aceback (most recent call last):
File "D:\my_codeworkspace\bishe_new\jiaoben\train_KINN_NonFEM_based_swin_freezebone.py", line 264, in <module>
trainOneParameter(params)
File "D:\my_codeworkspace\bishe_new\jiaoben\train_KINN_NonFEM_based_swin_freezebone.py", line 234, in trainOneParamet
er
train(model_two=model_two_output,optimizer_model_two=optimizer,train_loader=train_loader)
File "D:\my_codeworkspace\bishe_new\jiaoben\train_KINN_NonFEM_based_swin_freezebone.py", line 130, in train
P_I_loss.backward()
File "C:\Users\asus\.conda\envs\pytorch\lib\site-packages\torch\_tensor.py", line 307, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs)
File "C:\Users\asus\.conda\envs\pytorch\lib\site-packages\torch\autograd\__init__.py", line 154, in backward
Variable._execution_engine.run_backward(
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cu
da.DoubleTensor [18, 3]], which is output 0 of AsStridedBackward0, is at version 1; expected version 0 instead. Hint: e
nable anomaly detection to find the operation that failed to compute its gradient, with torch.autograd.set_detect_anoma
ly(True).
这是在这段代码里出现的
def train(model_two, optimizer_model_two, train_loader):
model_two.train() # train model会开放Dropout和BN
# model_stress.train()
for i, data in enumerate(train_loader):
optimizer_model_two.zero_grad() # 用 optimizer 將 model 參數的 gradient 歸零
# optimizer_model_stress.zero_grad()
data = tuple(i.cuda() for i in data) # 内循环
strain, stress = model_two(
(data[0], data[3][:, 0:2, :, :])) # 利用 model 的 forward 函数返回预测结果
# stress = model_stress((data[0], data[3][:, 0:2, :, :]))
# print(data[8].shape)
# print(displacement.shape)
trival_loss = model_two.forward_loss(strain_target=data[2], strain=strain, stress_target=data[1], stress=stress)
# loss2 = model_stress.forward_loss(stress_target=data[1], stress=stress)
# print(displacement)
# print('**********')
# print(loss)
P_I_loss = calculate_P_Iloss(stress_12=stress, strain_12=strain)
# loss = loss1+loss2 + P_I_loss
print('PI {}'.format(P_I_loss))
print('trival {}'.format(trival_loss))
# print(loss)
# loss = trival_loss
trival_loss.backward(retain_graph=True) # tensor(item, grad_fn=<NllLossBackward>)
# print(model_two.blocks.grad) 报错
# print(model_two.transform.grad)
# print_module_grad(model_two.blocks)
# print_module_grad(model_two.transform)
# # P_I_loss.backward()
# activate_module(model_two.blocks)
# activate_module(model_two.transform)
optimizer_model_two.step()
optimizer_model_two.zero_grad()
freeze_module(model_two.blocks)
freeze_module(model_two.transform)
P_I_loss.backward()
optimizer_model_two.step()
optimizer_model_two.zero_grad()
我以为,将不想更新模块参数的require_grad属性设为F后,optimizer就能正常更新我想要的部分的参数。但是事与愿违。我的代码在P_I loss.backward部分就出了错。
我推测报错原因:
根据日志里提到的in-place关键词,可知是in-place操作破坏了计算图,这样我就发现了:
optimizer_model_two.zero_grad()
freeze_module(model_two.blocks)
freeze_module(model_two.transform)
P_I_loss.backward()
optimizer_model_two.step()
optimizer_model_two.zero_grad()
zero_grad包含in_place操作!
因此,每次zero_grad之后都必须再进行前向传播创建计算图才能反向传播即使用backward方法。(跟freeze与否无关)
这个很难绕开,因为我用trival_loss对应的optimizer更新以后,如果不用zero_grad,再使用PI_loss反传,就会造成部分位置的梯度实际值是trival_loss和P_Iloss两次反向传播产生的梯度之和,下一次PI_optimizer反传,造成效果是P_I所管辖的那部分网络参数的trival_loss的梯度被更新了两次。
现在最重要的问题:弄清楚require_grad是在backward阻止梯度还是在optimzer阻止梯度。我推测是在optimizer阶段。
更新:
今天发现更扯淡的事,使得这条路更加困难:
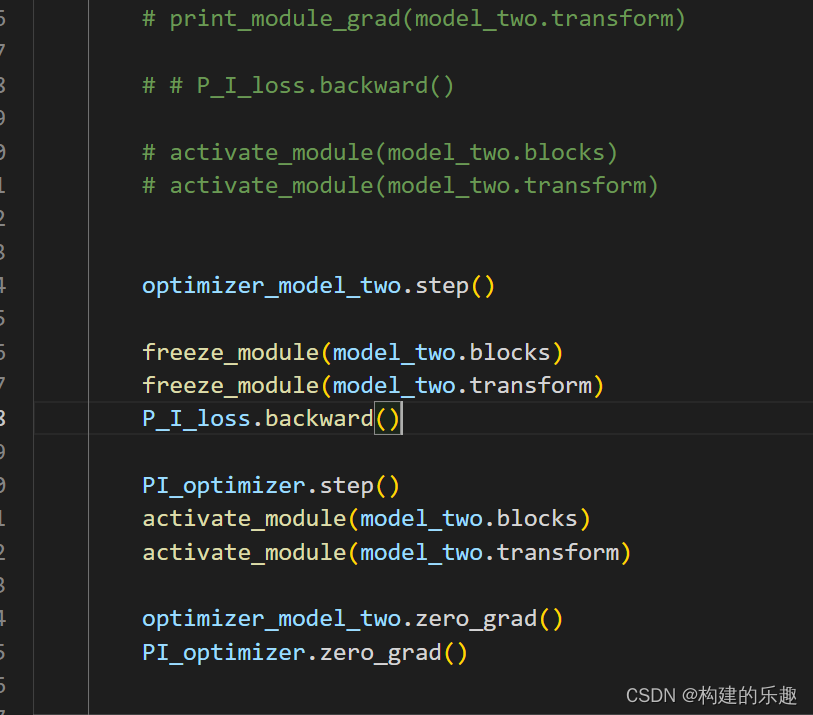
我确定不仅zero_grad包含in-place操作,而且optimizer step操作也包含in-place操作,而且这个才是主要的危害。
版权声明:本文为qq_44065334原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。