协程的原理和应用
协程的原理
协程(coroutine)跟具有操作系统概念的线程不一样,实际上协程就是类函数一样的程序组件,你可以在一个线程里面轻松创建数十万个协程,就像数十万次函数调用一样。只不过函数只有一个调用入口起始点,返回之后就结束了,而协程入口既可以是起始点,又可以从上一个返回点继续执行,也就是说协程之间可以通过 yield 方式转移执行权,对称(symmetric)、平级地调用对方,而不是像函数那样上下级调用关系。当然 协程也可以模拟函数那样实现上下级调用关系,这就叫非对称协程(asymmetric coroutines)。
我们举一个例子来看看一种对称协程调用场景,大家最熟悉的“生产者-消费者”事件驱动模型,一个协程负责生产产品并将它们加入队列,另一个负责从队列中取出产品并使用它。为了提高效率,你想一次增加或删除多个产品。伪代码可以是这样的:
# producer coroutine loop while queue is not full create some new items add the items to queue yield to consumer # consumer coroutine loop while queue is not empty remove some items from queue use the items yield to producer
如果用多线程实现生产者-消费者模式,线程之间需要使用同步机制来避免产生全局资源的竟态,这就不可避免产生了休眠、调度、切换上下文一类的系统开销,而且线程调度还会产生时序上的不确定性。
而对于协程来说,“挂起”的概念只不过是转让代码执行权并调用另外的协程,待到转让的协程告一段落后重新得到调用并从挂起点“唤醒”,这种协程间的调用是逻辑上可控的,时序上确定的,可谓一切尽在掌握中。
当今一些具备协程语义的语言,比较重量级的如C#、erlang、golang,以及轻量级的python、lua、javascript、ruby,还有函数式的scala、scheme等。相比之下,作为原生态语言的 C 反而处于尴尬的地位,原因在于 C 依赖于一种叫做栈帧的例程调用,例程内部的状态量和返回值都保留在堆栈上,这意味着生产者和消费者相互之间无法实现平级调用,当然你可以改写成把生产者作为主例程然后将产品作为传递参数调用消费者例程,这样的代码写起来费力不讨好而且看起来会很难受,特别当协程数目达到十万数量级,这种写法就过于僵化了。
如果将每个协程的上下文(比如程序计数器)保存在其它地方而不是堆栈上,协程之间相互调用时,被调用的协程只要从堆栈以外的地方恢复上次出让点之前的上下文即可,这有点类似于 CPU 的上下文切换,C 标准库给我们提供了两种协程调度原语:一种是 setjmp/longjmp,另一种是 ucontext 组件,它们内部(当然是用汇编语言)实现了协程的上下文切换,相较之下前者在应用上会产生相当的不确定性(比如不好封装,具体说明参考联机文档),所以后者应用更广泛一些,网上绝大多数 C 协程库也是基于 ucontext 组件实现的。
我们知道 python 的 yield 语义功能类似于一种迭代生成器,函数会保留上次的调用状态,并在下次调用时会从上个返回点继续执行,例如:
def cols(): for i in range(10): yield i g=cols() for k in g: print(k)
下面看看C语言的yiled语义是如何实现的:
int function(void) { static int i, state = 0; switch (state) { case 0: goto LABEL0; case 1: goto LABEL1; } LABEL0: /* start of function */ for (i = 0; i < 10; i++) { state = 1; /* so we will come back to LABEL1 */ return i; LABEL1:; /* resume control straight after the return */ } }
这是利用了static变量和goto跳转来实现的,如果不用goto,而是直接利用switch的跳转功能:
int function(void) { static int i, state = 0; switch (state) { case 0: /* start of function */ for (i = 0; i < 10; i++) { state = 1; /* so we will come back to "case 1" */ return i; case 1:; /* resume control straight after the return */ } } }
我们还可以用 __LINE__ 宏使其更加一般化:
int function(void) { static int i, state = 0; switch (state) { case 0: /* start of function */ for (i = 0; i < 10; i++) { state = __LINE__ + 2; /* so we will come back to "case __LINE__" */ return i; case __LINE__:; /* resume control straight after the return */ } } }
这样一来我们可以用宏提炼出一种范式,封装成组件:
#define Begin() static int state=0; switch(state) { case 0: #define Yield(x) do { state=__LINE__; return x; case __LINE__:; } while (0) #define End() } int function(void) { static int i; Begin(); for (i = 0; i < 10; i++) Yield(i); End(); }
这种协程实现方法有个使用上的局限,就是协程调度状态的保存依赖于 static 变量,而不是堆栈上的局部变量,实际上也无法用局部变量(堆栈)来保存状态,这就使得代码不具备可重入性和多线程应用。如果将局部变量包装成函数参数传入的一个虚构的上下文结构体指针,然后用动态分配的堆来“模拟”堆栈,解决了线程可重入问题。但这样一来反而有损代码清晰,比如所有局部变量都要写成对象成员的引用方式,特别是局部变量很多的时候很麻烦,再比如宏定义 malloc/free 的玩法过于托大,不易控制。
既然协程本身是一种单线程的方案,那么我们应该假定应用环境是单线程的,不存在代码重入问题,所以我们可以大胆地使用 static 变量,维持代码的简洁和可读性。事实上我们也不应该在多线程环境下考虑使用这么简陋的协程,非要用的话,前面提到 glibc 的 ucontext 组件也是一种可行的替代方案,它提供了一种协程私有堆栈的上下文,当然这种用法在跨线程上也并非没有限制,请仔细阅读其文档。
协程的并发应用
协程就是在单线程中使用同步编程思想来实现异步的处理流程,从而实现单线程能并发处理成百上千个请求,而且每个请求的处理过程是线性的,没有使用晦涩难懂的callback机制来衔接处理流程。
基于事件驱动状态机
传统的网络服务器(如nginx、squid等)都采用了 EDSM (event-driven state machine,事件驱动状态机) 机制并发处理请求,这是一种异步处理的方式,通过使用callback 方法避免阻塞线程。
EDSM最常见的方式就是I/O事件的异步回调。基本上都会有一个叫做dispatcher的单线程主循环(又叫event loop),用户通过向dispatcher注册回调函数(又叫event handler)来实现异步通知,从而不必在原地空耗资源干等。在dispatcher主循环中通过select()/epoll()等系统调用来等待各种I/O事件的发生,当内核检测到事件触发并且数据可达或可用时,select()/epoll()会返回从而使dispatcher调用相应的回调函数来对处理用户的请求。
整个过程都是单线程的。这种处理本质上就是将一堆相互独立(disjoint)的回调实现同步控制,就像串联在一个顺序链表上。如下图,黑色的双箭头表示I/O事件复用,回调是个筐,里面装着对各种请求的处理(当然不是每个请求都有回调,一个请求也可以对应不同的回调),每个回调被串联起来由dispatcher激活。这里请求等价于thread的概念(不是操作系统的线程),只不过“上下文切换”(context switch)发生在每个回调结束之时(假设不同请求对应不同回调),注册下一个回调以待事件触发时恢复其它请求的处理。至于dispatcher的执行状态(execute state)可作为回调函数的参数保存和传递
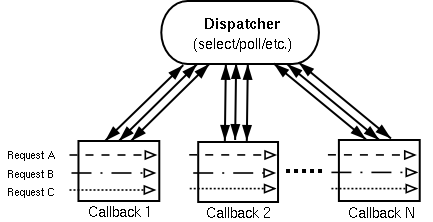
异步回调的缺陷在于难以实现和扩展,虽然已经有libevent这样的通用库,以及其它actor/reacotor的设计模式及其框架,但正如Dean Gaudet(Apache开发者)所说:“其内在的复杂性——将线性思维分解成一堆回调的负担(breaking up linear thought into a bucketload of callbacks)——仍然存在”。从上图可见,回调之间请求例程不是连续的,比如回调之间的切换会打断部分请求,又比如有新的请求需要重新注册。
协程本质上仍然是基于EDSM模型,但旨在取代传统的异步回调方式。协程将请求抽象为thread概念以更接近自然编程模式(所谓的linear thought吧,就像操作系统的线程之间切换那样自然)。

下面介绍一种协程的实现方案:State Threads库。
ST库
ST (State Threads) 库提供了一种高性能、可扩展服务器(比如web server、proxy server、mail agent等)的实现方案。
ST 库简化了multi-threading编程范式,每个请求对应一个线程,注意这里的线程其实是一种coroutine(协程),跟pthread那种内核线程不是一回事。
这里稍微解释一下ST调度工作原理,ST运行环境维护了四种队列,分别是IOQ(等待队列)、RUNQ(运行队列)、SLEEPQ(超时队列)以及ZOMBIEQ。当每个thread处于不同队列中对应不同的状态(ST顾名思义所谓thread状态机)。比如polling请求的时候,当前thread就加入IOQ表示等待事件(如果有timeout同时会被放到SLEEPQ中),当事件触发时,thread就从IOQ(如果有timeout同时会从SLEEPQ)移除并转移到RUNQ等待被调度,成为当前的running thread,相当于操作系统的就绪队列,跟传统EDSM对应起来就是注册回调以及激活回调。再比如模拟同步控制wait/sleep/lock的时候,当前thread会被放入SLEEPQ,直到被唤醒或者超时再次进入RUNQ以待调度。
ST的调度具备性能与内存双重优点:在性能上,ST实现自己的setjmp/longjmp来模拟调度,无任何系统开销,并且context(就是jmp_buf)针对不同平台和架构用底层语言实现的,可移植性媲美libc。下面放一段代码解释一下调度实现:
/* * Switch away from the current thread context by saving its state * and calling the thread scheduler */ #define _ST_SWITCH_CONTEXT(_thread) \ ST_BEGIN_MACRO \ if (!MD_SETJMP((_thread)->context)) { \ _st_vp_schedule(); \ } \ ST_END_MACRO /* * Restore a thread context that was saved by _ST_SWITCH_CONTEXT * or initialized by _ST_INIT_CONTEXT */ #define _ST_RESTORE_CONTEXT(_thread) \ ST_BEGIN_MACRO \ _ST_SET_CURRENT_THREAD(_thread); \ MD_LONGJMP((_thread)->context, 1); \ ST_END_MACRO void _st_vp_schedule(void) { _st_thread_t *thread; if (_ST_RUNQ.next != &_ST_RUNQ) { /* Pull thread off of the run queue */ thread = _ST_THREAD_PTR(_ST_RUNQ.next); _ST_DEL_RUNQ(thread); } else { /* If there are no threads to run, switch to the idle thread */ thread = _st_this_vp.idle_thread; } ST_ASSERT(thread->state == _ST_ST_RUNNABLE); /* Resume the thread */ thread->state = _ST_ST_RUNNING; _ST_RESTORE_CONTEXT(thread); }
如果你熟悉setjmp/longjmp的用法,你就知道当前thread在调用MD_SETJMP将现场上下文保存在jmp_buf中并返回返回0,然后自己调用_st_vp_schedule()将自己调度出去。调度器先从RUNQ上找,如果队列为空就找idle thread,这是在整个ST初始化时创建的一个特殊thread,然后将当前线程设为自己,再调用MD_LONGJMP切换到其上次调用MD_SETJMP的地方,从thread->context恢复现场并返回1,该thread就接着往下执行了。整个过程就同EDSM一样发生在操作系统单线程下,所以没有任何系统开销与阻塞。
其实真正的阻塞是发生在等待I/O事件复用上,也就是select()/epoll(),这是整个ST唯一的系统调用。ST当前的状态是,整个环境处于空闲状态,所有threads的请求处理都已经完成,也就是RUNQ为空。这时在_st_idle_thread_start维护了一个主循环(类似于event loop),主要负责三种任务:1.对IOQ所有thread进行I/O复用检测;2.对SLEEPQ进行超时检查;3.将idle thread调度出去,代码如下:
void *_st_idle_thread_start(void *arg) { _st_thread_t *me = _ST_CURRENT_THREAD(); while (_st_active_count > 0) { /* Idle vp till I/O is ready or the smallest timeout expired */ _ST_VP_IDLE(); /* Check sleep queue for expired threads */ _st_vp_check_clock(); me->state = _ST_ST_RUNNABLE; _ST_SWITCH_CONTEXT(me); } /* No more threads */ exit(0); /* NOTREACHED */ return NULL; }
这里的me就是idle thread,因为_st_idle_thread_start就是创建idle thread的启动点,每从上次_ST_SWITCH_CONTEXT()切换回来的时候,接着在_ST_VP_IDLE()里轮询I/O事件的发生,一旦检测到发生了别的thread事件或者SLEEPQ里面发生超时,再用_ST_SWITCH_CONTEXT()把自己切换出去,如果此时RUNQ中非空的话就切换到队列第一个thread。这里主循环是不会退出的。
在内存方面,ST的执行状态作为局部变量保存在栈上,而不是像回调需要动态分配,用户可能分别这样使用thread模式和callback模式:
/* thread land */ int foo() { int local1; int local2; do_some_io(); } /* callback land */ struct foo_data { int local1; int local2; }; void foo_cb(void *arg) { struct foo_data *locals = arg; ... } void foo() { struct foo_data *locals = malloc(sizeof(struct foo_data)); register(foo_cb, locals); }
另外有两点要注意,一是ST的thread是无优先级的非抢占式调度,也就是说ST基于EDSM的,每个thread都是事件或数据驱动,迟早会把自己调度出去,而且调度点是明确的,并非按时间片来的,从而简化了thread管理;二是ST会忽略所有信号处理,在_st_io_init中会把sigact.sa_handler设为SIG_IGN,这样做是因为将thread资源最小化,避免了signal mask及其系统调用(在ucontext上是避免不了的)。但这并不意味着ST就不能处理信号,实际上ST建议将信号写入pipe的方式转化为普通I/O事件处理,示例详见这里。
multi-threading编程范式
Posix Thread(以下简称PThread)是个通用的线程库,它是将用户级线程(thread)同内核执行对象(kernel execution entity,有些书又叫lightweight processes)做了1:1或m:n映射,从而实现multi-threading模式。例如,Apache服务器就是使用了PThread来实现并发请求的处理,每个线程处理一个请求,线程是以同步、阻塞的方式处理请求的,在线程的当前请求处理完成之前不会接受其它请求。
而ST是单线程(n:1映射),它的thread实际上就是协程(coroutine)。通常的网络应用上,多线程范式绕不开操作系统,但在某些特定的服务器领域,线程间的共享资源会带来额外复杂度,锁、竞态、并发、文件句柄、全局变量、管道、信号等,面对这些Pthread的灵活性会大打折扣。而ST的调度是精确的,它只会在明确的I/O和同步函数调用点上发生上下文切换,这正是协程的特性,如此一来ST就不需要互斥保护了,进而也可以放心使用任何静态变量和不可重入库函数了(这在同样作为协程的Protothreads里是不允许的,因为那是stack-less的,无法保存上下文),极大的简化了编程和调试同时增加了性能。
这里顺便说一句,C语言实现的协程据我所知只有三种方式:
1、Protothread为代表利用switch-case语义跳转;
2、以ST为代表不依赖libc的setjmp/longjmp上下文切换;
3、依赖glibc的ucontext接口(云风的coroutine);
其中,Protothread最轻,但受限最大,ucontext耗资源性能慢,目前看来ST是最好使的。
总结
ST的核心思想就是利用multi-threading的简单优雅范式胜过传统异步回调的复杂晦涩实现,又利用EDSM的性能和解耦架构避免了multi-threading在系统上的开销和暗礁。
ST的主要限制在于,应用程序所有I/O操作必须使用ST提供的API,因为只有这样thread才能被调度器管理,并且避免阻塞。
其实最后在罗嗦一句,ngx_lua模块也是利用coroutine简化了Nginx流程的处理流程,每个请求对应一个lua coroutine,从而在coroutine内部完全使用线性的方式处理请求,避免了使用回调的异步写法;
参考文档:
http://state-threads.sourceforge.net/
http://state-threads.sourceforge.net/docs/faq.html
http://coolshell.cn/articles/12012.html
http://coolshell.cn/articles/10975.html