和lexsort根据一个或多个键对数据进行排序——
numpy.ndarray.sort
numpy.ndarray.sort(axis=-1, kind='quicksort', order=None)
#沿无返回值,着横轴排序
numpy.argsort(a, axis=-1, kind='quicksort', order=None)[source]
#返回将对数组进行排序的索引,axis默认值是-1(最后一个轴)
numpy.lexsort(keys, axis=-1)
#使用一系列键执行间接排序,多键排序时是按照最后一个传入参数计算的。
#keys的形式(arr1,arr2,arr3)
numpy中可以通过
numpy.unique
函数找出数组中的唯一值并返回已排序结果,
numpy.tile
函数对数组进行重复操作,
numpy.repeat
函数对数组中每个元素进行重复操作
numpy.unique(ar, return_index=False, return_inverse=False,\
return_counts=False, axis=None)
numpy.tile(A, reps)
numpy.repeat(A, repeats, axis=None)
#axis=0沿着纵轴进行元素重复,axis=1沿着横轴进行元素重复在Numpy中常见的统计函数有sum、mean、std、var(方差=std*std)、min、max等。当axis参数为0时,表示沿着纵轴进行计算。当axis为1时,表示沿着横轴进行计算。但是在默认时,计算一个总值。上述计算均为聚合计算,若要产生中间结果的组成数组可以使用cumsum、cumprod函数。
arr = np.arange(2,10)
np.cumsum(arr) #计算所有元素的累计和
#输出结果out: [2 5 9 14 20 27 35 44]
np.cumprod(arr) #计算所有元素的累计积
#输出结果out: [2 6 24 120 720 5040 40320 362880]
5、实训:
创建一个国际象棋棋盘
+
Python绘图Turtle库详解
Matplotlib数据可视化基础
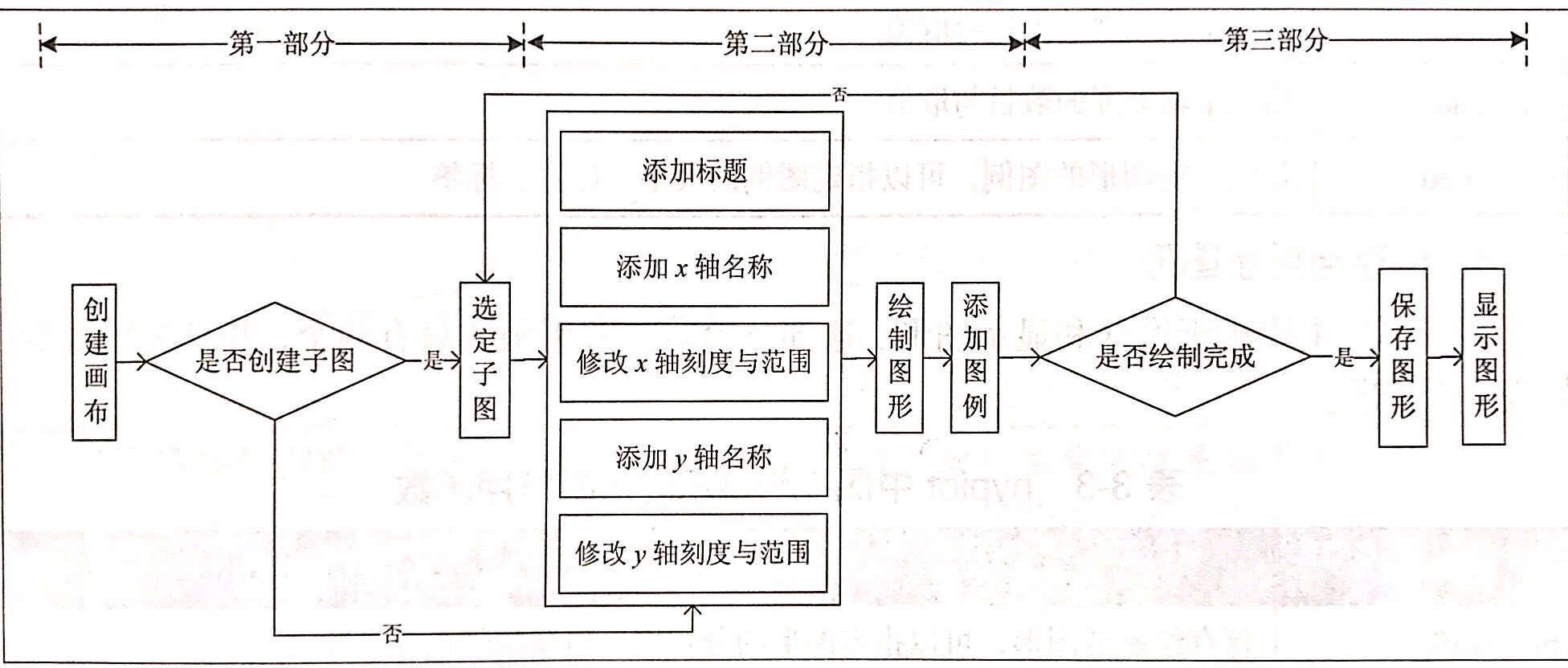
Matplotlib中应用最广的是matplotlib.pyplot模块,pyplot的基本流程如图所示
pyplot使用rc配置文件来自定义图形的各种属性。所有存储在变量中的rc参数,都被称为rcParams
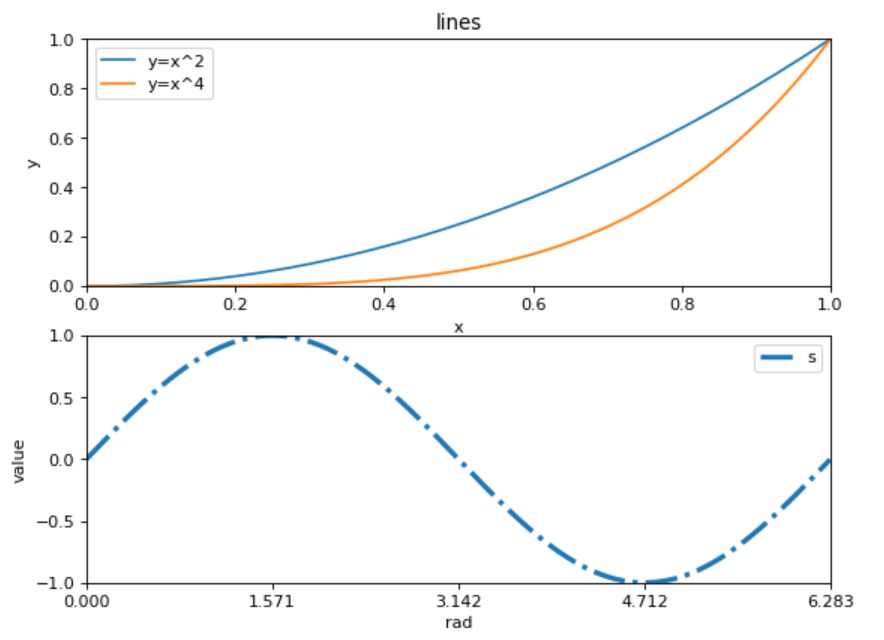
import numpy as np
import matplotlib.pyplot as plt
rad = np.arange(0,np.pi*2,0.01)
##第一幅子图
p1 = plt.figure(figsize=(8,6),dpi=80)## 确定画布大小
ax1 = p1.add_subplot(2,1,1)## 创建一个两行1列的子图,并开始绘制第一幅
plt.title('lines')## 添加标题
plt.xlabel('x')## 添加x轴的名称
plt.ylabel('y')## 添加y轴的名称
plt.xlim((0,1))## 确定x轴范围
plt.ylim((0,1))## 确定y轴范围
plt.xticks([0,0.2,0.4,0.6,0.8,1])## 规定x轴刻度
plt.yticks([0,0.2,0.4,0.6,0.8,1])## 确定y轴刻度
plt.plot(rad,rad**2)## 添加y=x^2曲线
plt.plot(rad,rad**4)## 添加y=x^4曲线
plt.legend(['y=x^2','y=x^4']) ##添加图例
##第二幅子图
ax2 = p1.add_subplot(2,1,2)## 创开始绘制第2幅
plt.rcParams['lines.linestyle'] = '-.'
plt.rcParams['lines.linewidth'] = 3
plt.xlabel('rad')
plt.ylabel('value')
plt.xlim((0,np.pi*2))
plt.ylim((-1,1))
plt.xticks([0,np.pi/2,np.pi,np.pi*1.5,np.pi*2])
plt.yticks([-1,-0.5,0,0.5,1])
plt.plot(rad,np.sin(rad))
plt.legend('sin')
plt.savefig('../tmp/tup.png') ##保存图形
plt.show() ##显示图形
pandas统计分析基础
DataFrame是最常用的padas对象,完成数据读取后,数据就以DataFrame的数据结构存储在内存中。常用的基础属性包括:元素values、索引index、列名columns、类型dtypes、元素个数size、维度数ndim、数据形状shape、转置T等。
DataFrame为一个带有标签的二维数组,每一个标签相当于一列的列名,可以以典访问的形式访问某一列数据。DataFrame的单列数据为一个Series,其访问方式基本和一个一维的ndarry相同。使用head和tail方法可以取首/末的多行数据,默认行数为5。
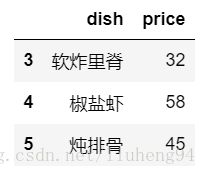
import pandas as pd
data = pd.DataFrame({"dish":["锅包肉","地三鲜","溜肉段","软炸里脊","椒盐虾",\
"炖排骨"],"price":[38,16,32,32,58,45],"star":[4.0,3.5,4.0,3.0,4.5,3.8]})
data[["dish","price"]][3:]
pandas提供了
pandas.DataFrame.loc
和
pandas.DataFrame.iloc
两种更加灵活的方法来实现数据访问
DataFrame.loc[行索引名称或条件,列索引名称] #eg 1:3代表前后均闭区间
DataFrame.iloc[行索引位置或布尔数组,列索引位置] #eg 1:3代表前闭后开区间
对于数据处理使用
drop
可以删除某列或某行数据。同时,作为专门为数据分析而生的库,pandas提供一个叫做
describe
的方法,能够一次性的得出数据框中所有的数值型特征的非空值数目、均值、四分位数和标准差。(value_counts函数可以对Series进行词频统计)
## 定义一个函数去除全为空值的列和标准差为0的列
def dropNullStd(data):
colisNull = data.describe().loc['count'] == 0
for i in range(len(colisNull)):
if colisNull[i]:
data.drop(colisNull.index[i],axis = 1,inplace =True)
stdisZero = data.describe().loc['std'] == 0
for i in range(len(stdisZero)):
if stdisZero[i]:
data.drop(stdisZero.index[i],axis = 1,inplace =True)
afterlen = data.shape[1]2、使用分组聚合进行组内计算
依据某个或某几列字段对数据进行分组,并对各组应用一个函数,无论数聚合还是转换,都是数据分析的常用操作。pandas提供一个灵活高效的groupby方法,配合agg方法或apply方法,能够实现分组聚合的操作,原理如下:
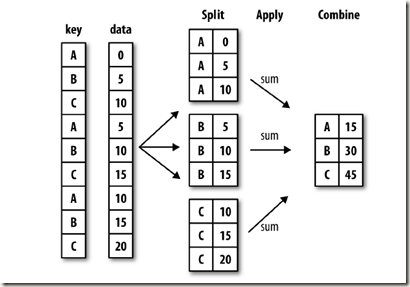
#by:用于确定分组的依据,接收list、string、mapping或generator
#axis:操作的轴向,默认为对列进行操作,为0。
#sort:表示是否对分组依据、分组标签进行排序,默认为True
#注意返回的数据类型不是一个数据框,而是一个GroupBy对象
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, observed=False, **kwargs)
#分组后,即GroupBy常用描述性统计方法有:count、head、max、cumcount、size、std、sum、mean、median等
#针对每个分组应用某函数,进行聚合操作,func接收list、dict、function
#注意在自定义函数中使用NumPy函数,在计算单个序列的时候,得到的结果可能不是想要的聚合结果
DataFrame.agg(func, axis=0, *args, **kwargs)
detail.agg({'counts':np.sum,'amounts':[np.mean,np.sum]})
#apply方法传入的函数只能够作用于整个DataFrame或Series,而无法像agg一样能够对不同的字段应用不同的函数来获取不同的结果
DataFrame.apply(func, axis=0, broadcast=None, raw=False, reduce=None, result_type=None, args=(), **kwds)
#transform方法能够对整个DataFrame的所有元素进行曹锁
#还能够对DataFrame分组后的GroupBy对象进行操作,实现组内离差标准化等操作。
DataFrame.transform(func, *args, **kwargs)
3、使用pandas进行数据预处理
通过堆积合并、主键合并、横向合并和纵向合并,等多种方式,可以将关联的数据合并在一张表中
pandas.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,\
keys=None, levels=None, names=None, verify_integrity=False,sort=None,copy=True)
#objs: series,dataframe或者是panel构成的序列lsit
#axis: 需要合并链接的轴,0是行,1是列
#join: 连接的方式 inner,或者outer
#keys: 加上一个层次化索引,识别数据源自于哪张表
DataFrame.append(other, ignore_index=False, verify_integrity=False, sort=None)
#纵合并两张表的列名需要完全一致
DataFrame.merge(right, how='inner', on=None, left_on=None, right_on=None,\
left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'),\
copy=True, indicator=False, validate=None)
#主键合并数据,根据某几个字段将表拼接起来
#left: 接收DataFrame或Series。表示要添加的新数据1。
#right: 接收DataFrame或Series。表示要添加的新数据2。
#how: 数据融合的方法inner、outer、left、right.
#on: 列名,对齐的那一列的名字.
#left_on: 左表对齐的列,可以是列名,也可以是和dataframe同样长度的arrays。
#right_on: 右表对齐的列,可以是列名,也可以是和dataframe同样长度的arrays。
#left_index/ right_index: 如果是True的haunted以index作为对齐的key.
#sort:根据dataframe合并的keys按字典顺序排序,默认是false。
DataFrame.join(other, on=None, how='left', lsuffix='', rsuffix='', sort=False)
#部分主键合并,主键名需要完全一致
DataFrame.combine_first(other)
#重叠合并,用于处理两份数据几乎一致,但是某些特征在其中一张表上是完整的,
#而在另一张表上的数据则是缺失的情况清洗数据的过程主要包括检查与处理重复值、缺失值、异常值等
#去除重复记录, first保留第一个,last保留最后一个,false只要重复都不保留
DataFrame.duplicated(subset=None, keep='first')
#去除重复记录,将特征间相似度为1的特征去除,或利用DataFrame.equals方法进行特征去重
corrDet = detail[['counts','amounts']].corr(method='kendall')
def FeatureEquals(df):
dfEquals=pd.DataFrame([],columns=df.columns,index=df.columns)
for i in df.columns:
for j in df.columns:
dfEquals.loc[i,j]=df.loc[:,i].equals(df.loc[:,j])
return dfEquals
#删除缺失值记录,0代表行,1代表列,how可以取any或all
detail.dropna(axis = 1,how ='any',subset=['dish_name','counts'])
#替换缺失值记录
detail.fillna(-99)
常用的插值法有线性插值、多项式差值、和样条插值等。pandas提供了对应名称为interpolate的模块,但是SciPy的interpolate模块更加全面。
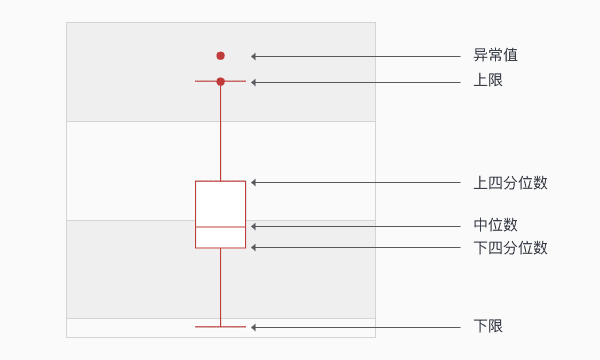
异常值是指数据中个别值的数据明显偏离其余的数值,有时也称为离群点,检测异常值就是检测数据中是否有输入错误以及是否有不合理的数据。常用的异常值检测主要有3σ原则和箱线图分析两种方法。
3σ原则:仅适用于正态或近似正态分布的样本,超出(u-3σ,u+3σ)范围的数据可认为为异常数据。
箱线图:箱线图依据实际数据绘制,真是、直观地表现出了数据分布的本来面貌,且没有对数据做任何限制性要求,异常值被定义为超出(QL-1.5IQR,QH+.5IQR)的值,QL/QH为下/上四分位数,IQR=QH-QL。如果箱形图很扁,异常值很多可以尝试进行对数变换。
使用scikit-learn构建模型
sklearn库整合了多种机器学习算法,拥有优秀的官方文档。
datasets模块继承了部分数据分析的经典数据集,加载后的数据可以视为一个字典,可以使用data、target、feature_names、DESCR获取数据集的数据、标签、特征名称和描述信息。
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer() #将数据集赋值给变量
print("输出前4个特征名称:",cancer['feature_names'][:4])
#输出前4个特征名称: ['mean radius' 'mean texture' 'mean perimeter' 'mean area']sklearn提供了model_selection模块、preprocessing数据预处理模块与decompisition特征分解模块。通过这三个模块能够实现数据预处理与模型构建前的数据标准化、二值化、归一化、数据集的分割、交叉验证和PCA降维等工作。
from sklearn.model_selection import train_test_split #划分数据集
dtrain, dtest,ttrain, ttest = train_test_split(cancer['data'],\
cancer['target'],test_size=0.2)
from sklearn.preprocessing import MinMaxScaler
Scaler = MinMaxScaler().fit(dtrain) #生成标准化规则
cancer_trainScaler = Scaler.transform(dtrain) #将规则应用于训练集
cancer_testScaler = Scaler.transform(dtest) #将规则应用于测试集
from sklearn.decomposition import PCA
pca_model = PCA(n_components=10).fit(cancer_trainScaler) #生成PCA降维规则规则
cancer_trainPca = pca_model.transform(cancer_trainScaler) #将规则应用于训练集
cancer_testPca = pca_model.transform(cancer_testScaler) #将规则应用于测试集
#降维前后测试集:(455, 30),(455, 10)
StandardScaler #对特征进行标准差标准化
Normalizer #对特征进行归一化
Binarizer #对定量特征进行二值化处理、
OneHotEncoder #对定性特征进行独热编码处理
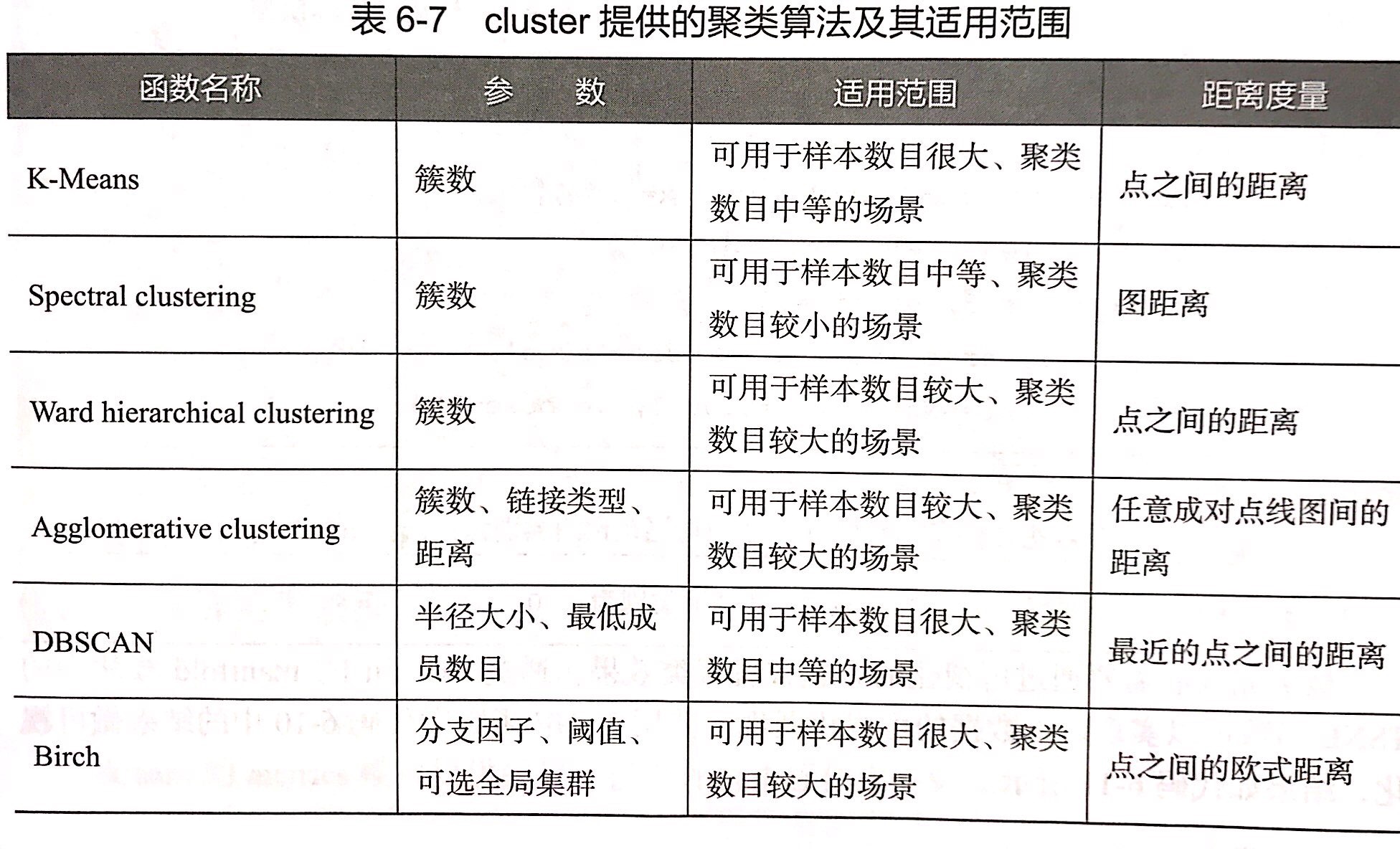
FunctionTransformer #对特征进行自定义的函数变换构建评价聚类模型
fit #主要用于训练算法
predict #主要用于监督学习
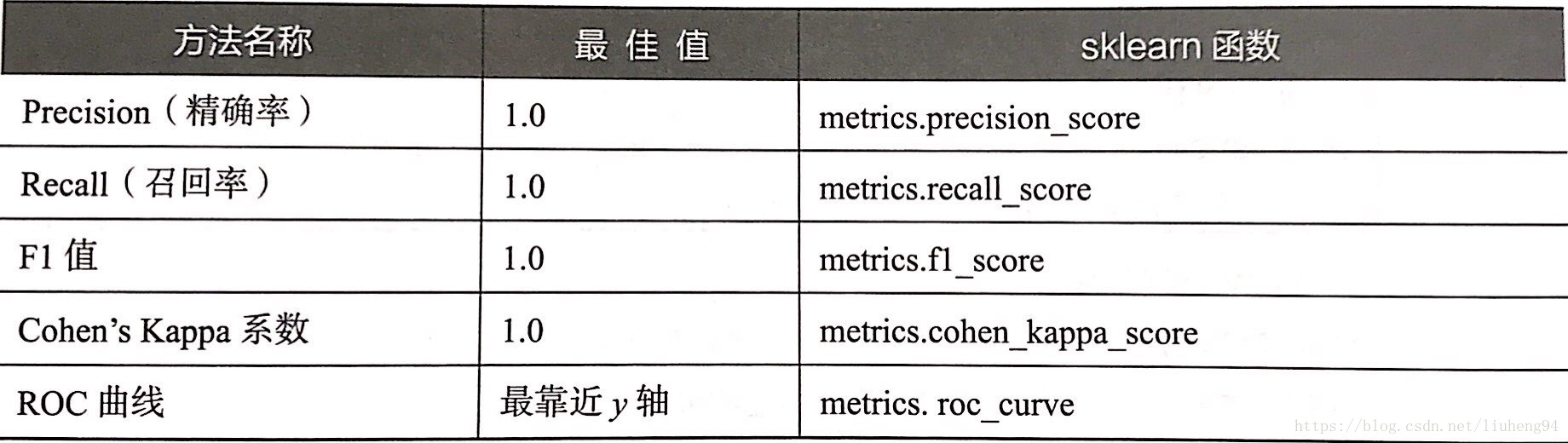
构建评价分类模型
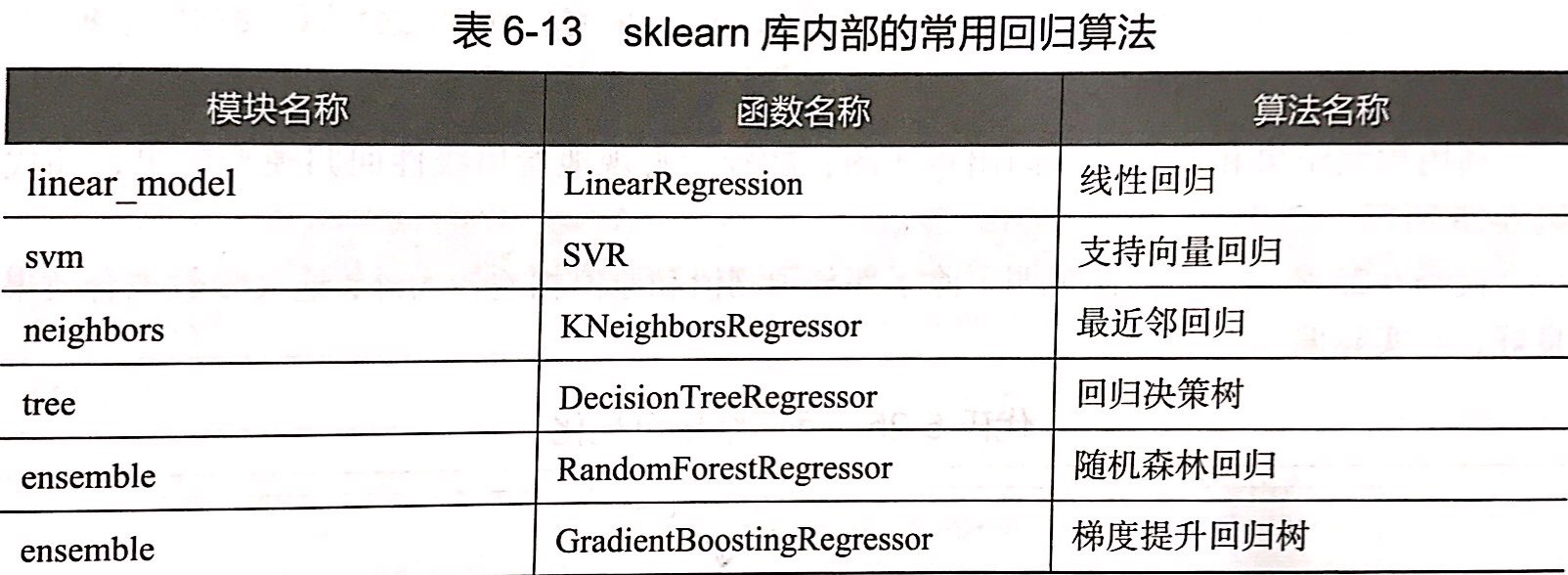
构建评价回归模型

##加载所需函数
from sklearn.linear_model import LinearRegression
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
## 加载boston数据
boston = load_boston()
X = boston['data']
y = boston['target']
names = boston['feature_names']
## 将数据划分为训练集测试集
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.2,\
random_state=125)
## 建立线性回归模型
clf = LinearRegression().fit(X_train,y_train)
print('建立的LinearRegression模型为:','\n',clf)
## 预测训练集结果
y_pred = clf.predict(X_test)
print('预测前20个结果为:','\n',y_pred[:20])
##评价模型性能
from sklearn.metrics import explained_variance_score,mean_absolute_error,\
mean_squared_error,median_absolute_error,r2_score
mean_absolute_error(y_test,y_pred) #平均绝对误差
mean_squared_error(y_test,y_pred) #均方误差为
median_absolute_error(y_test,y_pred) #值绝对误差
explained_variance_score(y_test,y_pred) #可解释方差值
r2_score(y_test,y_pred) #R方值