今天要分享的论文是ICMV2017的一篇非常巧妙的论文。作者是
论文下载链接:
https://arxiv.org/abs/1710.00886
关于论文的源码下载链接:
https://sites.google.com/site/nimahatami/projects
(然而,这个链接,反正我是被墙了,挂VPN好像也没什么用,然后向作者Hatami求助才下载到)这篇论文的源码很短,看上去很简单,嗯,看上去。我还没细看,但已经跑过了。
论文的
PDF和源码,还有我的PPT
,都上传到CSDN下载资源里面,链接在此:
https://download.csdn.net/download/luolan9611/10537857
如果讲解有误,虚心接受指正。
1.摘要概括:
大多数时间序列分类(TSC)文献都针对于一维信号,但本文使用递归图RP将时间序列转换为二维纹理图像,然后利用深度CNN分类器识别。本文将序列分类问题转换为了图像识别分类问题,针对UCR时间序列分类档案馆(UCR time-series classication archive)的数据集进行实验,证明了所提出方法与现有的深层架构和最先进的TSC算法相比都有极大的准确性。
2.核心方法:
方法主要分为两步,
第一步:将时间序列编码成RP递归图。

三张小图中最左边的是包含12个数据点的时序信号示意图记为
(1)
,中间的是根据时序信号画的二维相空间轨迹示意图记为
(2)
,最右边的是递归图记为
(3)
,该递归图其实是个11*11大小的矩阵。
从(1)到(2):(1)上有12个红点
x
,点到点为一个状态
s
,所以有11个状态。状态
sn:(xn,xn+1)
。也就是说状态sn的位置是(第x个数据点的纵坐标值,第x+1个数据点的纵坐标值)。自己去试着画一画,就能看到(2)中为什么箭头下来到达s3,又上去到达s4了。
从(2)到(3):根据上图Ri,j的那个公式计算R矩阵,用matl。然后前面有一个像e的符号,那个代表的是阈值,用于将彩色的rp图进行阈值化的。因为本文做的实验是直接将rp做成了灰度图,所以那个阈值好像没太管。具体的可以看看论文。然后整体是一个阶跃函数。K是状态s的个数。
第二步:使用深度CNN进行分类识别。

该深度网络的架构如上图所示。有两个卷积层,每个卷积层后的跟着一个ReLU修正线性单元,又两个池化层使用2*2最大池化方法,有2个全连接层。其中C1(size)-S1-C2(size)-S2-H-O,C1和C2是两个卷积层filter的个数,size是kernel大小,H是隐藏层神经元的个数,c表示输出神经元的个数,其实就是要分多少类。
输入的图像大小是有要求的,28*28,56*56,64*64.
3.实验过程:
UCR时序档案馆链接:
http://www.cs.ucr.edu/~eamonn/time_series_data/
(可以自己上链接去下数据集哦)该链接是作者给的官方链接,作者的数据就是从上面找的。作者从几十组数据中挑选了20组数据集,和现今的一些时序分类算法做了对比实验。
我自己在网上找了个链接:
http://www.timeseriesclassification.com/dataset.php
(该链接中点进每一个数据集,会有对这个数据集的介绍,有图有描述,觉得很棒。也可以在上面下载数据集。)
3.1先给大家介绍一些数据集:
比如50words:这个分类的话就有50个类

比如:Face all和Olive oil:Face all有14个类,Olive oil有4个

比如Coffe和Yoga:Coffe有2个类,Yoga也有2个类

这些数据集都是源于现实生活,想不到吧,这么多神奇的问题居然都被转化成了序列,然后用序列去进行分类。
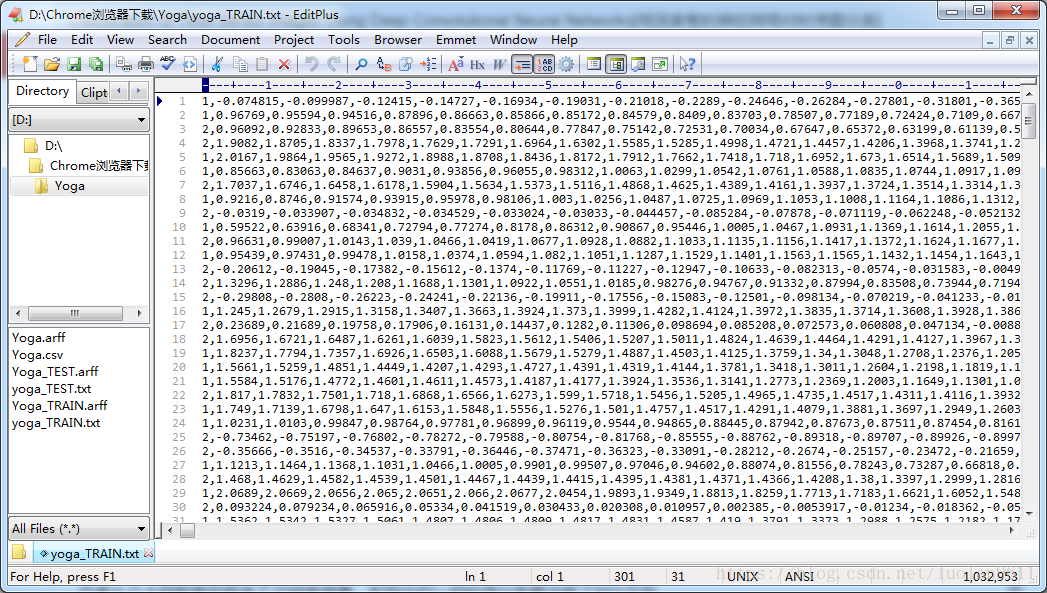
这个思路真的妙~采集到的序列是这样子的,给大家看看数据集
,比如我下到的Yoga的数据集,打开train.txt:第一个数是标签,应该代表男或女,后面的就是序列数据了。
3.2然后就是把序列数据集制作成RP图(使用MatLab)

3.3用深度CNN训练分类
输入大小有要求:28*28,56*56,64*64
2*2最大池化,Dropout=0.25
全连接层包含128个隐藏的神经元和c个输出神经元,Dropout=0.5
tips: Dropout是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。Dropout用来防止过拟合提高训练效果。
4.实验结果:
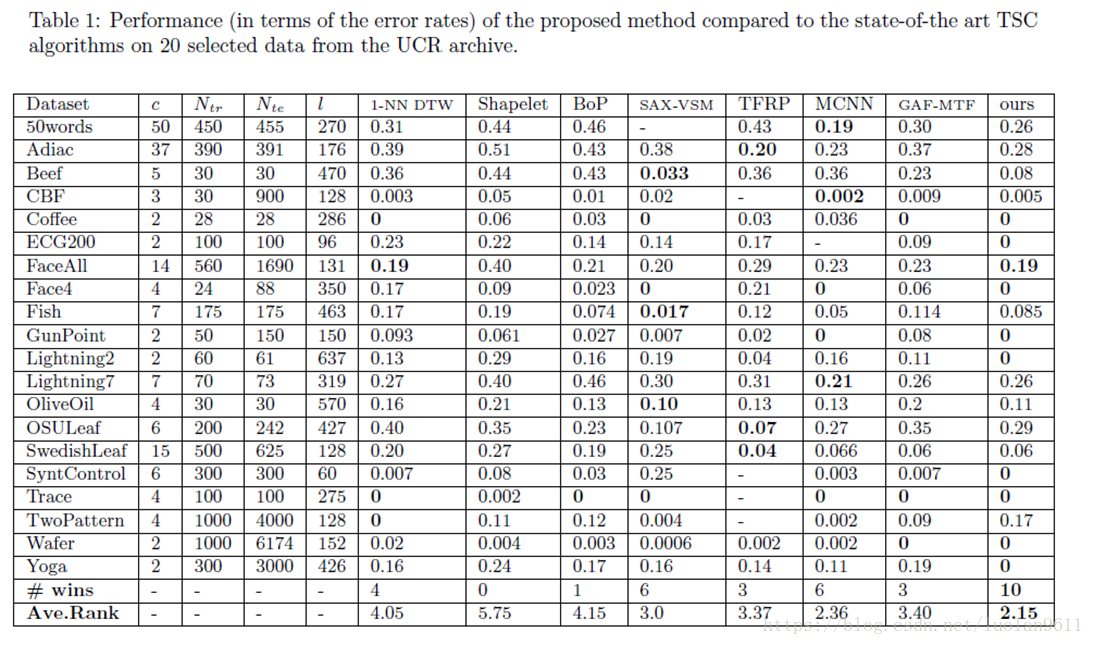
作者是挑选了20组数据和其它的方法做的实验。表头中c指的是分类类别,Ntr是训练样本数,Nte是测试样本数,l指的是序列长度。后面的都是别的方法名称。表中展示的是
错误率
。针对每种数据集,错误率最低的被
加粗
显示。作者的方法在10种数据集中都取得了第一名,然后计算了一个平均排位。作者使用的方法的平均排位是最高的。
好啦,今天这篇论文就分享到这里。
针对本论文我做了一个PPT,缩略图展示如下:

论文的
PDF和源码,还有我的PPT
,都上传到CSDN下载资源里面,链接在此: