目录
段错误Segmentation fault (core dumped):
空白符:
空格,制表符–‘\t’,换行符统称空白符
注意不要把空格和制表符混淆,两个不是同一个东西
面向对象和面向过程:
面向过程:为了实现某个目标 设计者需要自己一步一步的去完成,面向过程适合于小型项目的运用
面向对象:为了实现某个目标,设计者可以把这个目标划分为多个模块,然后设计一个或者多个对象去完成每一个对象自己的功能模块,以完成目标,面向对象适合于大型项目的实现
对象=数据+函数
注意区分变量和对象
分文件编程:
头文件:包含函数,类及数据成员声明,结构体的数据成员声明。
源文件:源文件要包含头文件,用来定义头文件中声明的东西(使用::)。
源文件包含的头文件,头文件可以不用包含。
但是头文件需要用到的一些命名空间(例如:std),头文件也需要直接引入
分文件编程如果找不到实现文件,就所有源文件一起编译
报错:
undefined reference to `animal::~animal()’
g++ student.cpp animal.cpp -o student.out
头文件和源文件的关系:
预处理:处理预编译语句,进行替换。
编译:按文件编译,生成目标文件,先将高级代码编译成汇编代码
汇编:再将汇编代码编译成目标机器的机器语言。
链接:将所有目标文件链接起来,生成可执行文件。
所有需要编译的文件,编译时都要加入,要不然找不到,就会报错:
当源文件不完整时:
g++ http_main.cpp -l pthread
报错:
undefined reference to `http_conn::process()’
collect2: error: ld returned 1 exit status
加入所有源文件:
g++ http_main.cpp http_web.cpp -l pthread
编译成功
头文件如果被源文件包含,头文件中的
数据(变量和函数)
就可以在源文件中被使用,而不用再定义。
再定义也可以,不会是重复定义
如果源文件和头文件有重复数据,编译器以源文件为主
头文件可以之间包含猿文件要使用的头文件,源文件就不用再包含这些头文件了
关键字:
extern:
extern—额外的
头文件已经可以引用其他文件的变量和函数了,为什么还要extern
对变量而言,如果你想在本源文件(例如文件名A)中使用另一个源文件(例如文件名B)的
全局变量
,方法有2种:
(1)在A文件中必须用extern声明在B文件中定义的变量(当然是全局变量),
而不用包含头文件
;
extern int a; //
声明
一个全局变量 a,a在别的文件中定义
extern int a =0 ; //
定义
一个全局变量 a 并给初值。
int a; // 定义一个全局变量 a
int a =0; // 定义一个全局变量 a, 并给初值,
(2)
在A文件中添加B文件对应的头文件
,当然这个头文件包含B文件中的变量声明,也即在这个头文件中必须用extern声明该变量,否则,该变量又被定义一次。
对函数而言,如果你想在本源文件(例如文件名A)中使用另一个源文件(例如文件名B)的函数,方法有2种:(1)在A文件中用extern声明在B文件中定义的函数(其实,也可省略extern,只需在A文件中出现B文件定义函数原型即可);(2)在A文件中添加B文件对应的头文件,当然这个头文件包含B文件中的函数原型,在头文件中函数可以不用加extern。
extern可以置于
变量或函数前
,以标识变量或者函数的定义在别的文件中,提示编译器遇到此变量和函数时在其他模块中寻找定义。(在此声明,别处定义)
extern的作用:
1,作用:在不同文件之间使用同一变量
定义变量的文件不加extern,用的文件才加
默认c/c++语言下,全局变量前隐藏了关键字extern
extern int a;
在文件中定义变量时在变量类型前加extern是为了告诉编译器,其他文件中有一个变量a,链接时在其他文件中寻找
2,当它与”C”一起连用时,如: extern “C” void fun(int a, int b);则告诉编译器在编译fun这个函数名时按着C的规则去翻译相应的函数名而不是C++的,C++的规则在翻译这个函数名时会把fun这个名字变得面目全非,可能是fun@aBc_int_int#%$也可能是别的,
声明函数的形式:
extern bool addfd(int epollfd,int fd,bool judge);
explicit:—转换操作符
C++类中
只有一个参数的构造函数
默认是可以进行隐式类型转换的
两种特殊情况:
class stu{…};
1)stu s1=10;
因为C++类中
只有一个参数的构造函数默认是可以进行隐式类型转换的
,所以编译器会将整型10转为stu类,再10赋给构造函数,相当于 stu s1(10);
2)stu s1=’a’;
这里可以使用字符a 的ASCALL码值,原理和上面一样
作用就是防止这种只有一个参数的构造函数发生不必要的隐式类型转换
explicit关键字只能用于类内部只有一个参数的构造函数声明上,而不能用在类外部的函数定义
一般只将
有单个参数的构造函数
声明为explicit,而拷贝构造函数不要声明为explicit。
explicit关键字只能对用户自己定义的对象起作用,不对默认构造函数起作用。此关键只能够修饰构造函数。无参数的构造函数和多参数的构造函数总是显示调用,这种情况在构造函数前加explicit无意义。
当不希望进行自动类型转换时用explicit,标准库的许多构造函数都是explicit的。
数据类型:
| 类型 | 所占字节数 | |||
| int | 4 | |||
注意:
int数据和char数据互转时,是利用ASCLL码进行的转换,不是将将这个数据直接转换
eg:
int n=100;
char p=(char)n
p=d //因为d的ASCLL码就是100,
而不是将100字符串
标识符:
宏:
__FILE__ 这个宏的值是当前文件名
__LINE__ 这个宏的值是当前本行代码在这个文件中的行数位置
__func__ 这个宏的值是当前代码所在的函数名
注意:是双下划线
转义字符:
windows下的点一下回车,效果是:回车换行,就是\r\n
unix系统下的回车一下就是一个\n
\n:
换行
\r:
回车,跳到本行行首,如果继续输出,那么之前的内容会被覆盖。
\n\r:
先换行,再移到所在行的行首
\r\n:
先移到所在行的行首,在换行,注意,不会带动文本换行,不像我们编辑文档时换行带动文本一起换行
注意:不要把字符串中的转义字符和从一个文件读取的字符序列的转义字符想象为相同作用。
eg:
char* p=”udfbdhfbjdbk\n”;
file.c中有一下内容:
fgiufidfvbidui\n
在p所指的字符串中’\n’是换行符,但是file.c中的\和n是两个字符,在Linux中只有我们输完一行,按下回车时,操作系统才会在本行结尾加上’\n'(读取时可以读取到);Windows中按下回车是’\r’加上’\n’。
自增,自减
注意以下形式:
i++=5;//是i等于5之后再加一,再看:
*point++=’\0′;//是先将point所指地址内容设置为’\0’,然后point指针再加一。
运算符优先级:
高—-低:暗算关羽或伏
!–>算术运算符–>关系运算符–>&–>|–>=
算术运算符:
怎么把一个数一位一位的取出来:
eg:789;
除运算取商:/
取余运算取余数:%
789/100=7,789%100=89
89/10=8,89%10=9
位运算符
位运算符作用的对象是整数,并且把整数看作二进制数进行操作
左移和右移:
这里只解释操作对象是无符号的数据
原理:以字节所占位数位框框,进行左移或者右移,空出来的位置补0,溢出框框的不要
eg:int 是4个字节,32位,所以有32个框框
int a=0;
int b=a<<1;其他的看:《C++primer》
作用域运算符(::):
作用:
1,类作用域—————类的类型
::
类成员
2,命名空间作用域——命名空间类型
::对象
3,全局作用域运算符—
::对象名
::之前没有对象是什么意思:
表示调用全局变量或者函数
用途:
如果你在局部中含有与全局同名的变量或者函数,就可以利用全局运算符指定全局的,那么没有被指定的编译器就默认为局部的
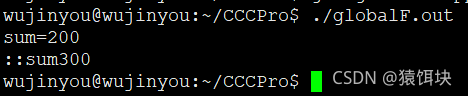
eg:
int sum=100;
void test(int num)
{
int sum=num;
::sum+=sum;
cout<<“sum=”<<sum<<endl<<“::sum”<<::sum<<endl;
}
int main()
{
test(200);
return 0;
}
malloc,new,free,delete:
利用malloc和new开辟的是堆上的内存空间,而一般变量是利用栈上的内存空间
new的形式:
int* p=new int(3);//这是开辟一个int大小的空间,并指定这个空间的值为3
int* p=new int[3];//开辟3个int类型大小的指针,开辟具有3个元素的数组
用new开辟一个类对象空间:
和利用类的类型建立一个类对象一样,在利用new开辟一个类对象的空间时,在开辟的过程中会调用到类的构造函数,所以需要给类的构造函数传递参数。
student* stu=new student(22,"bbay");
用new开辟一个结构体类型大小的空间,并赋值:
student *stlist = new student[3]{{"abc", 90}, {"bac", 78}, {"ccd", 93}};
偏移地址:
就是内存分段之后,这一段内存中的某一段内存相对于这段内存起始地址的偏移量是多少
函数
函数有声明之后一定要有定义,如果只有声明,没有定义,就报错:
ld returned 1 exit status
函数只要有了声明,无论声明或者定义是声明顺序,调用都不会有错误
方法和函数的区别
函数是单独存在的代码块,可以直接调用
方法是对象的属性,通过对象来调用
数组:
千万千万注意了:
只有变量才可以赋值,数组名不是变量,不可以给数组名赋值
char w_buf[BUFFER]={‘\0’};
char r_buf[1024];
……
w_buf=r_buf;
不可以给数组名,但是从数组名复制值:
char buf[100]=”hcbasdjbcdfviefc”;
char* p=NULL;
p=buf;
printf(“%s\n”,p);
C/C++枚举类型:
不限定作用域的枚举类型
关键字:enum
声明枚举类型,然后可以用枚举类型来定义变量(如同结构体):
enum Color{white,black,yellow};
{注意分号}
Color color_type;
color_type 变量的值只限于枚举类型Color中的值
枚举类型中的元素称为:枚举元素或者枚举常量
也可以不用声明枚举类型名,直接定义枚举变量:
enum{white,black,yellow}color_type;
注意
1枚举常量是常量,不能在枚举常量列表之外的地方对枚举类型中的枚举常量赋值。
2:每一个枚举常量都代表一个整数,如果声明时没有给枚举常量赋值,则默认从0开始,往后逐渐加1。如果某个元素被指定值,往后的又逐渐加1.
eg:
enum num{n1,n2=4,n3,n4,n5=10,n6};
则:n1=0,n3=5,n4=6,n6=11 。
3:枚举元素不要重复,重复就没有意义了。
4,枚举类型如果在头文件的类中定义,在源文件作为函数返回类型时,必须用作用域运算符指定,否则就是未定义。
5,可以定义枚举类型的变量,也可以用枚举元素给变量赋值。(HTTP请求方法获取)
枚举和switch
枚举虽然可以用在switch中,语法不会保错,但是因为枚举变量的值都是枚举类型,所以switch中的所有枚举选项尽管值不相等,但是类型相同,都会比较成功而被执行。
所以同一个枚举常量的值放在一个switch中比较毫无意义

限定作用域的枚举类型
enum class/struct{};
作用:
1,限定作用域,防止命令冲突;
2,防止隐式类型转换;
共用体(union):
共用:
共用体成员共同享用共同享用同一段内存,所以对共用体对象的引用要求是,同一时刻,只能引用共用体对象的一个成员。
1,共用体所占内存长度等于所占内存最长成员的内存长度
2,可以对共用体进行初始化,但是只能初始化一个成员的值
对共用体最重要的就是:
任意时刻,单一使用
结构体:
结构体类型和结构体变量
结构体类型:
struct 类型名{};
结构体变量是一个变量,加在{}之后的是此结构体类型的变量
有一种情况,将{}之后的字母定义为此结构体类型的数据,就是用typedef:
typedef struct
{
int a;
} num;
int main()
{
num* p=(num*)malloc(sizeof(num));
cin>>p->a;
cout<<p->a;
return 0;
}
num在这里就不是一个变量,而是代表结构体类型
struct stat:
主要在HTTP中使用。
struct stat
{
dev_t st_dev; /* ID of device containing file -文件所在设备的ID*/
ino_t st_ino; /* inode number -inode节点号*/
mode_t st_mode; /* 目标对应的类型模式,文件或者目录等*/
nlink_t st_nlink; /* number of hard links -链向此文件的连接数(硬连接)*/
uid_t st_uid; /* user ID of owner -user id*/
gid_t st_gid; /* group ID of owner – group id*/
dev_t st_rdev; /* device ID (if special file) -设备号,针对设备文件*/
off_t st_size; /* total size, in bytes -文件大小,字节为单位*/
blksize_t st_blksize; /* blocksize for filesystem I/O -系统块的大小*/
blkcnt_t st_blocks; /* number of blocks allocated -文件所占块数*/
time_t st_atime; /* time of last access -最近存取时间*/
time_t st_mtime; /* time of last modification -最近修改时间*/
time_t st_ctime; /* time of last status change – */
};
在POSIX中定义了检查这些目标对象类型的宏定义:
S_ISLNK (st_mode) 判断是否为符号连接
S_ISREG (st_mode) 是否为一般文件
S_ISDIR (st_mode) 是否为目录
S_ISCHR (st_mode) 是否为字符装置文件
S_ISBLK (s3e) 是否为先进先出
S_ISSOCK (st_mode) 是否为socket
对应的使用函数:
int stat(const char *filepath, struct stat *buf)
获取filepath指定文件信息,存放在struct stat指针对象中。
链表:
链表有一个头指针变量,指向链表的第一个元素,
类:
类的成员函数:
类的成员函数在类内定义和在类外定义的区别:
调用一个函数的时间开销远远大于小规模函数体中全部语句的执时间。为了减少时间开销,如果
在类体中定义的成员函数
中
不包括循环等控制结构
,c++系统会自动地对它们作为内置(inline)函数来处理。也就是说在程序调用这些函数时,并不是真正地执行函数的调用过程,而是把函数代嵌入程序的调用点。这样可以大大减少调用成员函数的时间开销
应该注意的是:如果成员函数不在类体内定义,而在类体外定义,系统并不把它期为内置函数,调用这些成员函数的过程和调用一般函数的过程是相同的。如果想将这些成员函数指定为内置函数,应当用inline作显式声明
值得注意的是:如果在类体外定义inline函数,则必须将类和成员函数的定义都放在同一个头文件中(或者写在同一个源文件中),否则编译时无法进行置换
只有在类外定义的成员函数规模很小而调用频率较高时,才指定为内置函数
成员函数不占用存储空间
不论成员函数在类内定义还是在类外定义,成员函数的代码段的存储方式是相同的,都不占用对象的存储空间。不要误以为在类内定义的成员函数的代码段占用对象的存储空间,而在类外定义的成员函数的代码段不占用对象的存储空间。
类成员的访问;
1,用成员运算符(点).
2,用指向类或者类对象的指针
3,引用
4,在没有建立类对象时,用作用域运算符,可以直接访问
类是一种数据类型:
类和结构体都是数据类型,不占存储空间,只有实体对象才占用存储空间
构造函数和析构函数:
构造函数的作用:
实现数据成员初始化
构造函数什么时候调用:
建立类对象时
构造函数能调用吗:
不能
构造函数重载(构造函数种类):
用户定义有什么构造函数就只有什么构造函数,不会有默认构造函数,定义了什么构造函数,建立对象时就要有什么样的初始值,除非有多个构造函数
默认构造函数:
就是无参构造函数,用户不定义构造函数时,C++系统自动生成
空(默认)
构造函数
复制构造函数:
转换构造函数:
实质,利用一个对象或者标准数据类型给当前对象赋值
eg:
class A;
A a1(3),a2;
a2=A(4);//建立一个无名对象,并初始化为其成员变量为4,然后把这个无名对象赋给a2
转换构造函数只能有一个参数
可能用到:
Teacher(student& s)
{
strcmp(name,s.name);
age=s.age;
}
私有构造函数
将构造函数定义为私有,就不能建立类对象了,而是要通过new建立一个类的指针对象,因为new会调用构造函数,所以new的时候传递参数给构造函数就可以了。
构造函数的默认参数
1,构造函数有默认参数,可以不用传参
2,构造函数有默认参数,在类外定义时,只需写参数名,而不需要再指定默认参数值
类型转换(返回)函数:
形式:
operator 要返回的类型()
{}
注意:operator前无返回类型,返回类型紧跟()前。
类型转换函数只能作为类成员,不能作为友元函数或者普通函数
和转换构造函数相反,类型转换函数是在类中定义一个函数,用来返回一个指定类型的数据,为什么要返回一个指定类型数据;
class A;
A a;
int n=10;
int b;
b=n+a;//b=a+n;
编译器首先会先寻找有没有重载函数,如果没有匹配的重载函数,再到类中中寻找一个返回int类型数据的函数,如果有就执行类型返回函数返回一个int数据和n相加,如果都没有就报错。
class add{};
int main()
{
add num1;
cin>>num1;
cout<<num1;
int h=10,f;
f=h+num1;
cout<<f<<endl;
f=num1+20;
cout<<f<<endl;
return 0;
}
利用类型转换函数可以实现类和普通函数相加
析构函数的作用:
对类中的数据进行清理
析构函数的特点:
三无:无返回值,无类型,无参数
不能重载
析构函数什么时候执行:
析构函数存在的周期如同局部变量:
(1)如果在
全局
范围中定义对象(即在所有函数之外定义的对象),那么它的的构造函数在本文件模块中的所有函数(包括main函数)执行之前调用(全局变量,对象最先建立)。但如果一个程序多个文件,而在不同的文件中都定义了全局对象,则这些对象的构造函数的执行顺序是不确定的,当main函数执行完毕或调用exit函数时(
此时程序终止),调用析构函数。
(2)如果定义的是
局部
自动对象(例如在函数中定义对象),则在建立对象时调用其构造函数。如果对象所在的函数被多次调用,则在每次建立对象时都要调用构造函数。
函数调用结束、对象释放时,先调用析构函数。
3)如果在函数中定义
静态(static )局部对象
,则只在程序第1次调用此函数>1用构造函数一次,在调用函数结束时对象并不释放,因此也不调用析构函数。
main函数结束或调用exit结束程序时,才调用析构函数
this指针
本质:是一个指针,是和对象同类型的指针,指向对象的起始地址
在每一个成员函数中都包含一个特殊的指针,是
指向本类对象
的指针,它的值是当前被调用的成员函数所在的对象的
起始地址,在函数中可以用this指针代表当前对象来使用(除了静态成员函数,静态成员没有this指针)
对this指针解引用就是当前对象:(*this).name
this指针的类型:this指针指向的对象是什么类,this指针就是什么类型
类对象的初始化方式:
class stu{…};
1,使用构造函数 stu s1();
2,对于只有单个参数的类的构造函数,有两种特殊情况可以初始化:
1)stu s1=10;
因为C++类中
只有一个参数的构造函数默认是可以进行隐式类型转换的
,所以编译器会将整型10转为stu类,再10赋给构造函数,相当于 stu s1(10);
2)stu s1=’a’;
这里可以使用字符a 的ASCALL码值,原理和上面一样
防止这种情况的出现可以在此只有一个参数的构造函数之前加
explicit
3,同类之间可以赋值
常成员对象
常对象:
将类对象声明为常量
特点:1,长对象必须要有初始值 2,常对象中的数据成员都不能被改变
person const p1(“lili”,20);
常量数据成员:
只能通过构造函数的
参数初始化表
对常数据成员初始化,任何其他函数都不能对常数据成员赋值
如果有常数据成员,就没有默认构造函数,就必须有参数初始化列表,因为,必须利用初始化列表对常数据成员初始化。
常成员函数:
如果将成员函数声明为常成员函数(const放在小括号之后),则只能引用本类中的数据成员,而不能修改它们
c++面向对象程序设计中,经常用
常指针
和
常引用
作函数参数。这样数据不能被随意修改
类对象之间的赋值:
类和结构体都可以在同类之间进行赋值
对象的复制(克隆):
类名 对象1(对象2)—调用拷贝构造函数

类的赋值和复制都会达到相同的目的,只是,赋值给旧对象的叫做赋值,赋值给新对象的同时创建新对象叫克隆
类的静态数据成员
首先要明白类的对象在建立时发生了什么:
类的对象在建立时进行了类的数据成员的拷贝,每一个对象都有自己的数据成员,但是并不是拷贝类的所有数据,成员函数,静态成员函数和静态成员变量就
是共享的,不拷贝的
。
被static修饰的类的数据成员(函数和变量),表明该数据成员对该类所有对象都只有一个实例。即该数据成员归所有对象共同享用。
1:类的静态成员函数是属于整个类而非类的对象,所以它
没有this指针
,这就导致 了它
仅能访问类的静态数据和静态成员函数。
2:不能将静态成员函数定义为虚函数。(
静态非虚
)
3:静态成员初始化与一般数据成员初始化不同:
初始化在类外进行,而前面不加static
。
如果要在类内初始化,要为静态成员变量提供const或者constexpr修饰,并且初始值必须是常量表达式。(静态成员函数不能声明为const,也就是不能在函数之后加const)
初始化时不加该成员的访问权限控制符private,public等;
4:
默认初始化为0
:在静态数据区,内存中所有的字节默认值都是0x00,某些时候这一特点可以减少程序员的工作量( 全局变量也具备这一属性,因为全局变量也存储在静态数据区 )
5:可以通过类的对象,引用和指针来访问类的静态成员,也可以直接用类名和作用域运算符来访问静态成员
person::allPerson();
//p2.display();
继承和派生:
继承的是父类的特性,派生的是具有父类特性的子类
单重继承:一个派生类继承一个基类
多重继承:一个派生类继承于多个基类
派生类把基类全部的成员(
不包括构造函数和析构函数
)接收过来,也就是说是没有选择的,不能选择接收其中一部分成员
三种继承方式:
共有继承:
私有继承:
外部和派生类虽然不能直接访问基类的私有成员,但是可以通过基类的共有成员函数访问间接地访问私有成员。
保护继承:
保护权限:(protected)
不可以被外界访问,但是可以被派生类访问
直接派生:直接继承 B从A继承
间接派生:间接继承 B从A继承,C从B继承
派生类数据成员和基类数据成员重复情况:
可以在派生类中声明一个与基类成员同名的成员,则派生类中的新成员会
覆盖
基类的同名成员 但应注意:如果是成员函数,不要求函数名相同,而且函数的参数表(参数的个数和类型)也应相同,如果不相同,就成重载函数了
如何访问基类被覆盖的数据成员:
使用同名数据成员时,用作用域运算符指明所属对象即可
派生类:A 基类:B
A,B中都有display()
访问B中的display()
同过A的对象:a
a.B::dsiplay();//A 的对象a的基类B的display()函数
继承的数据成员如何使用:
继承的就是自己有的,可以和一般成员一样使用
继承后端访问属性:
基类的成员函数只能访问基类的数据成员
基类的构造函数的初始化:
派生类的参数化列表直接调用基类构造函数
住:定义的时候才有初始化,才写参数初始化列表,声明的时候没有初始化,不用写参数初始化列表,也不要调用基类构造函数
基类和派生类构造函数和析构函数执行的先后顺序:
先执行基类的构造函数,再执行派生类的构造函数
先执行派生类的析构函数,再执行基类的析构函数
类中的数据成员是一个类:
数据成员称为子对象
子对象的初始化,即构造函数调用如同基类,在初始化参数列表初始化
执行派生类构造函数的顺序是:
(1)调用基类构造函数,对基类数据成员初始化;
(2)调用对象构造函数,对子对象数据成员初始化;
(3)再执行派生类构造函数本身,对派生类数据成员初始化。
基类—>子对象—>本身
析构函数相反
多层派生的构造函数:
子需要调用直接基类进行初始化即可
构造函数执行顺序:
先从此进入到最基层,从最基层开始执行构造函数
析构函数相反
如果子对象和基类无构造函数,或者构造函数无参,可以不用初始化
基类和子对象构造函数重载:
如果在基类中既定义
无参的构造函数
,又定义了有参的构造函数(构造函数重载),则在定义派生类构造函数时,既可以包含基类构造函数及其参数,也可以不包含基类构造函数(在调用派生类构造函数时,根据构造函数的内容决定调用基类的有参的构造函数还是无参的构造函数》编程者可以根据派生类的需要决定采用哪一种方式。(
可有可无
)
同时继承多个基类:
class student:public person,private student1,protected animala{};
派生类构造函数名(总参数表) :基类1构造函数(参数表),基类2构造函数(参数表),基类3构造函数(参数表列)
{派生类中新增数成员据成员初始化语句}
构造函数执行顺序按照声明派生类时继承的顺序执行:
person—>student1—>animal
虚基类
为什么需要虚基类:
当中间基类继承于同一个基类,而这些中间基类派生的派生类就会产生多份相同的基类数据成员
虚基类的功能是声明一个基类为虚基类,则它的多个派生类的公共派生类就只会保留这个虚基类的一份数据成员
每一个中间基类都需要把原始基类声明为虚基类,没有声明虚基类的那份数据依然会被保存,因为虚基类在哪个类声明,就只对哪个类有用
class A;
class B:virtual public A,
class C:virtual public A
派生类对直接虚基类和原始基类的初始化:
如果如同之前多重继承,派生类只需要对虚直接基类初始化,直接虚基类再去初始化自己的基类,那么多个虚基类都对原始基类初始化,则会产生矛盾。所以:
对于虚基类的继承方式,所有基类都由派生类用初始化列表初始化。
当然,对于单一线性继承的没必要
C++系统只执行最后一次对原始基类的初始化,中间基类对原始基类的初始化不会被执行。
但是中间基类构造函数有多少参数,还是要传多少参数
派生类给基类赋值:
赋值只是对数据成员,对成员函数不存在赋值
赋值的过程都是将派生类从基类继承来的数据成员的值赋给基类对应的数据成员
基类不可以向派生类赋值
1,派生类对象向基类对象赋值:
2,派生类对象给基类引用对象赋值:
引用不是整个派生类对象内存,只是派生类对象中继承于基类部分的 内存的引用
所以引用不可以访问派生类对象自己的数据成员
3,派生类对象给基类指针对象赋值:
和引用同理
4,当函数参数是基类对象或者基类对象的引用或者指针时,实参也可以用派生类
性值属于基类的对象都不能越界访问派生类新增的数据成员和成员函数
如何在一个中调用另一个类的数据成员和函数:
使用
::
(如:在派生类中需要调用基类数据成员和成员函数时)
类的组合
就是一个类中创建另一个类的对象
友元:
友元函数:
为什么要在类内声明友元函数:
将一个函数声明为类的友元函数,就可以利用这个函数的功能操作类中的数据成员
类的公共成员类的外部函数不用声明为友元函数也可以引用,
声明为友元主要是为了能引用类的私有成员
哪些函数可以成为友元函数:
任何不属于类的成员函数,以及类的成员函数都可以成为友元函数
当友元函数是其他类的成员函数时,需要用作用域运算符指明函数所属的类
友元函数没有this指针,即使在类内声明,也不可以直接访问类的成员,要用类对象或者作用域运算符指明
友元函数的访问权限:
可以访问类中的所有成员
友元函数的调用:
友元函数的调用和类无关,对类的访问才和类有关
友元类:
将一个类B声明为另一个类A的友元类,则B中的所有函数都是A的友元函数,都可以访问A的成员数据
类对象数组:
student stu[n];
有n个对象,就会执行n次构造函数
如何给对象数组赋值:
n=1时;
student stu[1]={“name”,12};
n=3时:
student stu[3]={student(“name1”,12),student(“name2”,13),student(“name3”,14)};
参数默认值:
string:
string 是标准库中的一个
类
,string对象
可变长
序列
string对象的初始化:
string s(5,’h’);
则s所代表的内存存放的是:hhhhh,5个h
string的数值转换:
1,其他类型转string:
int n=10;
string s=to_string(n);

注意:to_string只能运用于任何算数类型,而不能用于char

其中要转换为数值的string对象中的第一个字符必须是数字
p,b参数可以不要,只要s.
关于string函数更多请参考
链接
命名空间
命名空间的本质就是开发者根据需要开辟出
一块有名字的内存空间
命名空间——>给空间命名
这快空间的内存就是这个被命名空间的名字
namespace(命名空间),用户可以用namespace关键字定义不同的命名空间,来防止某些函数,类,模板等的冲突(重复)。
命名空间解决的问题:同名冲突
命名空间的命名空间成员可以是声明的形式,也可以是定义的形式
命名空间中的成员是全局成员,只是包含在命名空间中了,使用这些成员时,要使用命名空间限定的形式:ns::a
命名空间成员类型:
变量(可以初始化)
常量
函数
类
结构体
模板
命名空间(命名空间的嵌套)
命名空间的别名:
用来代替较长的命名空间
生成:namespace TV=Televsion;
使用using关键字生命命名空间的成员
在using语句作用范围内使用using声明命名空间的某个成员之后,在这个作用域内使用这个成员都可以不用命名空间限定。
using 关键字一次只能声明一个命名空间成员
using namespace 命名空间;
可以一次声明命名空间的所有成员,但是使用的前提是不能有同名冲突,如果有同名就必须用::指定
命名空间中的成员在本文件可以当作全局变量来使用
无名命名空间只能在本文件使用
命名空间注意事项:
1:命名空间的定义只能写在全局上,不能写在局部范围内
2:命名空间可以嵌套
嵌套命名空间中成员的调用:
3:命名空间可以随时入新成员:
#include “iostream”
namespace A
{
int a;
int b=10;
}
namespace A
{
int c;
}
int main()
{
}
4:命名空间定义后无分号
5:包含了头文件,也要指明头文件中的命名空间,不要一位包含了包含命名空间的头文件就可以
大型程序往往会使用多个独立开发的库,这些库又会定义大量的全局名字,如类、函数和模板等。当应用程序用到多个供应商提供的库时,不可避免地会发生某些名字相互冲突(重复)的情况。多个库将名字放置在全局命名空间中将引发命名空间污染(namespace pollution)。
多态:
一个事物多种形态
采用静态绑定实现的多态就称为静态多态性,是通过函数重载和运算符重载,在编译时通过静态绑定实现的。采用动态联编实现的多态就称为动态多态性,是通过继承和虚函数,在程序执行时通过动态绑定实现的。平常所说的面向对象程序设计的多态性常指运行时的多态性(动态多态性—继承和虚函数)。
静态多态性:就是函数重载,运算符重载
多态多态性:就是继承和虚函数
静态绑定和动态绑定最直接的区别:
静态绑定:通过对项名调用虚函数
动态绑定:通过基类指针调用虚函数
虚函数:
如何让实现同一接口:
定义一个指向基类的指针或者引用(可以将派生类对象赋值给这个指针或者引用)
实现:
将基类中的于派生类”相同”的函数声明为虚函数—-virtual
这样,”相同”的函数在派生类中就不存在了,而被隐藏了,通过接口(指向基类的指针或者引用)不同类中的”相同”函数
在声明时才需要加virtual,定义时,不需要加virtual。
注意虚函数不是函数重载
当中国”相同”函数在基类中被声明为虚函数后,派生类中的“相同”函数都会自动被声明为虚函数,但是最好加上virtual.
虚函数是会被继承的,只是当派生类中有相同函数时,虚函数不被使用。
virtual只能运用在类中声明虚函数,不能用于普通函数
如果把派生类中的”相同“函数声明为虚函数呢:
派生类中的虚函数对基类不会有影响,只对自己的派生类有影响
虚函数如何实现多态性:
对于具有继承关系的同一类族中不同类的对象,对同一函数调用会有不同响应。
(调用同一类族的不同类对象的同名函数,会有不同响应
虚析构函数:
特别的,当动态生成一个指向派生类的基类指针时,如果指针指向的基类之前的所有基类析构函数都是非虚的,那么如果程序执行完毕用delete释放这个指针时,被执行的析构函数就只有指针类型的基类的析构函数,和此基类之前的析构函数,派生类的析构函数将不会被执行。
解决办法是,将基类的析构函数声明为虚析构函数
,一旦基类的析构函数变为虚析构函数,那么所有派生类的析构函数都自动变为虚析构函数
。这样,当基类类的指针变量指向派生类而被释放时,就可以都执行所有类的析构函数了。
构造函数不能声明为虚函数
纯虚函数:
形式:
virtual 函数返回类型 函数名(参数)=0;
或者:virtual 函数返回类型 函数名(参数)const=0;
为了实现多态性,在基类中只声明一个纯虚函数,不定义,留给派生类定义
”=0“是将函数初始化为0,为了告诉编译器这是一个纯虚函数
纯虚函数只有被定义之后才可以被调用
纯虚函数如果在 派生类中没有被定义,那么在派生类依然是纯虚函数
注意:纯虚函数声明时没有函数体
抽象(基)类:
包含纯虚函数的类都是抽象类
抽象类不能建立对象,只能用来派生派生类,都是抽象类可以用来定义指针。
如果派生类把
所有
纯虚函数都定义了,那么这个派生类就不是抽象类,就可以用来定义对象,否则也是抽象类。
因为抽象类是作为公共接口使用,所以,最好定义其成员函数和数据成员权限为public
重载函数:
三要素:函数同名,参数个数相同,参数类型相同
运算符重载:
为什么程序员定义一个运算符的新功能是运算符的重载:
既然是运算符,那就说明运算符已经有实现功能的函数了,程序员再定义就是重载
运算符重载是通过定义运算符的函数实现的,所以
运算符重载也是函数重载
运算符被重载后,其原有功能依然还存在
为什么需要运算符重载(什么时候需要运算符重载函数):
需要对
非标准类型对象
进行运算
当运算符操作的数据类型不是标准类型时
如:类
运算符重载实现形式:
函数返回值类型 operator 运算符名称(形参列表)
{函数体}
函数名由operato和运算符组成
-
complex
complex
::
operator
+(
const
complex
&
A
)
const
{
-
complex B
;
-
B
.
m_real
=
this
->
m_real
+
A
.
m_real
;
-
B
.
m_imag
=
this
->
m_imag
+
A
.
m_imag
;
-
return
B
;
-
}
当执行
c3 = c1 + c2;
语句时,
编译器检测到
+
号左边(
+
号具有左结合性,所以先检测左边
)
C++编译系统会c1+c2解释为:c1.operator+(c2)
c1.是引用自己的成员
opertaor+(c2)就是c1中运算符重载函数,c2是函数的实参
运算符重载规则:
1,C++不允许用户定义新的运算符,只能对已有运算符重载

2,重载运算符函数不能有
默认参数
3,重载运算符的运算对象
必须至少有一个是用户自定义的类型对象
,不能全是标准类型
4,用于类对象的运算的运算符一般必须重载,两个除外:=,&
=:同一类型类对象可以相互赋值
&:地址运算符
5,当运算符是类的成员函数时,因为+是左结合性,左边的运算对象必须是非标准类型,否则无法调用重载函数。如果左边是标准类型可以让重载函数成为友元函数,而不是成员函数
6,重载不改变运算符的结合性,优先级,运算对象的个数
7,友元函数中实参和形参必须一 一对应:
friend complex operator+(int& i,complex& c){}
c3=1+c2;//right
c3=c2+1;//error
8,只能作为成员函数的运算符:=,[ ]–>下标运算符,(),->成员运算符,单目运算符,复合运算符。
单目运算符:!a,&a,++a,a–等等
复合运算符:<=,>=,==,!=等等
只能作为友元函数:<<,>>,双目运算符
运算符作为类成员函数和友元函数的区别:
1,作为成员函数,其中一个运算对象就是引用对象,参数会比友元函数少一个
2,作为友元函数,运算对象都需要作为参数传入
重载运算符作为友元如何引用:
和作为类成员函数一样引用
编译器检测到运算对象不是标准类型会自动去寻找重载函数
注意:运算符重载并不是说一定要用这个运算符进行运算,而只是用这个运算符重载一个函数来完成一定的功能
运算符重载函数的调用:
和普通函数一样:函数名(实参列表)
if(operator>(s1,s2))
cout<<s1.display()<<” > “<<s2.display()<<endl;
单目运算符重载:
自增,自减运算符重载:
class A;
怎么区分是前置自增(++a)还是后置自增(a++)
前置:重载函数形参列表要么为空,要么就和实参数目一样
后置:要求后置重载函数形参不能为空,无实参则至少也要有一个int型参数,有实参则添加实参个数:
自减一样
1:
Time operator++()//前置
Time operator++(int)//后置
2:
void operator++(num& n1)//前置
{
++n1.n;
}
void operator++(num& n1,int)//后置
{
n1.n++;
n1.n++;
}
<<和>>运算符重载:
只能将<<和>>运算符重载函数作为友元函数,不能作为成员函数
形式:
class A;
A a;
>>:
istream& operator>>(istream& input,A& b){}
<<:
ostream& operator<<(ostream& ouput,A& b){}
input,output,b都是形参
这两个运算符的重载函数的返回类型和第一个参数,必须是istream&或者ostream&,第二个参数是类对象的引用
为何:
看:cout<<a1<<a2<<endl;
首先执行cout<<a1,cout<<a1执行完之后需要返回一个cout才能继续输出cout<<a2,同理,才能输出cout<<endl;
返回是为了继续执行
eg:cout<<a
cout是ostream类的对象,是第一个参数
cin,cout:
C++编译系统在类库中都会有输入流类istream和输出流类ostream,
cin是istream类的对象,cout是ostream类的对象
cin:
可以连续输入不同类型数据:
int a;
char c;
float b;
cin>>a>>b>>c;
可以往指针所指地址输入数据:
printf(“Please input name for the %d person:\n”,i);
cin>>per[i]->name;
ostream的三个对象:cout,cerr,clog
cerr和 clog用来输出语句的错误信息,cerr不经过缓冲区直接输出,clog需要将数据存放在缓冲区,在缓冲区满或者遇到endl之后才输出
eg:cerr<<“I want to fall in love.”<<endl;
clog<<“I want to fall in love.”<<endl;
cout对象有一个成员函数用来输出一个字符:
cout.put(‘a’);
同样cin也有一个成员函数用来读入一个字符:cin.get();
1,int a=cin.get();
2,也可以:cin.get(a);
成功返回非0,失败返回0
getchar(a)
3,cin.get(字符数组名/字符指针,n,终止字符)
读取n-1个字符到数组中,如果读取过程遇到种植字符,就终止读取
eg:char arr[10];
cin.get(arr,10,’a’);
同样:cin.getline(
字符数组名/字符指针,n,终止字符
)
注意:终止字符不被读入
c和c++强制类型转换:
c:
int a=10;
(float)a;
c++:
float(a);
当然c++也可以用c的方式,但是c++中最好用c++类型
流:
流动的字节序列
内存—-》输出设备
输入设备—-》内存
缓冲区:暂存数据
比如从键盘输入,并不是一个一个输入到内存,而是先输入到键盘缓冲区,当按下回车,缓冲区的数据才被发送往内存
cout,cin都有缓冲区,当cout遇到endl,就将缓冲区数据输出到终端
异常处理(try–catch):
对运行时可能出现的错误和其他情况进行处理(比如,输出)
c++异常处理采取的办法:
在父函数将需要检查的程序(子函数的调用)放入try模块,由子函数(使用throw)抛出异常信息,抛出的信息抛到try模块中,当子函数设置的异常条件满足,throw抛出异常,子函数终止,try模块由于子函数异常终止,也终止,因为try异常终止,所以程序会跳到catch语句去捕捉throw抛出的信号,如果捕捉到,就进入catch语句执行对异常的处理。(如果父函数不能处理,可以将异常抛给父函数的父函数,由上一层函数处理,可以逐级上传)。(
子函数抛出,父函数处理
)。(throw,try-catch也可以在一个函数中)
C++异常处理由3部分组成,检查(try),抛出(throw), 捕捉(catch)
try:需要检查的语句放在try中
throw:在子函数中抛出异常到父函数try模块中
catch:捕捉异常并处理
(catch异常处理器/块)
try和catch是一个整体,当try中的语句没有发生异常是,就不会去执行catch中的语句,
只有当try中的语句发生异常,程序才会跳到catch中的语句去捕捉异常并处理。
可以在函数声明和定义时,限定可能抛出的异常类型:
int func() throw (int,double,float);//声明时
int func() throw(int,double,float){
…
}
则表明,抛出的异常只能是,int/double/float。
如果使用这种限定的形式,则函数声明和定义时都必须有异常限定部分:throw(int,double,float)
如果异常限定中throw()为空,则表示不抛出任何异常信息。
如果抛出了,程序将终止。
(构造函数不能返回,所以可以利用throw抛出,让构造函数程序终止)
注意:
1,try和catch是一个整体,catch不能单独使用,try可以单独使用。
2,try和catch中间不能插入其他语句。
eg:
try{
……
}
cout<<“dfcdcdc”<<endl;
catch{
……..
}//error
3,当catch处理完,程序并不会终止,而是继续执行catch之后的语句。
4,try{}—catch{}的花括号不能省略,即使只有一个语句也不能。
5,一个try-catch语句中只能有一个try,但是可以有多个catch,用来捕捉不同类型的信号。
try{…}
catch{…}
catch{…}
catch{…}
…
6,catch只能检查捕捉到的信号的类型,不会检查捕捉到的信号的值。所以catch()括号中一般只写异常信号类型。所以要抛出不同异常信息,需要抛出不同类型数据。
eg:
int a,b,c;
…
throw a;/throw b;/throw c;都是相同的。
7,throw抛出的数据不仅可以是C++预(先)定义的标准类型,还可以是用户自己定义的类型,如类,结构体等。
8,catch语句可以获取捕捉到的数据的一份拷贝:
定义catch为:catch(double a)
那么,当抛出一个double变量b时,就会拷贝b的值给a,就可以在catch模块中使用a变量。
9,catch(…)可以捕捉所有类型的信号,catch(…)应该放在最后,如果放在前面那,那么catch(…)之后的语句就没有用了,根本不会被执行。
9,throw和try-catch可以在同一个函数中,也可以在不同函数中,当throw抛出时,先在本函数找catch模块,如果异常被处理,就不进入父函数,如果本函数的catch没有捕捉throw抛出的信号,程序就转到上层函数寻找符合要求的catch,逐层向上,知道信号被catch捕捉或者整个程序都没有捕捉这个信号的catch,则程序会都调用teminate函数使函数终止。
10,当throw和try-catch在一个函数中时,
11,catch{
throw;
}
程序会把catch捕捉到的信号再抛给上层函数检查和处理。
12,因为抛出是在try中抛出,所以throw可以写在try中;
try{
throw a;
}
catch(){}
13,try-catch,throw可以在父函数,子函数中都有。
14,注意:try的后面没有括号,编程时不要加上括号。
一些细微的编程错误:
段错误Segmentation fault (core dumped):
访问了不该访问的内存,或者修改了不能修改的内存:
1: char* str=”aaaaaaaaaaa”;
2: char str[20]=”aaaaaaaaaaa”;
利用一下程序操作str:
char* str=”uiefcb”;
memcpy(arr,str,6);
printf(“%s\n”,arr);
2没有问题,但是操作1时,就会出现段错误
因为char指针变量str所指向的内存区编译之后只能读,不可以修改,但是数组名str所指向的内存区可以修改。
智能指针
为什么需要智能指针:
因为一般指针使用都是要new/malloc,然后离开作用域前要delete/free,那么你很有可能会忘了delete/free,而导致内存泄露。这时候智能指针就诞生了,通过把指针封装在模板类里面,调用构造函数分配内存,析构函数释放内存,那么只要离开作用域就会自动调用析构函数释放内存,就可以解决你忘了delete/free而导致的内存泄露问题了。
模板类
模板类的成员类外定义:
必须具有的三个要素:
1,类外定义一定要有模板定义的行—template<typename T>
2,同普通类成员的类外定义一样,成员最开始一定要具有类型修饰
3,要有完整类型限定符
一般的类成员类外定义只需要类名作为限定,但是模板类不仅需要类名,还需要模板参数
所以 完整类型限定符=类名<模板参数>
template<tpename T>
class student
{
……
void display();
};
template<typename T>
void student<T>
::
dispaly()
{…}
注意:
1,
模板类建立的对象的类型不是类名,而是类名加上模板参数的完整类型限定符
2,
模板参数所指向的数据成员即使还没定义也不会编译出错。
标准库(std):
std::exception
标准库中的一个类,用于报告标准库函数遇到的问题
,其类的声明在头文件<exception>中。所有标准库的异常类均继承于此类,因此通过引用类型可以捕获所有标准异常。
可以直接调用这个类的构造函数exception()来报告异常的发生,注意只是报告异常发生,但是不给出异常的详细信息。