一、概述
~~~~~~~
目前依存树分析领域两大主流方法分别是基于转移(Transition-based)和基于图(Graph-based)的依存分析。基于图的算法将依存分析建模为在有向完全图中求解最大生成树的问题。基于转移的依存分析算法将句子的解码过程建模为一个有限自动机问题。
~~~~~~~
基于转移的依存分析方法。这种方法从起始转移状态开始,不断地执行转移动作从一个状态进入另一个状态,最终达到终结状态,并将终结状态对应的树(或图)作为分析结果。转移状态包括一个保存正在处理中的词的栈(Stack),一个保存待处理词的缓存(Buffer)(另一篇推荐的博文中说道,这里的buffer也被翻译为队列),和一个记录已经生成的依存弧的存储器。转移动作通常包括如移进、规约并生成依存弧等。数据驱动的基于转移依存句法分析的目标是训练一个分类器。这个分类器对给定转移状态预测下一步要执行的转移动作。

依存句法分析标注关系 (共14种) 及含义
| 关系类型 | Tag | Description | Example |
|---|---|---|---|
| 主谓关系 | SBV | subject-verb | 我送她一束花 (我 <– 送) |
| 动宾关系 | VOB | 直接宾语,verb-object | 我送她一束花 (送 –> 花) |
| 间宾关系 | IOB | 间接宾语,indirect-object | 我送她一束花 (送 –> 她) |
| 前置宾语 | FOB | 前置宾语,fronting-object | 他什么书都读 (书 <– 读) |
| 兼语 | DBL | double | 他请我吃饭 (请 –> 我) |
| 定中关系 | ATT | attribute | 红苹果 (红 <– 苹果) |
| 状中结构 | ADV | adverbial | 非常美丽 (非常 <– 美丽) |
| 动补结构 | CMP | complement | 做完了作业 (做 –> 完) |
| 并列关系 | COO | coordinate | 大山和大海 (大山 –> 大海) |
| 介宾关系 | POB | preposition-object | 在贸易区内 (在 –> 内) |
| 左附加关系 | LAD | left adjunct | 大山和大海 (和 <– 大海) |
| 右附加关系 | RAD | right adjunct | 孩子们 (孩子 –> 们) |
| 独立结构 | IS | independent structure | 两个单句在结构上彼此独立 |
| 核心关系 | HED | head | 指整个句子的核心 |
依存句法分析通常满足3个约束
1.单核心,即句子中每个词语都只依存于一个核心词
2.弱联通
3.无环(每个连接弧是单向的)
依存句法准确率指标
UAS=核心节点正确的词数/总词数100%
LAS=核心节点正确且依存关系也正确的词数/总词数100%
CM=依存树完全正确的句子数/总句子数100%
RA=根节点正确的句子数/总句子数100%
二、基于图的依存句法分析
Chu-Liu/Edmonds算法之无环解析
前期介绍
该实验用的数据结构是python的嵌套字典,形如:
graph = {‘root’: {‘w0’: 3, ‘w1’: 4, ‘w2’: 3}, ‘w0’: {‘root’: 9, ‘w1’: 30, ‘w2’: 11}, ‘w1’: {‘root’: 10, ‘w0’: 20, ‘w2’: 0}, ‘w2’: {‘root’: 9, ‘w0’: 3, ‘w1’: 30}}
其中外层字典的key值是依存对中的依赖项,内层字典的key值是依存对中的核心词,内层字典的value值是依存对的权重,也就是依存对成立的可能性的大小。Chu-Liu/Edmonds算法要做的就是为除了根节点以为的其他词找到核心词。该篇博客只谈没循环的依存树,之后再讲有循环的如何解析。
具体步骤
1、如果有进入根的弧,则将其全部丢弃;
这个步骤比较好处理,只有将字典中:’root’: {‘w0’: 3, ‘w1’: 4, ‘w2’: 3}这个部分删掉,就不存在进入根节点的弧了。
如下图,将红色弧去掉:

2、对于除根以外的每个节点,选择权重最大的输入弧,让所选的n-1个弧成为集合s。
这一步写了一个循环,逐个比较内层字典的value值,选出最大的并且记录当前的key值,赋值给一个新图。
代码如下:
new_graph = {}
for d0 in graph:
tem = 0
for d1 in graph[d0]:
if graph[d0][d1] > tem:
tem = graph[d0][d1]
temp = d1
new_graph[d0] = {}
new_graph[d0][temp] = tem
形式化如下图:
处理前:

处理后:
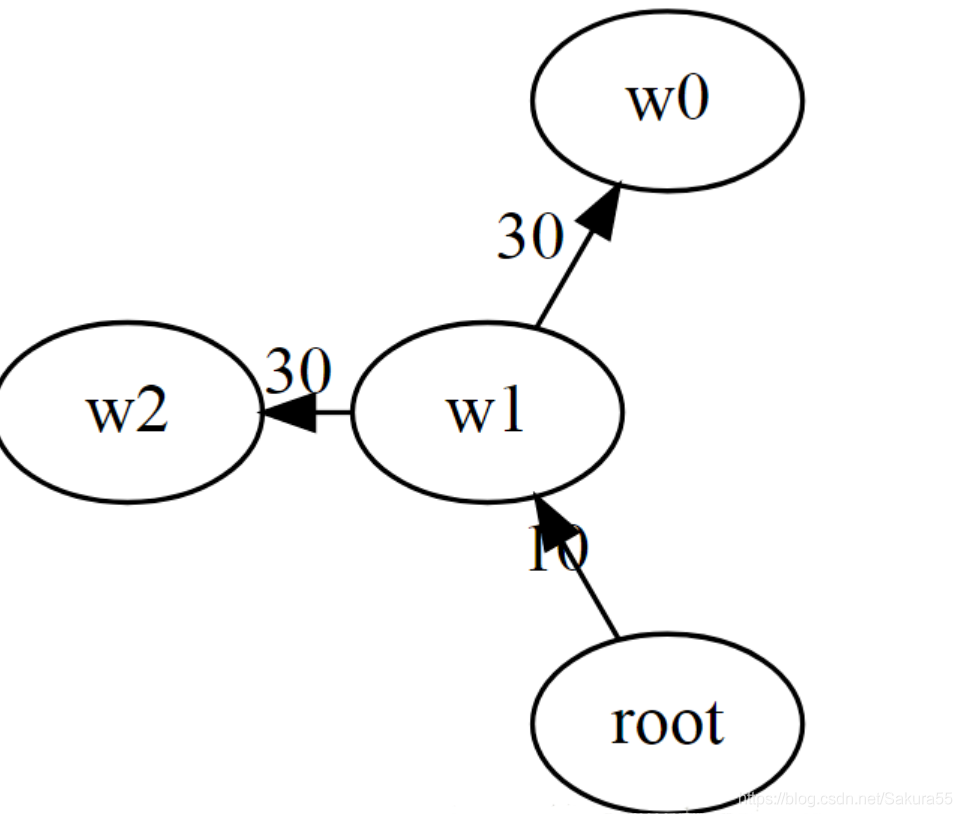
代表Chu-Liu/Edmonds Algorithm算法流程
Chu-Liu/Edmonds Algorithm
1、如果有进入根的弧,则将其全部丢弃。对于除根以外的每个节点,选择权重最大的输入弧,让所选的n-1个弧成为集合s;
2、如果上述集合s中没有形成循环,则该集合是一个最大生成树,算法结束。否则,进行下一步;
3、如果上述集合s中包含循环,将循环中的节点看作一个节点c,并留下该节点c指向其他节点权重最大的弧,丢弃其它;
4、如果上述集合s中包含循环,将循环中的节点看作一个节点c,并根据以下内容修改从循环外的某个节点(i)进入循环中的节点(j)的弧的权重:
s(i,c)=s(i,j) – (s(a(j),j) + s©
其中s(i,j)表示节点i到节点j弧的权重, (s(a(j),j)表示循环c中到节点j的弧的权重,s©表示循环中各个弧权重的总和;
5、对于每个循环,选择具有最大权重的输入弧,并用新的权重替换原来弧的权重;
6、将步骤5得到的有向图返回步骤2.
该算法的关键思想是找到具有最大权重以消除循环c。
三、基于转移的依存句法分析
转移系统:初始状态—(状态转移动作)—>n个中间状态—-(状态转移动作)—->接受状态,将一个状态表示为<栈,缓存,已分析好的依存弧>
初始状态:栈中只有伪词w0,整个词语都在缓存中,没有依存弧
接受状态:栈中只有伪词,缓存清空,所有的依存弧
状态转移动作:移进,左规约,右规约。
移进表示将缓存中的第一个词移入栈中
栈中词从左往右排序【…,X3,X2,X1】,栈顶词为X1,后进先出
~~~~~~~~
左规约表示栈顶的第一个词与第二个词产生了左指向依存弧,即第一个词依存于第二个词,将栈顶第二个词(核心词)下栈
~~~~~~~~
右规约表示栈顶第一个词与第二个词产生了右指向依存弧,即第二个次依存于第一个词,将栈顶第一个词下栈
典型的算法:CRF++算法,具体详见:https://www.jianshu.com/p/c66334711754
以及如下算法结构:
Transition-based parsing(基于贪心决策动作拼装句法树)
~~~~~~~~
下面那将对学习中遇到的PCFG、Lexical PCFG及主流的依存句法分析方法—Transition-based Parsing(基于贪心决策动作拼装句法树)做一整理。
~~~~~~
贪心解码算法:要学习一个分类器,其输入为一个状态,输出为该状态下最可能的动作。贪心算法存在错误级联问题,即前期动作选择错误会导致后面更多的错误,且无法回溯。
~~~~~~
通过特征来表示状态,通过分类器判断要采取的转移动作。如栈顶的词、词性,缓存中的第一个词、词性,已生成部分依存树的最左或最右词,这些又被称为核心特征。为了提高分类的精度,还需要人工定义各种组合特征。如Zhang and Nivre (2011) 曾给出了一套准优化的特征及特征组合模板,共有20种核心特征,72种组合特征。
~~~~~~
柱搜索算法:使用agenda来组织搜索过程,保存了相同数目的K个状态,遍历所有状态选择分值最大的K个,形成新的K个状态,更新agenda。
柱搜索算法举例
~~~~~~
首先需要确定一个Beam Size,这里设置为2,意思是每个word后面的分支考虑概率最大的那两个words。比如下面的例子,从下往上首先分成A、B两个words,然后继续往上传播,句子变成是AA/AB/BA/BB这四种情况(绿色虚线)。考虑到Beam Size=2,选择概率最大的两个,假设是AB/BA(橙色大箭头)。然后以选择的AB/BA继续向上传播,又出现了四种情况ABA/ABB/BBA/BBB,依然是选择综合概率最大的两个ABB/BBB。以此类推,直至句子结束。只要可以调整好Beam Size,就能够使用最小的计算量,得到最优的结果。

PCFG(概率上下文无关文法)
~~~~~~~~
PCFG(Probabilistic Context Free Grammar),概率上下文无关文法,或称为SCFG(Stochastic Context Free Grammar),随机上下文无关文法。
~~~~~~~~
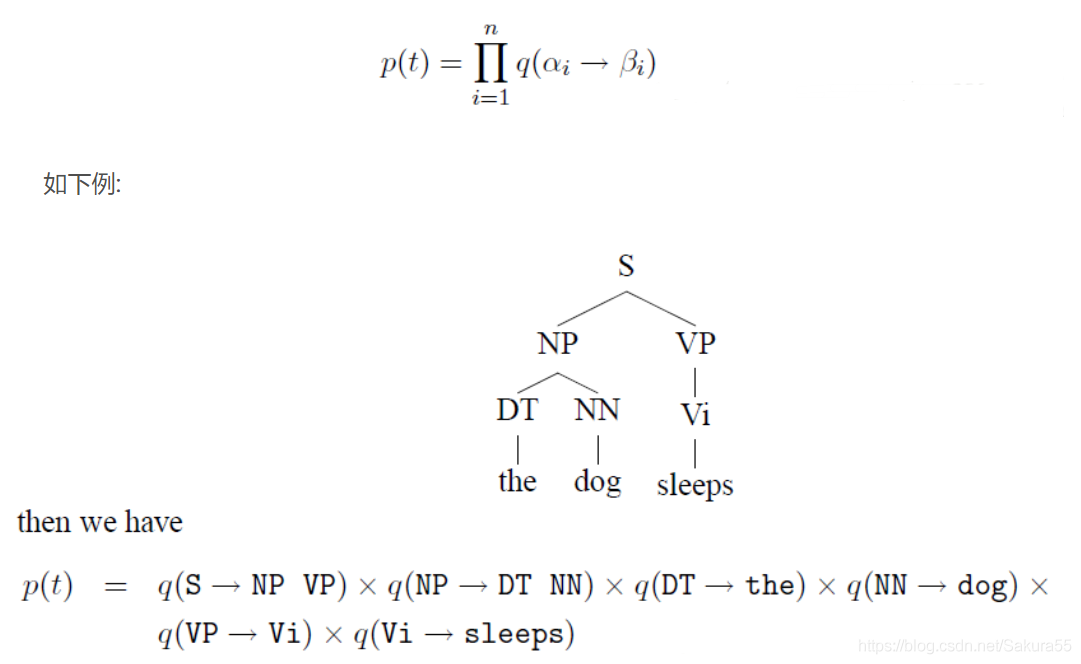
结合上下文无关文法(CFG)中最左派生规则(left-most derivations)和不同的rules概率,计算所有可能的树结构概率,取最大值对应的树作为该句子的句法分析结果。
~~~~~~~~
(The key idea in probabilistic context-free grammars(PCFG) is to extend our definition to give a probability over possible derivations.)
~~~~~~~~
对最左派生规则的每一步都添加概率,这样整棵句法分析树的概率就是所有这些“独立”的概率的乘积。
为了方便计算,在PCFG中添加对rules的限制(Chomsky Normal Form):

问题是如何寻找概率最大的句法分析树结构?
1. 暴力搜索(Brute-force method)
暴力搜索Brute-force method(根据PCFG的rules,暴力计算不同句法结构的概率,选择概率最高的句法分析树作为结论),缺陷在于随着句子的增长,计算量指数增长:
~~~~~~
2. 动态规划(dynamic programming)CKY算法

详细算法见:https://blog.csdn.net/qq_28031525/article/details/79187080
Lexical PCFG(基于词典的PCFG)
首先考虑PCFG的缺陷:
1、在PCFG中,词的选择具有很强的独立性假设,词的选择完全依赖于当前的词性(POS),而条件独立于与其他所有句法树上的结构(More formally, the choice of each word in the string is conditionally independent of the entire tree,once we have conditioned on the POS directly above the word),而这正是很多歧义问题的原因。下例中,’IBM’的选择仅仅与’NP’有关,而与其他树上的结构完全无关。

2、对结构偏好(structure preference)不敏感
对于存在歧义的两个句子,具有完全相同的树形结构,但是由于缺乏词汇的信息,进而缺少结构依赖的信息,使得最终不同树形结构计算的概率完全相同。
如下例中:同一句话,两个完全不同的句法分析结构,由于采用了相同的rules,因此概率计算最终也会相同。
四、基于深度学习技术的贪心解码算法
~~~~~~~
CMU的Dyer等人 (2015) 提出使用长短时记忆循环神经网络(LSTM-RNN)来表示栈和缓存,并使用递归神经网络来表示部分依存树,另外还额外地使用一个LSTM表示历史的转移动作序列,最终将这些网络输出的向量进行拼接来表示一个状态,从而达到无需进行任何人工特征提取和组合的操作,即可更完备地表示状态的目的。
Ballesteros等人 (2015) 后来又进一步拓展他们自己上述的工作,使用字符序列的双向LSTM来表示单词,从而更好地对单词进行泛化表示,克服低频词或未登录词表示不精确等问题。Dyer等人的一系列工作虽然无需人工提取任何特征,但是网络过于复杂,不便于学习。Kiperwasser and Goldberg (2016) 提出了一个非常简单的特征表示和学习方法,他们使用双向LSTM来对句子中的每个词进行表示,然后将该词表示作为依存句法分析系统的输入,在仅使用少量核心特征的情况下,取得了较高的准确率。