文章目录
在使用mybatis时,一般都是书写mapper文件来执行sql,mapper文件中sql下发到数据库执行要经过下面几个步骤:

- MapperProxy接口代理: 用于代理mapper文件中sql执行接口,其目的是简化对MyBatis使用,底层使用动态代理实现;
-
SqlSession:sql会话,提供增删改查API,其本身不作任何业务逻辑的处理,所有处理都交给执行器。这是一个典型的
门面模式设计
。 - Executor:处理器,核心作用是处理SQL请求、事物管理、维护缓存以及批处理等 。执行器在的角色更像是一个管理员,接收SQL请求,然后根据缓存、批处理等逻辑来决定如何执行这个SQL请求。并交给JDBC处理器执行具体SQL。
- StatementHandler:JDBC处理器,他的作用就是用于通过JDBC具体处理SQL和参数的。在会话中每调用一次CRUD,JDBC处理器就会生成一个实例与之对应(命中缓存除外)。
下面我们集中介绍下Executor
1. Executor功能介绍
Executor是mybatis的执行接口,执行器主要包括如下功能:
- 基本功能:改、查,没有增删的原因是,所有的增删操作都可以归结到改;
- 缓存维护:这里的缓存主要是为一级缓存服务,功能包括创建缓存Key、清理缓存、判断缓存是否存在;
- 事物管理:提交、回滚、关闭、批处理刷新。
下面看下执行器的上下继承关系
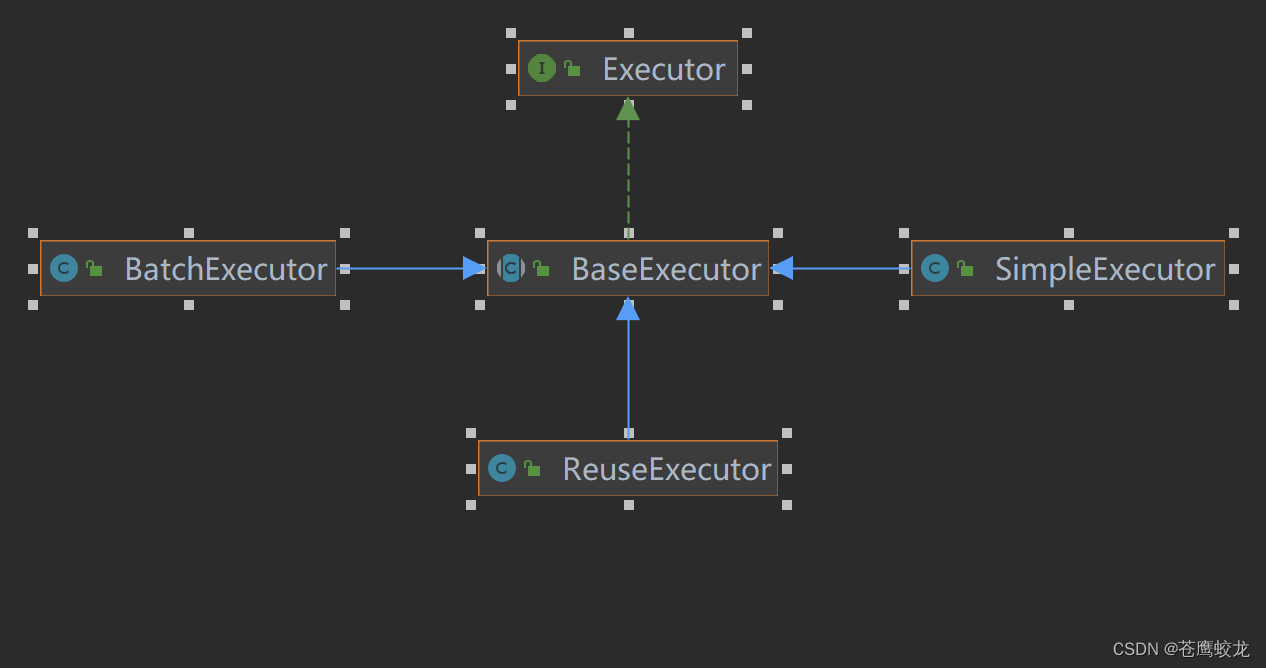
共包括3中Executor执行器,分别为SimpleExecutor、ReuseExecutor、BatchExecutor,其中BaseExecutor是封装了获取链接、维护事物、以及一级缓存相关的通用操作,三种执行器都是继承BaseExecutor而来。
2. Executor执行器种类
2.1 SimpleExecutor简单执行器
SimpleExecutor是默认执行器,它的行为是每处理一次会话当中的SQl请求都会通过对应的StatementHandler 构建一个新个Statement,这就会导致即使是相同SQL语句也无法重用Statement。
案例如下所示,本篇所有案例环境构建参考
此篇文章
package com.lzj.example.executor;
import com.lzj.example.MybatisUtil;
import org.apache.ibatis.executor.SimpleExecutor;
import org.apache.ibatis.mapping.MappedStatement;
import org.apache.ibatis.session.Configuration;
import org.apache.ibatis.session.RowBounds;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.sql.SQLException;
import java.util.List;
@Component
public class SimpleExecutorExample {
@Autowired
private MybatisUtil mybatisUtil;
public void SimpleExecutorTest() throws SQLException {
Configuration configuration = mybatisUtil.getConfiguration();
MappedStatement ms = configuration.getMappedStatement("com.lzj.dao.UserDao.selectOne");
SimpleExecutor executor = new SimpleExecutor(mybatisUtil.getConfiguration(), mybatisUtil.getJdbcTransaction());
List<Object> lists = executor.doQuery(ms, 1, RowBounds.DEFAULT, SimpleExecutor.NO_RESULT_HANDLER, ms.getBoundSql(1));
System.out.println(lists.get(0));
List<Object> lists1 = executor.doQuery(ms, 1, RowBounds.DEFAULT, SimpleExecutor.NO_RESULT_HANDLER, ms.getBoundSql(1));
System.out.println(lists1.get(0));
}
}
执行该案例会有如下输出,可见对于同样的一条SQL,简单执行器也是要编译两遍的。
……
2022-11-12 23:07:21.515 DEBUG 12392 --- [ main] com.lzj.dao.UserDao.selectOne : ==> Preparing: select * from user where id=?
2022-11-12 23:07:21.562 DEBUG 12392 --- [ main] com.lzj.dao.UserDao.selectOne : ==> Parameters: 1(Integer)
2022-11-12 23:07:21.620 DEBUG 12392 --- [ main] com.lzj.dao.UserDao.selectOne : <== Total: 1
User{id=1, name='xiaowang', age=22}
2022-11-12 23:07:21.624 DEBUG 12392 --- [ main] com.lzj.dao.UserDao.selectOne : ==> Preparing: select * from user where id=?
2022-11-12 23:07:21.624 DEBUG 12392 --- [ main] com.lzj.dao.UserDao.selectOne : ==> Parameters: 1(Integer)
2022-11-12 23:07:21.625 DEBUG 12392 --- [ main] com.lzj.dao.UserDao.selectOne : <== Total: 1
User{id=1, name='xiaowang', age=22}
2.2 ReuseExecutor可重用执行器
ReuseExecutor 区别在于他会将在会话期间内的Statement进行缓存,并使用SQL语句作为Key。所以当执行下一请求的时候,不在重复构建Statement,而是从缓存中取出并设置参数,然后执行。
package com.lzj.example.executor;
import com.lzj.example.MybatisUtil;
import org.apache.ibatis.executor.ReuseExecutor;
import org.apache.ibatis.executor.SimpleExecutor;
import org.apache.ibatis.mapping.MappedStatement;
import org.apache.ibatis.session.Configuration;
import org.apache.ibatis.session.RowBounds;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.sql.SQLException;
import java.util.List;
@Component
public class ReuseExecutorExample {
@Autowired
private MybatisUtil mybatisUtil;
public void resueExecutorTest() throws SQLException {
Configuration configuration = mybatisUtil.getConfiguration();
MappedStatement ms = configuration.getMappedStatement("com.lzj.dao.UserDao.selectOne");
ReuseExecutor executor = new ReuseExecutor(configuration, mybatisUtil.getJdbcTransaction());
List<Object> lists = executor.doQuery(ms, 1, RowBounds.DEFAULT, SimpleExecutor.NO_RESULT_HANDLER, ms.getBoundSql(1));
System.out.println(lists.get(0));
List<Object> lists1 = executor.doQuery(ms, 2, RowBounds.DEFAULT, SimpleExecutor.NO_RESULT_HANDLER, ms.getBoundSql(2));
System.out.println(lists1.get(0));
}
}
执行该案例,输出包含如下所示,从日志可以看出对于可重用执行器执行同条SQL只是参数不同,只进行一次编译,每次设置不同参数而已。
……
2022-11-12 23:20:05.059 DEBUG 15456 --- [ main] com.lzj.dao.UserDao.selectOne : ==> Preparing: select * from user where id=?
2022-11-12 23:20:05.099 DEBUG 15456 --- [ main] com.lzj.dao.UserDao.selectOne : ==> Parameters: 1(Integer)
2022-11-12 23:20:05.152 DEBUG 15456 --- [ main] com.lzj.dao.UserDao.selectOne : <== Total: 1
User{id=1, name='xiaowang', age=22}
2022-11-12 23:20:05.154 DEBUG 15456 --- [ main] com.lzj.dao.UserDao.selectOne : ==> Parameters: 2(Integer)
2022-11-12 23:20:05.157 DEBUG 15456 --- [ main] com.lzj.dao.UserDao.selectOne : <== Total: 1
User{id=2, name='xiaoli', age=25}
注
:执行器都不能跨线程调用。
2.3 BatchExecutor批处理执行器
BatchExecutor 顾名思议,它就是用来作批处理的。但会将所 有SQL请求集中起来,最后调用Executor.flushStatements() 方法时一次性将所有请求发送至数据库。
BatchExecutor只对增删改的SQL才有效。该执行器将SQL一次性插入数据库是有条件的,即只有连续相同的SQL语句并且相同的SQL才会重用Statement,并利用其批处理功能,否则就不能利用批处理功能。
看下面案例
package com.lzj.example.executor;
import com.lzj.bean.User;
import com.lzj.example.MybatisUtil;
import org.apache.ibatis.executor.BatchExecutor;
import org.apache.ibatis.mapping.MappedStatement;
import org.apache.ibatis.session.Configuration;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.sql.SQLException;
import java.util.HashMap;
import java.util.Map;
@Component
public class BatchExecutorExample {
@Autowired
private MybatisUtil mybatisUtil;
public void batchExecutorTest() throws SQLException {
Configuration configuration = mybatisUtil.getConfiguration();
MappedStatement ms = configuration.getMappedStatement("com.lzj.dao.UserDao.updAge");
MappedStatement ms1 = configuration.getMappedStatement("com.lzj.dao.UserDao.insert");
BatchExecutor executor = new BatchExecutor(configuration, mybatisUtil.getJdbcTransaction());
User user = new User();
user.setId(1);
user.setAge(23);
executor.doUpdate(ms, user);
user.setId(3);
user.setName("xiaozhang");
user.setAge(30);
executor.doUpdate(ms1, user);
user.setId(2);
user.setAge(26);
executor.doUpdate(ms, user);
executor.doFlushStatements(false);
}
}
执行案例输出如下所示,虽然两条update语句映射相同,但两条update中间增加了一条insert语句,此时就会导致不能利用批处理功能。如果去掉insert语句,那么这两条update语句是可以利用批处理一次性更新库表的。
2022-11-12 23:56:11.771 DEBUG 14700 --- [ main] com.lzj.dao.UserDao.updAge : ==> Preparing: update user set age=? where id=?
2022-11-12 23:56:11.817 DEBUG 14700 --- [ main] com.lzj.dao.UserDao.updAge : ==> Parameters: 23(Integer), 1(Integer)
2022-11-12 23:56:11.817 DEBUG 14700 --- [ main] com.lzj.dao.UserDao.insert : ==> Preparing: insert into user values (?,?,?)
2022-11-12 23:56:11.817 DEBUG 14700 --- [ main] com.lzj.dao.UserDao.insert : ==> Parameters: 3(Integer), xiaozhang(String), 30(Integer)
2022-11-12 23:56:11.818 DEBUG 14700 --- [ main] com.lzj.dao.UserDao.updAge : ==> Preparing: update user set age=? where id=?
2022-11-12 23:56:11.820 DEBUG 14700 --- [ main] com.lzj.dao.UserDao.updAge : ==> Parameters: 26(Integer), 2(Integer)
2.4 CachingExecutor二级缓存执行器
除了上面演示的从BaseExecutor继承而来的3中执行器,还有一种是直接实现Exector接口而来的CachingExecutor二级缓存执行器(后面会讲二级缓存与一级缓存的区别)。
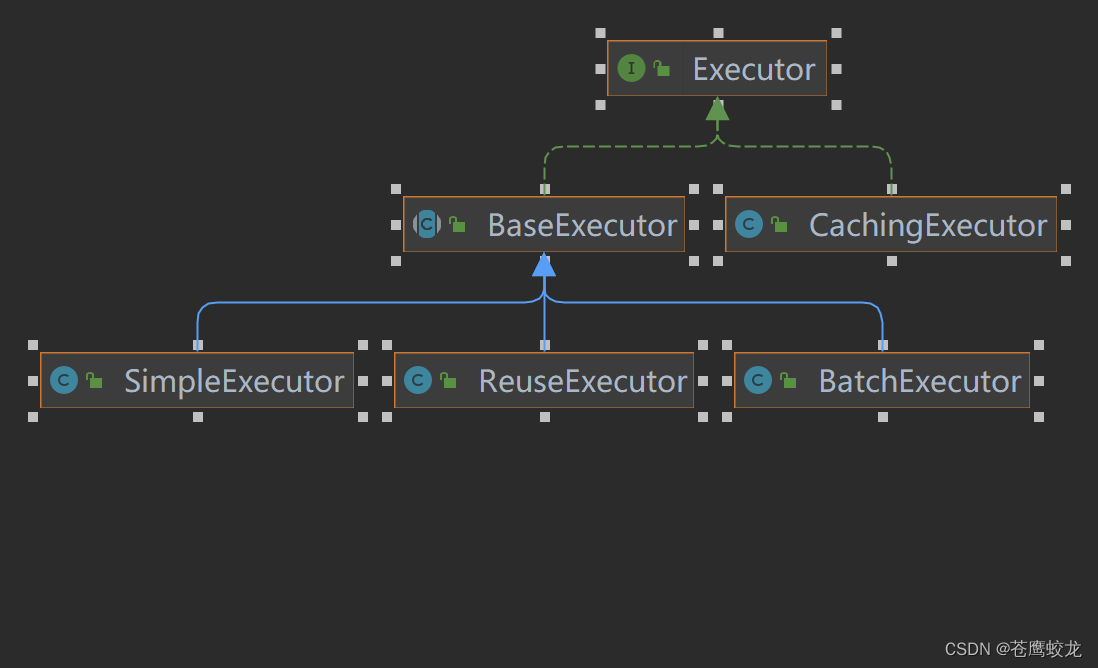
为什么一级缓存的功能在BaseExecutor,二级缓存确单独实现了个CachingExecutor?因为一级缓存天生就是存在的,二级缓存是设置了才会有,不设置就没有,如果把二级缓存也设置到BaseExecutor中就会增加BaseExecutor中分支增加,职责也不专一。
CachingExecutor利用
装饰器模式
对SimpleExecutor或者ReuseExecutor或者BatchExecutor进行装饰,在构造CachingExecutor时需要传一个Executor,也即三种执行器中任何一种都可以,CachingExecutor只执行二级缓存的逻辑,其余操作比如查询、修改逻辑还是交给包装的Executor的执行器进行执行。
CachingExecutor执行SQL必须commit后,后续如有相同SQL执行才会命中缓存,因为二级缓存是可以跨线程处理的,如果在一个session中没有进行commit处理两条相同的SQL那是命中的一级缓存。
如需二级缓存首先要开启二级缓存,比如在application.yml中添加mybatis.configuration.cache-enabled: true
mybatis:
mapper-locations: classpath*:mapper/*Mapper.xml
configuration:
cache-enabled: true
然后在需要二级缓存的mapper中添加
<cache></cache>
配置
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--namespace为UserDao接口的全类名-->
<mapper namespace="com.lzj.dao.UserDao">
<cache></cache>
<!--selectOne要与UserDao接口中的接口方法名一致-->
<!--parameterType和resultType指定的类型除了基本类型外,自定义的类要用全类名-->
<select id="selectOne" parameterType="int" resultType="com.lzj.bean.User">
select * from user where id=#{id}
</select>
<update id="updAge" parameterType="com.lzj.bean.User">
update user set age=#{age} where id=#{id}
</update>
<insert id="insert" parameterType="com.lzj.bean.User">
insert into user values (#{id},#{name},#{age})
</insert>
</mapper>
下面看如下测试案例
package com.lzj.example.executor;
import com.lzj.example.MybatisUtil;
import org.apache.ibatis.executor.CachingExecutor;
import org.apache.ibatis.executor.SimpleExecutor;
import org.apache.ibatis.mapping.MappedStatement;
import org.apache.ibatis.session.Configuration;
import org.apache.ibatis.session.RowBounds;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.sql.SQLException;
import java.util.List;
@Component
public class CachingExecutorExample {
@Autowired
private MybatisUtil mybatisUtil;
public void cachingExecutorTest() throws SQLException {
Configuration configuration = mybatisUtil.getConfiguration();
MappedStatement ms = configuration.getMappedStatement("com.lzj.dao.UserDao.selectOne");
SimpleExecutor executor = new SimpleExecutor(mybatisUtil.getConfiguration(), mybatisUtil.getJdbcTransaction());
CachingExecutor cachingExecutor = new CachingExecutor(executor);
cachingExecutor.query(ms, 1, RowBounds.DEFAULT, SimpleExecutor.NO_RESULT_HANDLER);
cachingExecutor.query(ms, 1, RowBounds.DEFAULT, SimpleExecutor.NO_RESULT_HANDLER);
cachingExecutor.commit(true);
cachingExecutor.query(ms, 1, RowBounds.DEFAULT, SimpleExecutor.NO_RESULT_HANDLER);
cachingExecutor.query(ms, 1, RowBounds.DEFAULT, SimpleExecutor.NO_RESULT_HANDLER);
}
}
运行该案例有如下输出,从日志可以看出,第一次select时缓存命中率为0.0,这个很好理解,第一次查询还没有缓存所以命中率为0.0;而第二次命中率也是0.0,为什么呢?因为第一次和第二次之间没有commit,导致第二次查询命中的是一级缓存而不是二级缓存;第二次查询后进行了commit,可以看出后面两次查询二级缓存命中率逐渐增高。
2022-11-13 15:33:22.903 DEBUG 17948 --- [nio-8004-exec-2] com.lzj.dao.UserDao : Cache Hit Ratio [com.lzj.dao.UserDao]: 0.0
2022-11-13 15:33:22.929 DEBUG 17948 --- [nio-8004-exec-2] com.lzj.dao.UserDao.selectOne : ==> Preparing: select * from user where id=?
2022-11-13 15:33:22.993 DEBUG 17948 --- [nio-8004-exec-2] com.lzj.dao.UserDao.selectOne : ==> Parameters: 1(Integer)
2022-11-13 15:33:23.055 DEBUG 17948 --- [nio-8004-exec-2] com.lzj.dao.UserDao.selectOne : <== Total: 1
2022-11-13 15:33:23.062 DEBUG 17948 --- [nio-8004-exec-2] com.lzj.dao.UserDao : Cache Hit Ratio [com.lzj.dao.UserDao]: 0.0
2022-11-13 15:33:23.066 DEBUG 17948 --- [nio-8004-exec-2] com.lzj.dao.UserDao : Cache Hit Ratio [com.lzj.dao.UserDao]: 0.3333333333333333
2022-11-13 15:33:23.067 DEBUG 17948 --- [nio-8004-exec-2] com.lzj.dao.UserDao : Cache Hit Ratio [com.lzj.dao.UserDao]: 0.5
3 SqlSession
SqlSession是mybatis中sql的会话,通过SqlSession可以执行SQL命令、管理事务。SqlSession内部对mybatis的配置以及上述介绍的Executor进行了封装,我们通过SqlSession的一个实现DefaultSqlSession就可以看出,从下面构造器可以看出封装的内容。
public DefaultSqlSession(Configuration configuration, Executor executor, boolean autoCommit) {
this.configuration = configuration;
this.executor = executor;
this.dirty = false;
this.autoCommit = autoCommit;
}
既然SqlSession进行了封装,因此大大简化了执行SQL的代码,比如执行一个查询操作所示,直接通过SqlSession的selectList一行代码执行数据库获取数据库获取执行结果。
package com.lzj.example.sqlsession;
import com.lzj.example.MybatisUtil;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.util.List;
@Component
public class SqlSessionExample {
@Autowired
private MybatisUtil mybatisUtil;
public void sqlSessionTest1(){
SqlSessionFactory factory = mybatisUtil.getFactory();
SqlSession sqlSession = factory.openSession(true); //true表示自动提交
List<Object> list = sqlSession.selectList("com.lzj.dao.UserDao.selectOne", 2);
System.out.println(list.get(0));
}
}
MybatisUtil中获取factory的代码如下所示
SqlSessionFactoryBuilder factoryBuilder = new SqlSessionFactoryBuilder();
factory = factoryBuilder.build(MybatisUtil.class.getResourceAsStream("/mybatis-config.xml"));
mybatis-config.xml的配置如下所示
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<settings>
<!--开启二级缓存-->
<setting name="cacheEnabled" value="true"/>
</settings>
<!--数据库配置-->
<environments default="mysql">
<environment id="mysql">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/lzj?characterEncoding=utf8"/>
<property name="username" value="root"/>
</dataSource>
</environment>
</environments>
<!--mapper位置-->
<mappers>
<mapper resource="mapper/UserMapper.xml"></mapper>
</mappers>
</configuration>
执行
List<Object> list = sqlSession.selectList("com.lzj.dao.UserDao.selectOne", 2);
一句时,mybatis底层其实是按如图所示流程进行执行的,先通过SqlSession获取了CachingExecutor二级缓存执行器,如果二级缓存中已缓存SQL直接返回,如果未命中缓存则获取CachingExecutor包装的BaseExecutor执行器(本案例中是SimpleExecutor执行器),然后判断BaseExecutor执行器中是否命中一级缓存,如果命中则直接返回,否则继续调SimpleExecutor中的query方法查询数据库。

通过打断点的方式可以看出默认的DefaultSqlSession内部包装的CachingExecutor二级缓存执行器,二级缓存执行器内部装饰了SimpleExecutor简单执行器。

下面我们通过跟踪源码方式一步步剖析执行流程。
首先执行了DefaultSqlSession中selectList方法,根本就是调用二级缓存先查询缓存数据。
@Override
public <E> List<E> selectList(String statement, Object parameter) {
return this.selectList(statement, parameter, RowBounds.DEFAULT);
}
@Override
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
/*首先通过statement id获取mapper接口对应的MappedStatement, statement id就代表mapper文件中方法id,一个mapper文件不能有重复的id*/
MappedStatement ms = configuration.getMappedStatement(statement);
/*executor代表二级二级换成执行器,首先调用二级查询方法查询sql*/
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
MappedStatement解释:每个MappedStatement对应了我们自定义Mapper接口中的一个方法,它保存了开发人员编写的SQL语句、参数结构、返回值结构、Mybatis对它的处理方式的配置等细节要素,是对一个SQL命令是什么、执行方式的完整定义。可以说,有了它Mybatis就知道如何去调度四大组件顺利的完成用户请求。
下面调二级缓存执行器的query方法来获取缓存中数据或者从数据库中获取数据。
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameterObject);
/*获取换成key*/
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
Cache cache = ms.getCache();
if (cache != null) {
/*检查mapper文件中,是否有要求刷新缓存*/
flushCacheIfRequired(ms);
/*判断mapper文件中是否运行二级缓存;并且对于缓存的sql,不再运行自定义ResultHandler*/
if (ms.isUseCache() && resultHandler == null) {
/*mapper文件中书写的SQL确保输入参数是in模式*/
ensureNoOutParams(ms, boundSql);
@SuppressWarnings("unchecked")
/*从缓存中获取结果*/
List<E> list = (List) tcm.getObject(cache, key);
if (list == null) {
/*如果缓存中无结果,从二级缓存执行器装饰的执行器也即SimpleExecutor执行器查询数据库获取结果*/
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
/*获取的结果放到缓存中*/
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
/*如果缓存为空,就调用二级缓存装饰的执行器,这个地方为SimpleExecutor进行查询SQL*/
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
下一篇文章分析一级缓存和二级缓存源码
参考:源码阅读网