本菜鸟实践中发现,使用正则表达式 or xpath爬取想要的内容真的是太香了—只需定位到你想爬取的内容及前后内容即可(此处有点绕,下面详细讲解)
以豆瓣读书《恶意》为例(此处心疼豆瓣一秒钟,总是成为菜鸟们练手的第一选择):
图片左侧为评论内容,右侧为检查元素

爬取的内容为第一条评论:作为新手妈咪,在看到最终结局的时候很感慨。凶手体内毒液一般的恶意,也许就是源自当初母亲在生活中流露出来的偏见,应该也算是失败教育的受害者吧。谨记谨记。
(1)正则表达式:从检查元素中可以看到,与评论相连的前面位置元素内容为:

后面位置元素内容为:

以下为正则表达式程序:

“\s”在正则表达式里表示空白符,”.”在正则表达式里匹配换行符以外的任意字符,“星”在正则表达式里表达重复一次或更多次(”.”只会爬取一个字符,通过”星”把 第一条评论内容都爬取下来),(.星)表示只获取()里的内容
结果:

附上完整程序代码:
import re
import requests
def parse_page(url):
headers = {
'User - Agent':'Mozilla / 5.0(Windows NT 6.1;WOW64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 63.0.3239.26Safari / 537.36Core / 1.63.6788.400QQBrowser / 10.3.2714.400'
} #反爬
response = requests.get(url,headers = headers)
text = response.text #文本
comment = re.findall(r'<span\sclass="short">(.*)</span>',text) #评论
print(comment)
def main():
url = 'https://book.douban.com/subject/3646172/comments/hot?p=2'
parse_page(url)
if __name__ == "__main__":
main()
(2)xpath
获取xpath方法有两种:复制 or 手写
方法一:复制
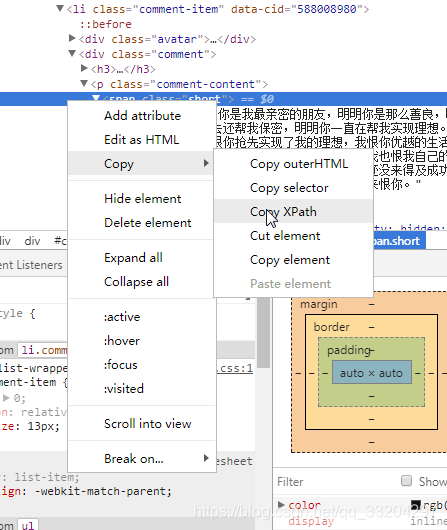
方法二:手写

程序代码:
import requests
from lxml import etree
def parse_page(url):
headers = {
'User - Agent':'Mozilla / 5.0(Windows NT 6.1;WOW64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 63.0.3239.26Safari / 537.36Core / 1.63.6788.400QQBrowser / 10.3.2714.400'
}
response = requests.get(url,headers = headers) #反爬
text = response.text #文本
file = etree.HTML(text)
comment = file.xpath('//div[@class="comment"]/p/span/text()')[0] #解析
print(comment)
def main():
url = 'https://book.douban.com/subject/3646172/comments/hot?p=2'
parse_page(url)
if __name__ == "__main__":
main()
欢迎评论交流
版权声明:本文为qq_33204297原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。