Inception v1
1.核心思想
通过增加网络宽度,结合不同kernel的feature map进行concat,来增加网络的感受野组合,有效提高对原始像素信息与网络内部资源的利用率。
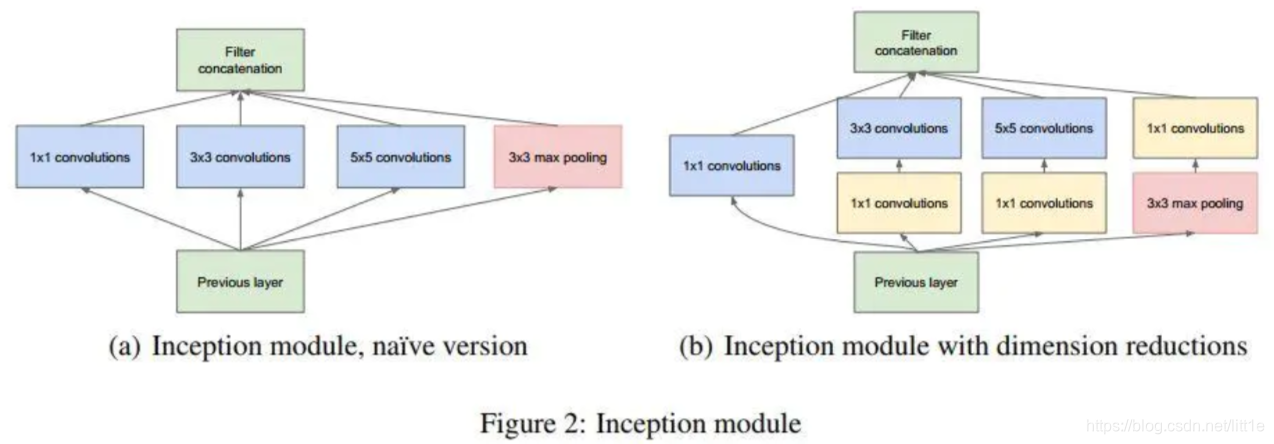
为了降低inception block的计算成本,作者用1×1卷积先将feature降维(降低channel)再分别于其他kenerl卷积。GoogLeNet在中间的两个Inception模块后增加了辅助分类器输出,其损失乘以权重0.3加到了总损失中,这种设计可以增强反向传播的误差信号,同时带来一定的正则化效果。
2.模型结构
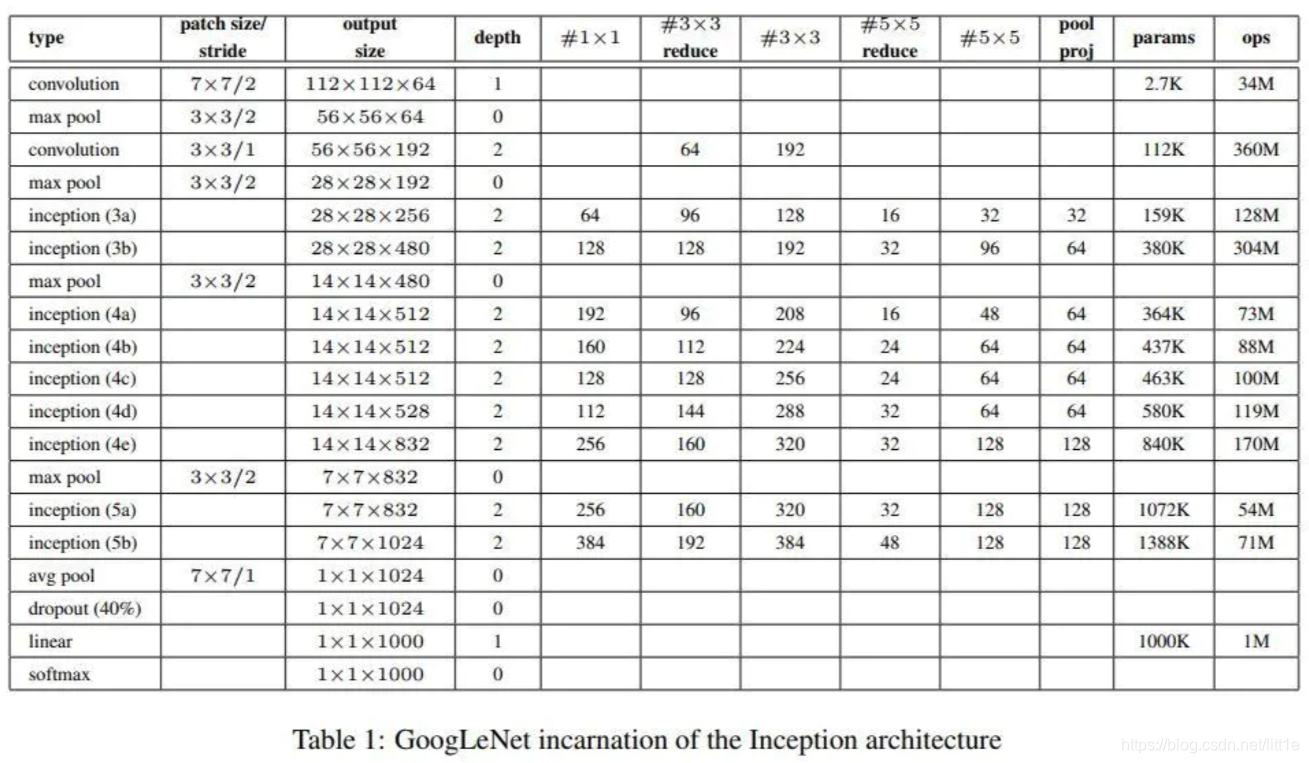
上表即为GoogleNet的网络结构设计概况。作者表明我们可以灵活地根据自己所有的硬件/软件/系统等情况来选择Inception网络中各模块的使用(modules数目及其上的conv的channels数)。不必过于拘泥于它的具体实现细节,只需了解它的本质设计思想即可。
Inception v2、v3
Inception v2 和 Inception v3 来自同一篇论文《Rethinking the Inception Architecture for Computer Vision》,作者提出了一系列能增加准确度和减少计算复杂度的修正方法。
1.核心思想
1.1 Batch Normalization(BN层应用)
首次应用BN层,减少internal covariate shift 。internal covariate shift(ICS)使得每层输入不再是独立同分布。这就造成,上一层数据需要适应新的输入分布,数据输入激活函数时,会落入饱和区,使得学习效率过低,甚至梯度消失。
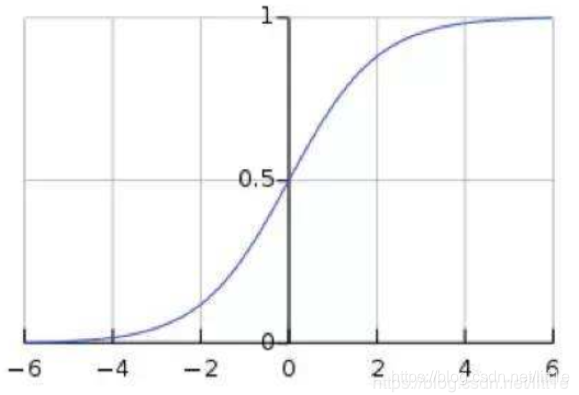
如下图,sigmoid函数,由于CNN层数多,ICS会使激活输入分布偏移,导致大部分输入落入饱和区,使得这部分的梯度出现衰减甚至消失。而BN就是通过归一化手段,将每层输入强行拉回均值0方差为1的标准正态分布,这样使得激活输入值分布在非线性函数梯度敏感区域,从而避免梯度消失问题,大大加快训练速度。
但是,归一化后,激活输入值均被分布于-1~1之间,这会导致非线性程度降低,夸张一点说,其实输入域的分布把原来的非线性函数转变成了线性函数。这意味着网络的表达能力下降了。因此BN为了保证非线性,对变换后的满足均值为0方差为1的x又进行了scale shift操作,即y=scale*x+shift。这两个参数通过训练获得,其实又将输入分布在标准正态分布的基础上进行了平移。其实就是为了在线性与非线性间找到平衡,让泛化能力与收敛能力最大程度的体现。
2.模型结构
大尺寸的卷积核可以带来更大的感受野,但也意味着更多的参数,比如5×5卷积核参数是3×3卷积核的25/9=2.78倍。为此,作者提出可以用2个连续的3×3卷积层(stride=1)组成的小网络来代替单个的5×5卷积层,(保持感受野范围的同时又减少了参数量),并且可以避免表达瓶颈,加深非线性表达能力。
总结来讲,用小尺度卷积级联的方式的优点有以下:
- 增大感受野,同时降低计算成本。(相比于大尺寸卷积核)
- 卷积级联附带激活函数,增加网络非线性表达能力。
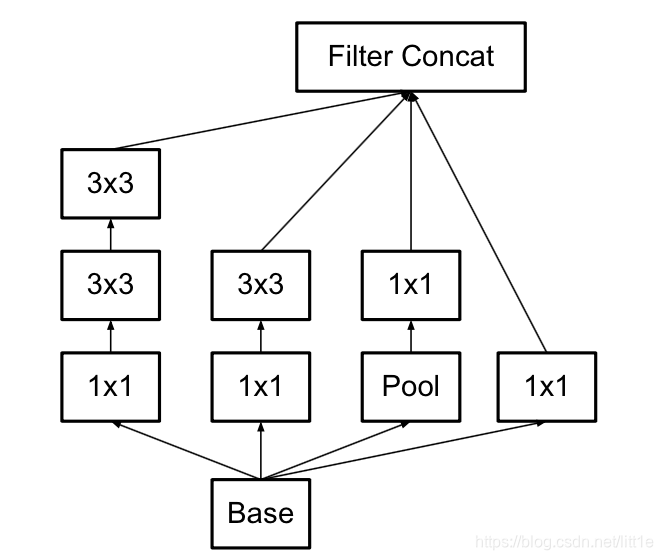
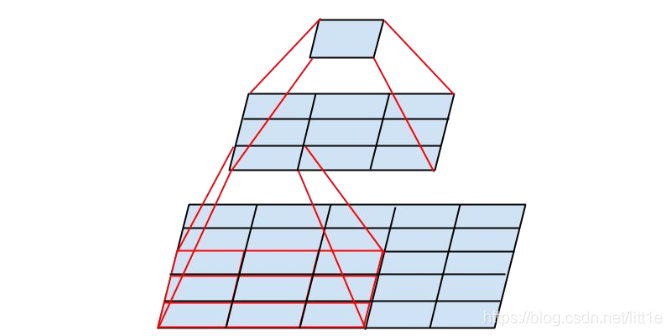
此外,作者将 n×n 的卷积核尺寸分解为 1×n 和 n×1 两个卷积。例如,一个 3×3 的卷积等价于首先执行一个 1×3 的卷积再执行一个 3×1 的卷积。他们还发现这种方法在成本上要比单个 3×3 的卷积降低 33%,这一结构如下图所示:
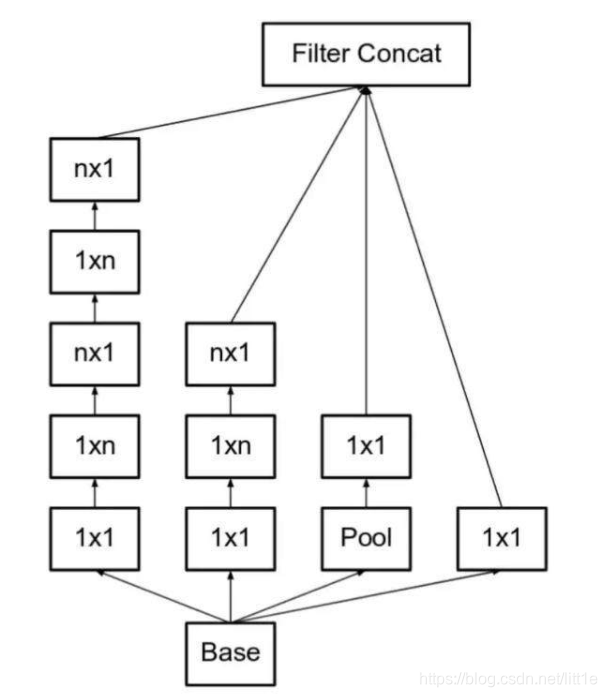
Inception-v3比Inception-v2增加了几种处理:(1)RMSProp优化器;(2)使用了LabelSmoothing;(3)7×7卷积变成了1×7和7×1的卷积核叠加;(4)辅助分类器使用了 BatchNorm。 同时输入图像大小变成299×299。
3.label smooth:
在常见的多分类问题中,先经过softmax处理后进行交叉熵计算,原理很简单可以将计算loss理解为,为了使得网络对测试集预测的概率分布和其真实分布接近,常用的做法是使用one-hot对真实标签进行编码,作者认为这种将标签强制one-hot的方式使网络过于自信会导致过拟合,因此软化这种编码方式。
如下,qi是label smoothing后的标签,可以看到,当i=y时,qi变成了比1小的数,同时,原来qi为0的情况,都通过均值提高了。K表示label数。
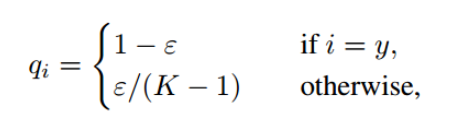
Inception v4 和 Inception-ResNet-v1、 Inception-ResNet-v2
在文章中,作者设计了新的Inception-v4结构,同时结合ResNet,设计了Inception-ResNet-v1、Inception-ResNet-v2结构。文章主要提到引入Residual Block能显著加快训练速度。
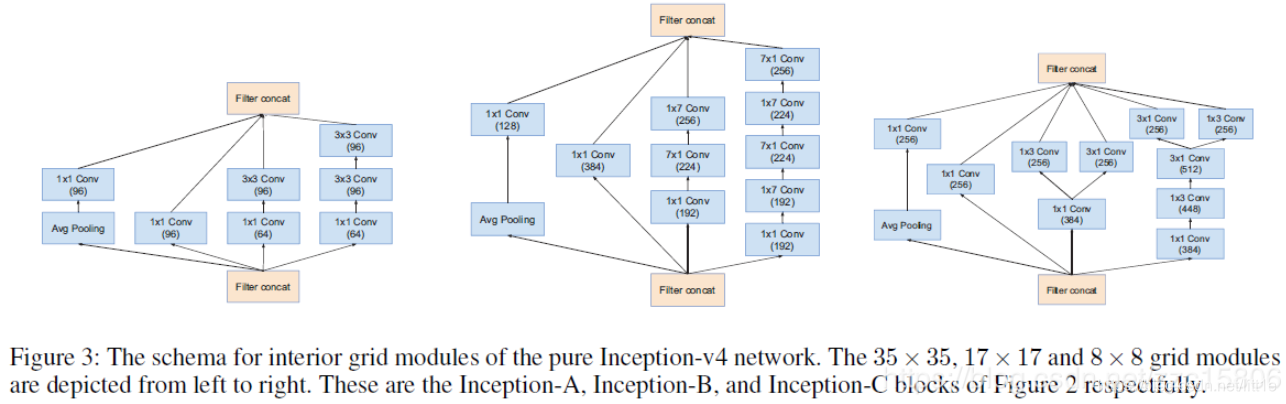
Inception V4是存粹的inception结构,没有参杂残差思想。上图是inception v4提取不同特征维度的block。思想一脉相承,使用了inception多分路结构,不同的Inception模块的连接,减小了feature map,却增加了filter bank。
inception-resnet结合版本的模型结构其实就是在inception网络上加入残差。作者们在训练的过程中发现,如果通道数超过1000,那么Inception-resnet等网络都会开始变得不稳定,并且过早的就“死掉了”,即在迭代几万次之后,平均池化的前面一层就会生成很多的0值。作者们通过调低学习率,增加BN都没有任何改善。不过他们发现如果在将残差汇入之前,对残差进行缩小,可以让模型稳定训练。