本文所使用的软件版本如下
filebeat 5.4.0,
elasticsearch 5.4.0,
kibana 5.4.0,
最近公司需要做实时日志分析系统,在网上查了很多资料,发现ELK是最适合的,而且是开源,官方文档还算详细。
尽管ELK环境搭建在网上一搜一大片,即使如此我还是花了好几天的时间才能搭好,因为其中很多很多细节网上没有提到。所以希望将我搭的过程中遇到的问题分享出来。
在这过程中学习到了很多东西,其中最重要的一点就是,多看官方原版英文文档,不要看中文翻译的,不要看中文翻译的,不要看中文翻译的!! 其中stackoverflow是比较好用的网站!!!
指导人很牛,给了很多的建议以及指导。以前安装软件只知道用yum,apt-get等等,基本没用过源码安装。指导人一句话给我讲明白了,原话是这样说的:yum ,apt-get等等安装方法说白了就是windows安装软件时的下一步下一步。。
根本没有选择路径的权利,基本都是安装在/opt,
配置文
件在/etc/…下,而且对于不同的软件,下载的位置根本不对,这样就不便于集中管理。我之前就是这么安装的ELK,但是全卸载了。因为实在是不容易管理,看配置还要换很多目录,切换的烦。所以全部用源码安装。
啥是源码安装啊?说白了就是从官方下载压缩文件,什么.tar,.tar.gz格式的文件,然后在linux下解压,这样就会形成一个目录,这就是源码安装。简单吧!!
1.ELK工作流程图(十分关键,不理解就没法配置环境!)
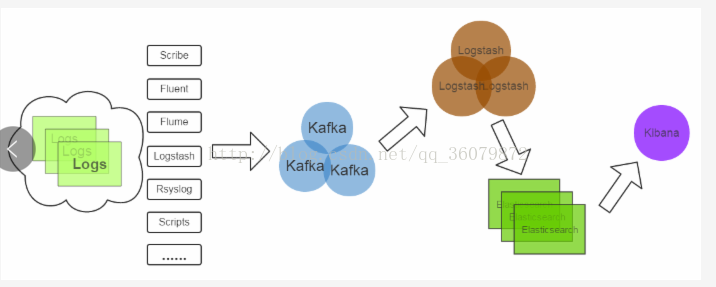
(1)首先最左侧这几个都是logstash agent,我们可以选择其中一种,logstash agent是运行在我们想要收集日志的机器上的,也就是我们想收集哪台机器的日志,我们就把logstash agent安装在哪台机器上。他的作用是收集日志,其中可以选择过滤掉一些日志的行,我们可以设置,下面有详细说明。
(2)logstash agent收集的数据要发送给kafka,这样为了防止在网络阻塞的时候数据丢失。相当于缓冲区,kafka具体内容不介绍,就当个黑盒就好了。logstash agent相当于kafka的producer。
(3)然后logstash从kafka中pull(拉)消息,当做kafka的consumer。
(4)logstash可以将日志解析,(这个解析很抽象,我们见下面的例子),然后将数据发送到elasticsearch,elasticsearch是负责存储数据的。
(5)kibana是展示端,仅仅负责展示ES中存储的数据。
2.配置客户机,filebeat的配置
2.1我们首先配置客户机(也就是我们想在这台机器上获得日志)
我们只需要安装一种logstash agent就可以了,我们选择filebeat,比较轻量级,对CPU负载不大,不占用太多资源。
解压了filebeat后,进入filebeat文件夹,你会发现如下的目录结构:
我们只需要配置filebeat.yml,这个是filebeat执行的时候才用的配置。只需要修改他就行!
这是
其中的开头几行,paths指明你要把本机的哪个目录的日志分享出去。
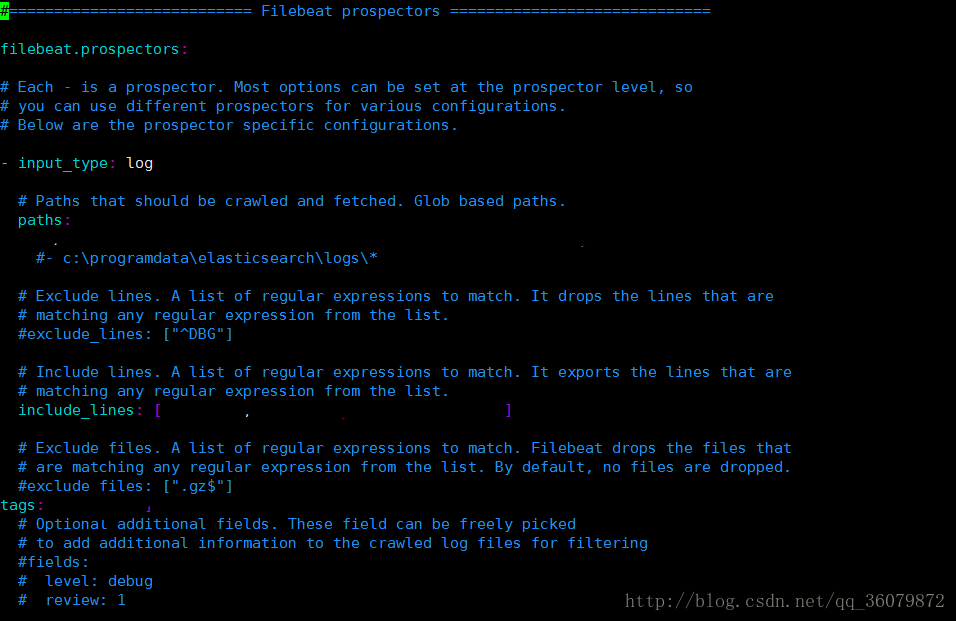
其中include_lines表明,从filebeat输出的日志中要包含的内容,可以用通配符表示 ,比如 include_lines:[“.*key.*]表示从filebeat收集的日志的行一定要包含key,不包含key的不要。当然也有exclude_lines,是排除掉的日志。
在官方文档了解到tags的用法,如果加了tags字段,表明,filebeat输出的日志中将要加一个tags域,比如tags: [“log”],那么filebeat输出的日志中会新加入一个特征tags(也就是列),值为log。加入tags的目的是为了后续logstash对其进行筛选,很关键的操作。
之后最重要的就是下面的output部分。filebeat 5.4支持向kafka,logstash,es输出数据。(注意:刚开始进入filebeat.yml的时候里面并没有output.kafka,是后加的,当时很惶恐啊。不知道可不可以,试了之后发现可以),其实们可以看和filebeat.yml同目录下的filebeat.full.yml,这个是filebeat支持的所有操作,只不过都是注释的而已,供我们参考,filebeat运行还是使用filebeat.yml配置。
我们可以把原来的output.elasticsearch注释掉,之后再加上output.kafka。如下图所示:

enabled表明这个模块是启动的。host: 是想把filebeat传入到哪台机器的kafka上,比如 一个具体的ip + 9092(kafka默认端口号)。
topic这里很关键,表明我们想发送给kafka的哪个topic,若发送的topic不存在,则会自动创建此topic!!!!
其他选项默认就好。不用改。
这样filebeat就配置好了。
3.配置服务器端
这篇文章,我只在一台机器上配置elasticsearch,logstash 和kibana,在公司刚开始应用ELK时,就是这么配置的,只在一台机器上运行这3个,这是可以用的。
3.1安装kafka(后续添加)
3.2安装与配置logstash
在官方网站下载logstash linux 64位的,
。然后解压 tar -xzvf logstash-5.4.0.tar.gz
会有如下目录:
(里面的start.sh脚本是额外写的,原本没有)
我们暂时无须配置config里面的logstash.yml,暂时用不到,如上图所示,我们创建一个test_conf,名字可以随意起,是因为logstash启动必须用命令行参数指明需要使用的配置文件,比如此图中我们使用
bin/logstash -f test_conf,这样表明logstash用tesh_conf配置启动。那么如何配置test_conf呢?如下图所示

input
插件中有kafka,表示logstash 用kafka的输出来作为输入。其中各项属性请参考官方文档,很容易理解。
filter 是过滤,其中grok插件也是一门学问,需要多多查看资料。
output可以指定logstash的输出去向,我们是让logstash输出到elasticsearch。具体配置请见官方文档。其实output这里index 和 document_type的理解很关键,建议去官方文档看看。
3.2安装配置elasticsearch
在官方网站下载5.4版本的elasticsearch,解压可得到如下的目录结构:

只需要配置config中的elasticsearch.yml。
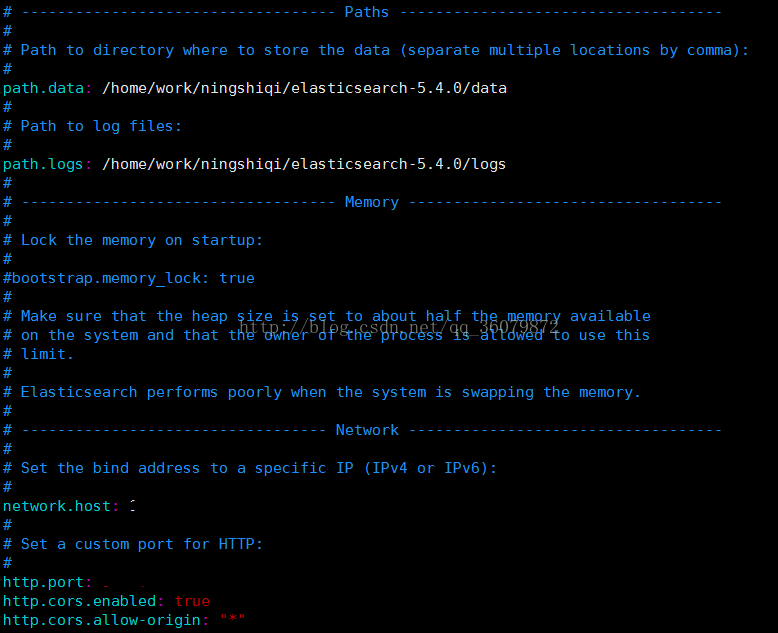
network.host是我们安装的这台机器的ip.
http.port 是我们想要elasticsearch运行的端口。默认是9200,可以自行改变。
后两项是为了使用elasticsearch的插件所设置的。常用的是head插件,head可以在前端展示elasticsearch的存储情况。
这样elasticsearch设计就完成了,很简单。
3.3安装配置kibana
在官网下载kibana5.4,解压,然后在config目录下配置kibana.yml。
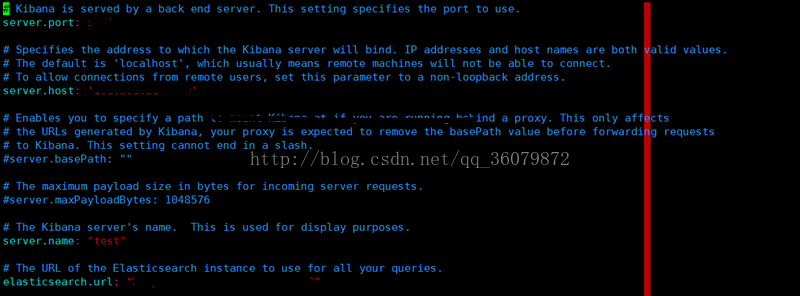
server.host 是kibana运行机器的ip
elasticsearch.url 是elasticsearch所在的ip+端口。
配置完成。