HDFS基本操作
hadoop fs -mkdir /test (/test2) 创建目录(常见多级目录)
Hadoop fs -ls /test 查看列表下所有的文件
hadoop fs -cat /test/1.txt 查看指定文件夹下的内容
Hadoop fs -cat /test/1.txt /test/2.txt 同时查看指定文件夹下的内容
Hadoop fs -cat
file:///test/1.txt
查看本地系统文件
Hadoop fs -put /1.txt /2.txt /input 将本地文件复制到hdfs目录
Hadoop fs -get /input/1.txt /usr 将hdfs目录下的文件复制到本地 put的逆操作
Hadoop fs -mv /input/1.txt /usr/hadoop/ 将文件从原路径移动到指定路径下
Hadoop fs -cp /input/1.txt /usr/hadoop/ 将文件从原路径复制到指定路径下
Hadoop fs -rm /usr/1.txt 删除指定文件,只删除非空目录和文件
Hadoop fs -rmr /usr 递归删除,将文件和文件夹都删除
hadoop fs -test -e /input2/file3.txt
Echo $?
检查是否存在
-e:检查文件是否存在。如果存在则返回0
-z:检查文件是否0字节。如果是则返回0
-d:检查路径是否为目录,如果是则返回1,否则返回0
hadoop fs -du URI [URI …] 显示目录所有文件的大小
开启
hdfs的回收站功能
执行
stop-dfs.sh 关闭hdfs
在
namenode的core-site.xml中配置两个节点属性
1.
<
property>
2.
<name>
fs.trash.interval
</name>
3.
<value>
10080
</value>
4.
<description>
Number of minutes after which the checkpoint gets deleted. If zero, the trash feature is disabled.
</description>
5.
</property>
6.
7.
<property>
8.
<name>
fs.trash.checkpoint.interval
</name>
9.
<value>
0
</value>
10.
<description>
Number of minutes between trash checkpoints. Should be smaller or equal to fs.trash.interval. If zero, the value is set to the value of fs.trash.interval.
</description>
11.
</property>
属性介绍
:
fs.trash.interval:丢进回收站中的文件多久后(准确的说是多少分钟后)会被系统永久删除;这里10080是7天;
fs.trash.checkpoint.interval:前后两次检查点的创建时间间隔(单位也是分钟);新的检查点被创建后,随之旧的检查点就会被系统永久删除;
hadoop fs -expunge 清空回收站
利用
hadoop api 实现对hadoop的文件操作
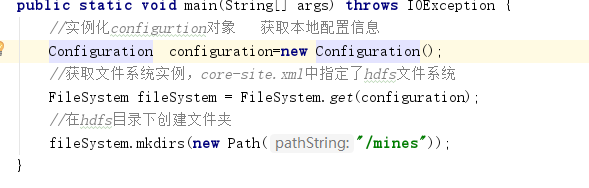
1.
在
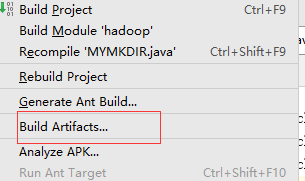
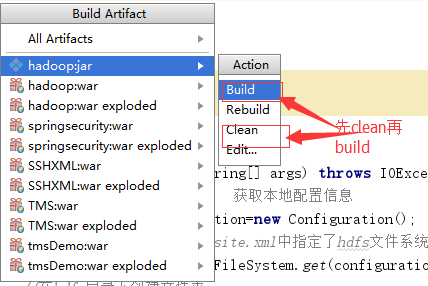
idea中将项目打成jar包
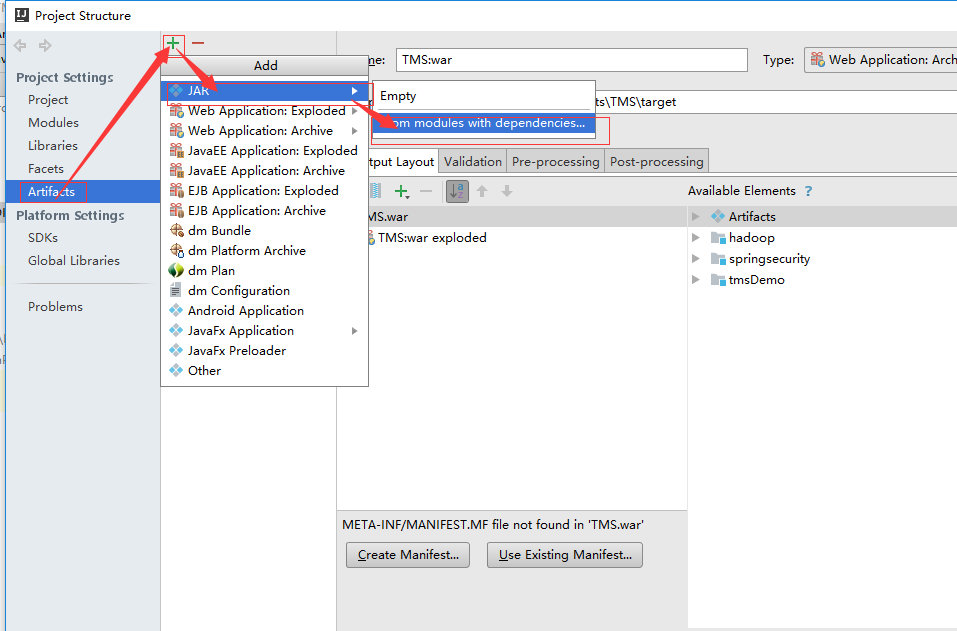
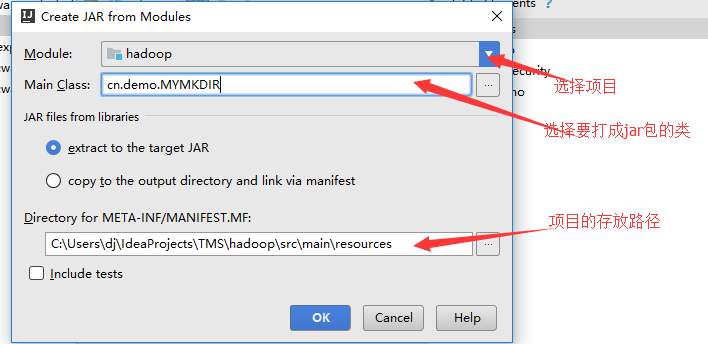
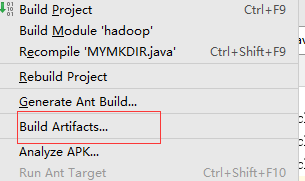
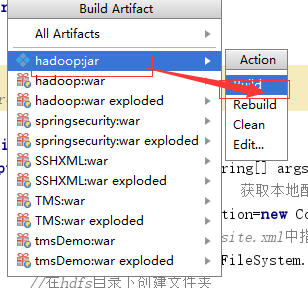
Build,使jar包生成
Jar包在本地存放位置

根据自己位置不定,这只是我的
)
将
jar包通过xftp工具放入指定jar存放目录下(hadoop下都行)
/usr/local/bigData/hadoop-2.8.0/share/hadoop/hdfs(我的目录位置)
切换到
jar包所在位置
运行
jar包
Hadoop jar hadoop.jar cn.demo.mkdir(主类的全名称)
对应的操作将会执行
但是当代码修改之后,你再次打
jar包时会报一个源文件已存在的错,这时只需要