一、安装过程
1.安装Docker Engine
arm64
推荐使用官网安装中的
Install from a package
docker官网安装Docker Engine
Docker Engine(arm64版本)的相关deb包下载地址
amd64
- 卸载系统自带的旧版本
sudo apt-get remove docker docker-engine docker-ce docker.io
- 更新索引
sudo apt-get update
- 使用存储库
sudo apt-get install -y apt-transport-https ca-certificates curl software-properties-common
- 添加Docker官方的GPG密钥
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
- 设置stable存储库
sudo add-apt-repository "deb [arch=amd64]
https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
- 更新索引
sudo apt-get update
- 安装最新版本的Docker CE
sudo apt-get install -y docker-ce
- 查看docker版本
docker -v
ubuntu16.04系统apt安装docker以及基本配置
2.安装nvidia-docker2
- 准备阶段
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | \
sudo apt-key add -
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | \
sudo tee /etc/apt/sources.list.d/nvidia-docker.list
- 安装阶段
sudo apt-get update
sudo apt-get install -y nvidia-docker2
- 重启docker
sudo systemctl restart docker
3.修改(替换)镜像源
sudo gedit /etc/docker/daemon.json
在最下面(原来的大括号外面)加入一下几行
{
"registry-mirrors": ["https://docker.mirrors.ustc.edu.cn"]
}
{
"registry-mirrors": ["http://hub-mirror.c.163.com",
"http://docker.mirrors.ustc.edu.cn",
"http://registry.docker-cn.com"]
}
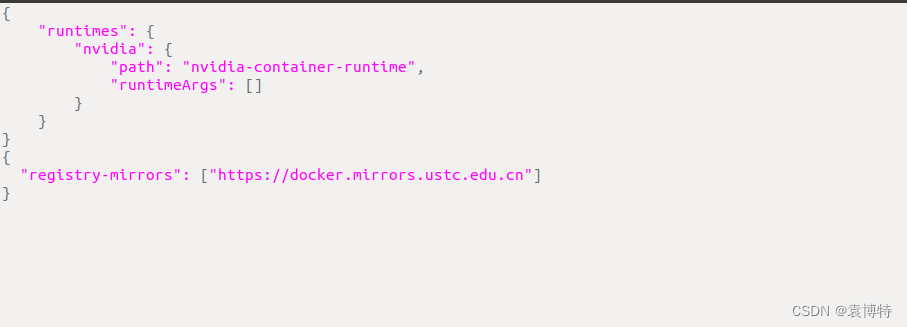
{
"runtimes": {
"nvidia": {
"path": "nvidia-container-runtime",
"runtimeArgs": []
}
}
}
{
"registry-mirrors": ["http://docker.mirrors.ustc.edu.cn"]
}
重新加载daemon和docker
sudo systemctl daemon-reload
sudo systemctl restart docker
二、使用过程
添加root用户
默认情况下,docker 命令会使用 Unix socket 与 Docker 引擎通讯。而只有 root 用户和 docker 组的用户才可以访问 Docker 引擎的 Unix socket。出于安全考虑,一般 Linux 系统上不会直接使用 root 用户。即我们当前的用户不是root用户。
将当前用户加入到docker组中,也可以自己指定用户。
sudo gpasswd -a $USER docker
更新docker组
newgrp docker
否则的话会报下面的错,当然呢,你也可以直接使用sudo命令来规避这个问题。
Got permission denied while trying to connect to the Docker daemon socket at unix:///var/run/docker.sock: Post http://%2Fvar%2Frun%2Fdocker.sock/v1.24/images/create?fromImage=python&platform=linux%2Famd64&tag=3.8.16: dial unix /var/run/docker.sock: connec
Docker指令报错的解决方法:Got permission denied while trying to connect to the Docker daemon socket at unix:/
(但是貌似,后来我运行的时候又报这个错了。)
Got permission denied while trying to connect to the Docker daemon socket at unix:///var/run/docker.sock: Get http://%2Fvar%2Frun%2Fdocker.sock/v1.24/images/json: dial unix /var/run/docker.sock: connect: permission denied
有
一篇博客
认为这是权限问题
之前的操作过程我们发现docker命令使用过程中不断的需要sudo权限,输入密码,这样很不方便,因此,我们接下来将用户加入到docker的权限中,这样每次命令就可以不用sudo了:
sudo chmod a+rw /var/run/docker.sock
ubuntu16.04系统apt安装docker以及基本配置
拉取nvidia的容器
docker-hub官网中nvidia容器的下载地址
在拉取镜像时可以通过
--platform linux/arm64
进行指定平台,否则将默认拉取该tag下的第一种镜像。
docker pull --platform linux/arm64 nvidia/cuda:11.5.1-cudnn8-devel-ubuntu18.04
docker pull --platform linux/amd64 python:3.8.16
channels:
- http://mirrors.ustc.edu.cn/anaconda/pkgs/main/
- http://mirrors.ustc.edu.cn/anaconda/pkgs/free/
- http://mirrors.ustc.edu.cn/anaconda/cloud/conda-forge/
- http://mirrors.ustc.edu.cn/anaconda/cloud/pytorch/
show_channel_urls: true
channel_priority: flexible
error pulling image configuration: Get https://production.cloudflare.docker.com/registry-v2/docker/registry/v2/blobs/sha256/08/0869a4e92f01e49dfebf23d9ee3cf58f212fb8613e8714c8c45a6fe17732f737/data?verify=1686966335-oylLXYpvb58X5SoyGC9sej3d9d4%3D: dial tcp 104.18.123.25:443: i/o timeout
查看镜像
查看Docker镜像最常用的方法是使用docker images命令。该命令会列出Docker主机上的所有镜像,如下所示:
docker images
运行该命令后,你将看到一个表格,其中包含镜像的相关信息,例如ID、创建时间、大小和标记等。
查看容器
查看所有的容器命令如下:
docker ps -a
查看当前正在运行的容器
docker ps
菜鸟教程的
Docker 容器使用
还是很不错的。
新建容器
docker run -itd --name ubuntu-test ubuntu /bin/bash
注:加了 -d 参数默认不会进入容器,想要进入容器需要使用指令 docker exec(下面会介绍到)。
启动容器
在使用 -d 参数时,容器启动后会进入后台。
- 先运行容器
docker start 容器id或者名称
- 进入指定容器中,并且是以终端的形式进行交互
docker exec -it 容器id或者名称 /bin/bash
docker exec
此命令在退出容器终端时,不会导致容器的停止。
退出容器
exit # 停止容器并退出(后台方式运行则仅退出)
Ctrl+P+Q # 不停止容器退出
docker 与 宿主机之间传送文件
1、docker容器向宿主机传送文件
格式:
docker cp container_id:<docker容器内的路径> <本地保存文件的路径>
例:
docker cp 10704c9eb7bb:/root/test.text /home/vagrant/test.txt
2、宿主机向docker容器传送文件
格式:
docker cp 本地文件的路径 container_id:<docker容器内的路径>
例:
docker cp /home/vagrant/test.txt 10704c9eb7bb:/root/test.text
删除容器
docker rm 容器id或者名称
删除镜像
docker rmi 镜像id或者名称
可能会报错
Error response from daemon: conflict: unable to remove repository reference “samuelwei/cuda10.2-pytorch1.5:laste” (must force) – container b48f839fd8d1 is using its referenced image 32ee44522d28
可以先停止容器服务
docker stop 容器id或者名称
容器封装镜像
sudo docker commit -a "jjuv" -m "create new img" 17ba5c781b3c bevformer:v0
sudo docker commit -a "jjuv" -m "create new img" d63a9f3e5fd1 bevformer:v1
docker export d63a9f3e5fd1 > bevformer_image.tar
Option 功能
-a 指定新镜像作者
-c 使用 Dockerfile 指令来创建镜像
-m 提交生成镜像的说明信息
通过容器来导入、导出镜像文件
导出镜像
(1)使用 docker export 命令根据容器 ID 将镜像导出成一个文件。
docker export d63a9f3e5fd1 > bevformer_image.tar
(2)上面命令执行后,可以看到文件已经保存到当前的 docker 终端目录下。
导入镜像
(1)使用 docker import 命令则可将这个镜像文件导入进来。
docker import - new_hangger_server < hangger_server.tar
docker import bevformer_inspur.tar bevformer_inspur:v1.0
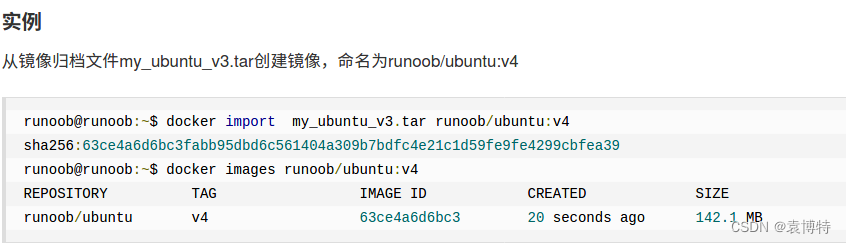
(2)执行 docker images 命令可以看到镜像确实已经导入进来了。
通过镜像来保存、加载镜像文件
保存镜像
(1)下面使用 docker save 命令根据 ID 将镜像保存成一个文件。
docker save a6a4c15ca9db > bevformer_image.tar
(2)我们还可以同时将多个 image 打包成一个文件,比如下面将镜像库中的 postgres 和 mongo 打包:
docker save -o images.tar postgres:9.6 mongo:3.4
载入镜像
使用 docker load 命令则可将这个镜像文件载入进来。
docker load < hangge_server.tar
附:两种方案的差别
特别注意:两种方法不可混用。
如果使用 import 导入 save 产生的文件,虽然导入不提示错误,但是启动容器时会提示失败,会出现类似”docker: Error response from daemon: Container command not found or does not exist”的错误。
1,文件大小不同
export 导出的镜像文件体积小于 save 保存的镜像
2,是否可以对镜像重命名
docker import 可以为镜像指定新名称
docker load 不能对载入的镜像重命名
3,是否可以同时将多个镜像打包到一个文件中
docker export 不支持
docker save 支持
4,是否包含镜像历史
export 导出(import 导入)是根据容器拿到的镜像,再导入时会丢失镜像所有的历史记录和元数据信息(即仅保存容器当时的快照状态),所以无法进行回滚操作。
而 save 保存(load 加载)的镜像,没有丢失镜像的历史,可以回滚到之前的层(layer)。
5,应用场景不同
docker export 的应用场景:主要用来制作基础镜像,比如我们从一个 ubuntu 镜像启动一个容器,然后安装一些软件和进行一些设置后,使用 docker export 保存为一个基础镜像。然后,把这个镜像分发给其他人使用,比如作为基础的开发环境。
docker save 的应用场景:如果我们的应用是使用 docker-compose.yml 编排的多个镜像组合,但我们要部署的客户服务器并不能连外网。这时就可以使用 docker save 将用到的镜像打个包,然后拷贝到客户服务器上使用 docker load 载入。
查看容器大小
docker ps -s

SIZE:
括号外面的,剩余空间大小。如:19.6GB. 表示现在向容器的可写层写入的数据量的大小。
括号里面的,总共可以有多大的空间。(virtual 19.7GB。表示:镜像大小 + 可写层数据量大小 之和。
vitual的大小 19.7GB = 镜像大小0.1GB + 可写层大小19.6GB
bevformer docker
docker run -itd --name ubuntu-test ubuntu /bin/bash
容器启动命令
这篇文章写的docker驱动调用还是很详细的——
docker使用GPU总结
docker run -itd --gpus all --name 容器名 -e NVIDIA_DRIVER_CAPABILITIES=compute,utility -e NVIDIA_VISIBLE_DEVICES=all 镜像名或id
docker run -itd --gpus all --name bevformer-new -p 8010:22 -e NVIDIA_DRIVER_CAPABILITIES=compute,utility -e NVIDIA_VISIBLE_DEVICES=all 87c13a4b9c78
docker start bevformer-new
docker exec -it bevformer-new /bin/bash
使用这个命令新建docker容器,可以直接调用宿主机的显卡驱动。
所以说,只需要安装需要的cuda和cudnn就行。
sudo
apt-get update
apt-get install sudo
gcc-6.2安装
cd home
wget http://ftp.gnu.org/gnu/gcc/gcc-6.2.0/gcc-6.2.0.tar.gz
sudo chmod 777 gcc-6.2.0.tar.gz
tar -xvf gcc-6.2.0.tar.gz
cd gcc-6.2.0
./contrib/download_prerequisites
mkdir build
cd build
../configure --prefix=/usr/local/gcc/gcc-6.2.0 --enable-threads=posix --disable-checking --disable-multilib --enable-languages=c,c++ --disable-libsanitizer
make
sudo make install
ls -l /usr/bin/gcc*
sudo ln -s /usr/local/gcc/gcc-6.2.0/bin/gcc /usr/bin/gcc-6
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-6 40
sudo update-alternatives --config gcc
sudo ln -s /usr/local/gcc/gcc-6.2.0/bin/g++ /usr/bin/g++-6
sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-6 40
sudo update-alternatives --config g++
gcc --version
g++ --version
Ubuntu安装低版本gcc详细教程(安装gcc6.3.0为例)
python安装
wget https://www.python.org/ftp/python/3.8.16/Python-3.8.16.tgz
sudo cp Python-3.8.16.tgz /home/
sudo chmod 777 Python-3.8.16.tgz
tar -xvzf Python-3.8.16.tgz
cd Python-3.8.16
./configure prefix=/usr/local/python3
sudo apt install build-essential zlib1g-dev libncurses5-dev libgdbm-dev libnss3-dev libssl-dev libreadline-dev libffi-dev
make
sudo make install
sudo rm /usr/bin/python
sudo rm /usr/bin/python3
sudo ln -s /usr/local/python3/bin/python3.8 /usr/bin/python
sudo ln -s /usr/local/python3/bin/python3.8 /usr/bin/python3
pip安装
wget -O /tmp/get-pip.py https://bootstrap.pypa.io/get-pip.py
python3 /tmp/get-pip.py
sudo apt install python3-pip
sudo ln -sf /usr/bin/pip3 /usr/local/bin/pip
sudo ln -sf /usr/bin/pip3 /usr/local/bin/pip3
PyTorch and torchvision 安装
pip install torch==1.9.1+cu111 torchvision==0.10.1+cu111 torchaudio==0.9.1 -f https://download.pytorch.org/whl/torch_stable.html
# Recommended torch>=1.9
mmcv-full
pip install mmcv-full==1.4.0 -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.9.0/index.html
mmdet and mmseg
pip install mmdet==2.14.0
pip install mmsegmentation==0.14.1
cuda cudnn安装
cuda_11.1.0_455.23.05_linux.run
sudo sh cuda_11.1.0_455.23.05_linux.run
cudnn-11.1-linux-x64-v8.0.4.30.tgz
tar -zxvf cudnn-11.1-linux-x64-v8.0.4.30.tgz
需要退出容器后,重新加载daemon和docker
sudo systemctl daemon-reload
sudo systemctl restart docker
然后再进入容器,查看是否安装成功
docker start bevformer-new
docker exec -it bevformer-new /bin/bash
nvcc -V

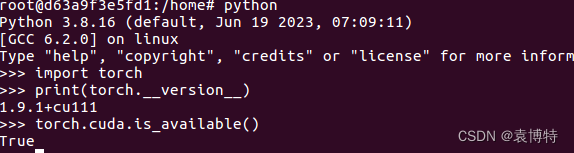
此外,可以测试一下torch和cuda了
python
import torch
print(torch.__version__)
torch.cuda.is_available()
mmdet3d from source code
金额贝尔不过需要手动pip安装一些库,因为版本不是很一致
python setup.py develop
在这里我列出来一些,其他的大家可以自行探索
pip install pandas==1.4.4
pip install matplotlib==3.5.2
pip install scikit-image==0.19.3
pip install networkx==2.2
pip install numpy==1.19.5
将BEVformer拷贝过去
准备数据
我使用的是nuScenes v1.0-mini。
We genetate custom annotation files which are different from mmdet3d’s
python tools/create_data.py nuscenes --root-path ./data/nuscenes --out-dir ./data/nuscenes --extra-tag nuscenes --version v1.0-mini --canbus ./data
报错1
File "/usr/local/python3/lib/python3.8/importlib/__init__.py", line 127, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
ImportError: libGL.so.1: cannot open shared object file: No such file or directory
解决方法
安装这个库即可
pip install opencv-python-headless
【解决方法】libGL.so.1: cannot open shared object file: No such file or directory
报错2
ModuleNotFoundError: No module named 'mmcv._ext'
我分析了一下,应该是安装顺序的问题,我是先安装的mmcv-full,后安装的cuda,所以建立的软链接不太行。
所以这里就是卸载后重新安装一下mmcv-full就行。
pip uninstall mmcv-full
pip install mmcv-full==1.4.0 -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.9.0/index.html
ModuleNotFoundError: No module named ‘mmcv._ext‘解决方案
报错3
File "/usr/local/python3/lib/python3.8/lzma.py", line 27, in <module>
from _lzma import *
ModuleNotFoundError: No module named '_lzma'
将
/usr/local/python3/lib/python3.8/lzma.py
中的
from _lzma import *
from _lzma import _encode_filter_properties, _decode_filter_properties
改为
try:
from _lzma import *
from _lzma import _encode_filter_properties, _decode_filter_properties
except ImportError:
from backports.lzma import *
from backports.lzma import _encode_filter_properties, _decode_filter_properties
但是还是报错
File "/usr/local/python3/lib/python3.8/site-packages/torchvision/datasets/utils.py", line 10, in <module>
import lzma
File "/usr/local/python3/lib/python3.8/lzma.py", line 31, in <module>
from backports.lzma import *
ModuleNotFoundError: No module named 'backports'
再安装
backports.lzma
pip install backports.lzma
报错4
File "/usr/local/python3/lib/python3.8/site-packages/pandas/io/common.py", line 4, in <module>
import bz2
File "/usr/local/python3/lib/python3.8/bz2.py", line 19, in <module>
from _bz2 import BZ2Compressor, BZ2Decompressor
ModuleNotFoundError: No module named '_bz2'
sudo apt-get install libbz2-dev
还是不行,参考了几篇博客。决定,从网上下载一个
_bz2.cpython-38-x86_64-linux-gnu.so
,放到容器的指定位置中
/usr/local/python3/lib/python3.8/lib-dynload/
没想到,竟然成功解决了。
再此给出
_bz2.cpython-38-x86_64-linux-gnu.so
的百度网盘下载链接。
链接:https://pan.baidu.com/s/1HpaqJwsxWwIC5JXa2Lh1Vw
提取码:1234
ModuleNotFoundError: No module named ‘_bz2‘
[问题汇总]Python3解决ModuleNotFoundError: No module named ‘_bz2‘
这是成功后的终端显示。

跑一下
Train BEVFormer with 8 GPUs
./tools/dist_train.sh ./projects/configs/bevformer/bevformer_base.py 8
从笔记本电脑的docker上先跑一下吧
只有一张显卡
./tools/dist_train.sh ./projects/configs/bevformer/bevformer_base.py 1
报错1
看起来像是
IPython
的问题
ImportError:
IPython 8.13+ supports Python 3.9 and above, following NEP 29.
IPython 8.0-8.12 supports Python 3.8 and above, following NEP 29.
When using Python 2.7, please install IPython 5.x LTS Long Term Support version.
Python 3.3 and 3.4 were supported up to IPython 6.x.
Python 3.5 was supported with IPython 7.0 to 7.9.
Python 3.6 was supported with IPython up to 7.16.
Python 3.7 was still supported with the 7.x branch.
See IPython `README.rst` file for more information:
https://github.com/ipython/ipython/blob/main/README.rst
ERROR:torch.distributed.elastic.multiprocessing.api:failed (exitcode: 1) local_rank: 0 (pid: 1633) of binary: /usr/bin/python
我测试了一下,发现docker中
IPython
是8.14.0版本。已经跑通的系统中是7.12.0版本。所以,选择更换一下
pip install IPython==7.12.0
然后,紧接着,有一些依赖库报错,依次进行修改版本,即可。
ipykernel 6.23.2 requires ipython>=7.23.1, but you have ipython 7.12.0 which is incompatible.
pip install ipykernel==5.1.4
pip install jupyter-console==6.1.0
报错2
import _tkinter # If this fails your Python may not be configured for Tk
ModuleNotFoundError: No module named '_tkinter'
ERROR:torch.distributed.elastic.multiprocessing.api:failed (exitcode: 1) local_rank: 0 (pid: 2903) of binary: /usr/bin/python
sudo apt-get install tcl-dev tk-dev python3-tk
然后需要重新编译安装一遍python,这里是把上面的python直接复制下来了。
wget https://www.python.org/ftp/python/3.8.16/Python-3.8.16.tgz
sudo cp Python-3.8.16.tgz /home/
sudo chmod 777 Python-3.8.16.tgz
tar -xvzf Python-3.8.16.tgz
cd Python-3.8.16
./configure prefix=/usr/local/python3
sudo apt install build-essential zlib1g-dev libncurses5-dev libgdbm-dev libnss3-dev libssl-dev libreadline-dev libffi-dev
make
sudo make install
sudo rm /usr/bin/python
sudo rm /usr/bin/python3
sudo ln -s /usr/local/python3/bin/python3.8 /usr/bin/python
sudo ln -s /usr/local/python3/bin/python3.8 /usr/bin/python3
tkinter # If this fails your Python may not be configured for Tk解决方法
Python长征之路–第19天python之tkinter报错你知多少
” MODULENOTFOUNDERROR: NO MODULE NAMED ‘TKINTER’ “的解决方法
解决这个问题,也是深受启发,还是需要先安装依赖库,然后再编译安装python。否则,新安装的依赖库,python是无法使用的。
因此在这里更新一下python安装的步骤:
sudo apt install build-essential zlib1g-dev libncurses5-dev libgdbm-dev libnss3-dev libssl-dev libreadline-dev libffi-dev tcl-dev tk-dev python3-tk
wget https://www.python.org/ftp/python/3.8.16/Python-3.8.16.tgz
sudo cp Python-3.8.16.tgz /home/
sudo chmod 777 Python-3.8.16.tgz
tar -xvzf Python-3.8.16.tgz
cd Python-3.8.16
./configure prefix=/usr/local/python3
make
sudo make install
sudo rm /usr/bin/python
sudo rm /usr/bin/python3
sudo ln -s /usr/local/python3/bin/python3.8 /usr/bin/python
sudo ln -s /usr/local/python3/bin/python3.8 /usr/bin/python3
报错3
再次运行,报错2的问题可以解决,程序也能够正常进入读取环境,但是后面还是报错
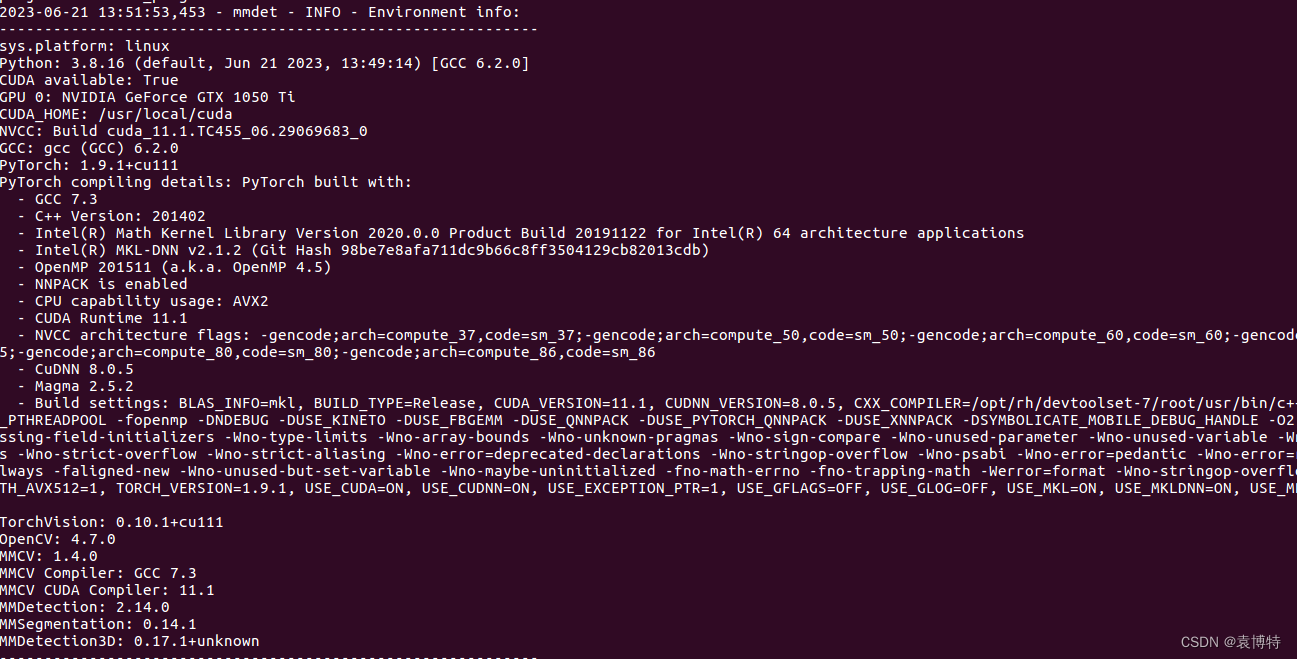
ERROR: Unexpected bus error encountered in worker. This might be caused by insufficient shared memory (shm).
Traceback (most recent call last):
File "./tools/train.py", line 259, in <module>
main()
File "./tools/train.py", line 248, in main
custom_train_model(
File "/home/BEVFormer/projects/mmdet3d_plugin/bevformer/apis/train.py", line 27, in custom_train_model
custom_train_detector(
File "/home/BEVFormer/projects/mmdet3d_plugin/bevformer/apis/mmdet_train.py", line 199, in custom_train_detector
runner.run(data_loaders, cfg.workflow)
File "/usr/local/python3/lib/python3.8/site-packages/mmcv/runner/epoch_based_runner.py", line 127, in run
epoch_runner(data_loaders[i], **kwargs)
File "/usr/local/python3/lib/python3.8/site-packages/mmcv/runner/epoch_based_runner.py", line 47, in train
for i, data_batch in enumerate(self.data_loader):
File "/usr/local/python3/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 521, in __next__
data = self._next_data()
File "/usr/local/python3/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 1203, in _next_data
return self._process_data(data)
File "/usr/local/python3/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 1229, in _process_data
data.reraise()
File "/usr/local/python3/lib/python3.8/site-packages/torch/_utils.py", line 425, in reraise
raise self.exc_type(msg)
RuntimeError: Caught RuntimeError in DataLoader worker process 0.
Original Traceback (most recent call last):
File "/usr/local/python3/lib/python3.8/site-packages/torch/utils/data/_utils/worker.py", line 287, in _worker_loop
data = fetcher.fetch(index)
File "/usr/local/python3/lib/python3.8/site-packages/torch/utils/data/_utils/fetch.py", line 47, in fetch
return self.collate_fn(data)
File "/usr/local/python3/lib/python3.8/site-packages/mmcv/parallel/collate.py", line 79, in collate
return {
File "/usr/local/python3/lib/python3.8/site-packages/mmcv/parallel/collate.py", line 80, in <dictcomp>
key: collate([d[key] for d in batch], samples_per_gpu)
File "/usr/local/python3/lib/python3.8/site-packages/mmcv/parallel/collate.py", line 59, in collate
stacked.append(default_collate(padded_samples))
File "/usr/local/python3/lib/python3.8/site-packages/torch/utils/data/_utils/collate.py", line 54, in default_collate
storage = elem.storage()._new_shared(numel)
File "/usr/local/python3/lib/python3.8/site-packages/torch/storage.py", line 157, in _new_shared
return cls._new_using_fd(size)
RuntimeError: unable to write to file </torch_14342_2828106155>
Error in atexit._run_exitfuncs:
Traceback (most recent call last):
File "/usr/local/python3/lib/python3.8/multiprocessing/popen_fork.py", line 27, in poll
pid, sts = os.waitpid(self.pid, flag)
File "/usr/local/python3/lib/python3.8/site-packages/torch/utils/data/_utils/signal_handling.py", line 66, in handler
_error_if_any_worker_fails()
RuntimeError: DataLoader worker (pid 14366) is killed by signal: Bus error. It is possible that dataloader's workers are out of shared memory. Please try to raise your shared memory limit.
ERROR:torch.distributed.elastic.multiprocessing.api:failed (exitcode: 1) local_rank: 0 (pid: 14286) of binary: /usr/bin/python
Traceback (most recent call last):
File "/usr/local/python3/lib/python3.8/runpy.py", line 194, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/usr/local/python3/lib/python3.8/runpy.py", line 87, in _run_code
exec(code, run_globals)
File "/usr/local/python3/lib/python3.8/site-packages/torch/distributed/launch.py", line 193, in <module>
main()
File "/usr/local/python3/lib/python3.8/site-packages/torch/distributed/launch.py", line 189, in main
launch(args)
File "/usr/local/python3/lib/python3.8/site-packages/torch/distributed/launch.py", line 174, in launch
run(args)
File "/usr/local/python3/lib/python3.8/site-packages/torch/distributed/run.py", line 689, in run
elastic_launch(
File "/usr/local/python3/lib/python3.8/site-packages/torch/distributed/launcher/api.py", line 116, in __call__
return launch_agent(self._config, self._entrypoint, list(args))
File "/usr/local/python3/lib/python3.8/site-packages/torch/distributed/launcher/api.py", line 244, in launch_agent
raise ChildFailedError(
torch.distributed.elastic.multiprocessing.errors.ChildFailedError:
***************************************
./tools/train.py FAILED
=======================================
按照问题出现的先后顺序,逐一进行解决吧
首先是第一个问题
ERROR: Unexpected bus error encountered in worker. This might be caused by insufficient shared memory (shm).
问题就是docker容器的共享内存太小了,不够用。
在容器中查看共享内存的大小
df -h | grep shm

没有头,可以看下面的注释
文件系统 容量 已用 可用 已用% 挂载点
可以看出,共享内存也太小了,64MB。
这个问题也好解决
最简单的办法是重新新建一个容器
在run的时候添加参数:
--shm-size 6G
改变已有容器的shmsize
(1) 先停止所有容器,
docker stop container_ID
(2) 停止docker服务。
要关闭docker, 否则后面的操作步骤会无效!!
systemctl stop docker
(3)
cd /var/lib/docker/containers/要修改的容器id
,这个目录是放容器的,有可能因为改了路径有变化。
(4)
sudo gedit hostconfig.json
,找到ShmSize

67108864KB 就约等于64M
修改这个数字,8589934592=8x1024x1024x1024
也就是8GB(根据自己的需求来就行)
(5) 启动docker服务。
systemctl start docker
(6) 启动容器,并查看是否修改有效。
docker start bevformer-new
docker exec -it bevformer-new /bin/bash
df -h | grep shm

这篇文章的路径写的有问题
docker修改shm-size
报错4
看bug应该是cuda算力不够用了,到这里就算是测试完毕了。
可以将docker容器封装成镜像,然后放到服务器上去了。
RuntimeError: CUDA out of memory. Tried to allocate 1.59 GiB (GPU 0; 3.94 GiB total capacity; 2.51 GiB already allocated; 682.50 MiB free; 2.54 GiB reserved in total by PyTorch)
ERROR:torch.distributed.elastic.multiprocessing.api:failed (exitcode: 1) local_rank: 0 (pid: 52) of binary: /usr/bin/python
Traceback (most recent call last):
File "/usr/local/python3/lib/python3.8/runpy.py", line 194, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/usr/local/python3/lib/python3.8/runpy.py", line 87, in _run_code
exec(code, run_globals)
File "/usr/local/python3/lib/python3.8/site-packages/torch/distributed/launch.py", line 193, in <module>
main()
File "/usr/local/python3/lib/python3.8/site-packages/torch/distributed/launch.py", line 189, in main
launch(args)
File "/usr/local/python3/lib/python3.8/site-packages/torch/distributed/launch.py", line 174, in launch
run(args)
File "/usr/local/python3/lib/python3.8/site-packages/torch/distributed/run.py", line 689, in run
elastic_launch(
File "/usr/local/python3/lib/python3.8/site-packages/torch/distributed/launcher/api.py", line 116, in __call__
return launch_agent(self._config, self._entrypoint, list(args))
File "/usr/local/python3/lib/python3.8/site-packages/torch/distributed/launcher/api.py", line 244, in launch_agent
raise ChildFailedError(
torch.distributed.elastic.multiprocessing.errors.ChildFailedError:
***************************************
./tools/train.py FAILED
=======================================
容器环境设置
1 修改容器的root密码
进入容器中,使用如下命令修改root用户密码:
passwd
2 安装服务器远程调试需要的ssh
sudo apt-get install openssh-server
sudo apt-get install openssh-client
报错1
sudo: error in /etc/sudo.conf, line 0 while loading plugin `sudoers_policy'
sudo: /usr/lib/sudo/sudoers.so must be only be writable by owner
sudo: fatal error, unable to load plugins
主要是权限的问题
chmod 644 /usr/lib/sudo/sudoers.so
chown -R root /usr/lib/sudo
sudo: error in /etc/sudo.conf, line 0 while loading plugin ‘sudoers_policy‘
sudo: error in /etc/sudo.conf, line 0 while loading plugin ‘sudoers_policy’
报错2
sudo: /etc/sudoers is world writable
sudo: no valid sudoers sources found, quitting
sudo: unable to initialize policy plugin
仍然是权限的问题
chmod 555 /etc/sudoers
chmod 555 /etc/sudoers.d/README
sudo: /etc/sudoers is world writable 错误解决方案
3 修改ssh配置文件
修改ssh配置文件以下选项:
vim /etc/ssh/sshd_config
将
PermitRootLogin prohibit-password
注释掉
并在下面添加一行
PermitRootLogin yes
保存退出即可。
4 启动sshd服务
/etc/init.d/ssh restart

5 退出容器,连接测试
注意这里的测试是在镜像上传服务器,并且新建容器(带有端口设置的)后进行的。
ssh root@127.0.0.1 -p 8010
注意,此处应该是测试8010端口。
输入密码成功进入容器内部即配置成功。
最简单的办法是重新新建一个容器
此处需要现将容器封装镜像,然后再生成新的容器之后再测试。
注意生成新的容器的代码需要更换了
sudo docker run –gpus all -it -d -p 8010:22 –name 容器名称 -v 本地路径或服务器物理路径:容器内路径 -d 镜像id /bin/bash ;
(-p 指定端口映射,格式:主机(宿主)端口:容器端口。22是服务器的端口。)
docker run -itd --gpus all --name bevformer-new -p 8010:22 -e NVIDIA_DRIVER_CAPABILITIES=compute,utility -e NVIDIA_VISIBLE_DEVICES=all 87c13a4b9c78
docker start bevformer-new
docker exec -it bevformer-new /bin/bash
docker run
要加入参数
-p 8010:22
。
其中,8010是宿主端口,22是容器端口(我们服务器的端口号是22,各位根据自己的实际情况来)。
改变已有容器的端口号
后面验证过了,这个法子不行。
和前面设置shmsize的时候一样。
(1) 先停止所有容器,
docker stop container_ID
(2) 停止docker服务。
要关闭docker, 否则后面的操作步骤会无效!!
systemctl stop docker
(3)
cd /var/lib/docker/containers/要修改的容器id
,这个目录是放容器的,有可能因为改了路径有变化。
(4)修改
hostconfig.json
sudo gedit hostconfig.json
找到PortBindings
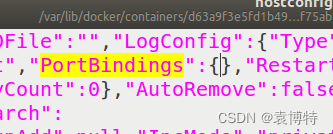
通常情况下,
PortBindings
是空的,即没有设置过。
在这里只需要手动输入
"8080/22":[{"HostIp":"","HostPort":"8080"}]
主机(宿主)端口为8080
容器端口为22。(根据自己服务器的情况自行设置,也可以设置为ip)

(5) 修改
config.v2.json
sudo gedit config.v2.json
找到
ExposedPorts
在ExposedPorts里面添加”8080/22″:{}
由于我的里面没有
ExposedPorts
这一项,所以直接手动添加进去就行。(添加的位置就在
AttachStderr
的后面或者
Tty
的前面)

"ExposedPorts":{"8080/22":{}}

(6) 启动docker服务。
systemctl start docker
(6) 启动容器,并查看是否修改有效。
docker start bevformer-new
添加docker容器端口(映射宿主机和docker容器中的端口)
docker容器增加端口映射最佳实践(修改配置文件方式)
报错1
Error response from daemon: driver failed programming external connectivity on endpoint bevformer-new (1ea7e4c50409e2c4e590f0bfa1328095b50f3cb8eeef7d1680354e7866ef999d): invalid transport protocol: 0
Error: failed to start containers: d63a9f3e5fd1
打不开容器了,应该就是端口号的问题。
按照
Linux中启动Docker容器报错:Error response from daemon: driver failed programming external connectivity
这篇博客的说法,使用
systemctl restart docker
重启docker,也没法解决问题。
看来直接手动调节端口号还是不太行,需要重新新建一个容器,并且在一开始的时候就指定好端口号。
我一步一步的往后退。