摄影中最重要的是光,找光、等光、拍光,而在室外录音录像中,则是要等声音。确切点说,是等噪音过去,尤其是瞬时噪声,飞机呼啸而过、学校的下课铃、汽车的鸣笛等等。

这些,就需要通过 AI 算法进行智能降噪处理。
AI 降噪可以通过模型训练的方式,识别出需要过滤掉的瞬时噪声。
6 月 9 日的融云 RTC · 进阶实战高手课中,融云音频算法工程师从降噪技术、AI 降噪技术、融云 AI 降噪探索实践等方面对 AI 降噪相关技术进行了全面分享。
本文将对课件内容进行梳理展示,欢迎收藏转发~
【融云全球互联网通信云】后台回复【AI降噪】获取完整课件
降噪技术
噪音其实是一个相对概念,不同场景对有用声音与噪音的定义并不一致。
比如在一个有背景音乐的环境中通话,背景音乐就是噪音,需要用降噪技术去除掉。而在直播中,主播唱歌的背景音乐就成了一个有用信号,不仅不能去掉,还需要保证无失真地保留。
因此,我们需要根据不同场景有针对性地设计降噪方案。
降噪技术发展多年,每个阶段都会有一些典型的算法和重要的技术突破。比如早期的线性滤波法、谱减法,后来的统计模型算法、子空间算法。
近些年,基于深度学习的降噪算法得到快速发展,也就是本文所分享的 AI 降噪算法。主要是基于幅度谱的深度学习算法,还有复数谱的深度学习算法,以及后来的基于时域信号的深度学习算法。
 (不同阶段的主要降噪技术)
(不同阶段的主要降噪技术)
传统算法,是由研究者总结噪音规律来建模,继而实施背景噪音处理,主要包括线性滤波法、谱减法、统计模型算法以及子空间算法。
线性滤波法,就是用高通滤波器等对已知频带的信号进行滤除。比如有个 50 赫兹的干扰,我们用高通滤波器,截止频率在 50 赫兹以上,就可以把 50 赫兹的干扰信号滤除掉。
谱减法,记录非语音段的一个噪音能量,然后用含噪语音谱减去噪音谱,就得到纯净语音。
统计模型算法,基于统计的方法计算出各频点的语音和噪音分量。
子空间算法,将含噪语音映射到信号子空间和噪音子空间,通过消除噪音子空间成分,保留有用的信号子空间成分,来估计真正有用的语音信号。
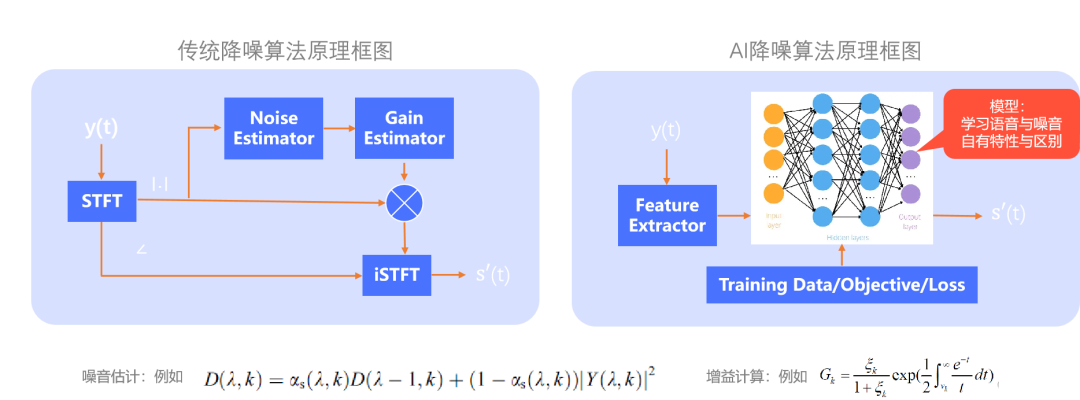 (降噪算法原理框图)
(降噪算法原理框图)
上图(左)展示了传统降噪方法的典型原理。
信号 y(t) 经过短时傅里叶变换后得到含噪语音幅度谱与相位谱,传统方法通常重点关注语音信号的幅度谱,将幅度谱信息经 Noise Estimator(噪音估计模块)对噪音进行估计,然后经过 Gain Estimator 进行最终 Gain 值计算,将含噪语音的幅度谱与 Gain 值相乘得到最终的增强语音幅度谱,再将其与含噪语音的相位谱结合,进行 iSTFT,从而得到增强语音。
由于噪音估计模块通常是经过平滑递归来计算噪音的估计值,非平稳噪音就很难被准确估计。因此,我们需要引入 AI 降噪进一步提升降噪性能。
上图(右)是基于 AI 降噪的原理图,将含噪语音经过特征提取输入到训练好的神经网络,得到去噪后的增强语音。
其本质是利用神经网络模型学习语音与噪音各自的特性与区别,从而去除噪音保留语音。
AI 降噪
AI 降噪主要研究三个方面。
首先是模型 Model,从最早期的 DNN 网络发展到后来的 RNN 网络,再到后来的 CNN 网络、GAN 网络及近期的 Transformer 等,AI 降噪模型的发展是随深度学习模型的发展而发展的。
这些神经网络模型不只在 AI 降噪中使用,还广泛应用在语音识别、语音合成、图像处理、自然语言处理等领域。
然后是训练目标 Training Objective,总的来说分为两大类:Mask 类和 Mapping 类。
Mask 主要有:理想二值掩蔽 IBM、理想比值掩蔽 IRM、频谱幅度掩蔽 SMM,这些都只用到了幅度信息;后来的相位敏感掩蔽 PSM,是第一个利用相位信息进行相位估计的掩蔽训练目标;之后的复数比值掩蔽 CRM,同时增强实部和虚部。
Mapping 方法,最先是将输入语音映射到幅度谱,相当于只针对语音的幅度谱进行恢复,再到后来的复数谱,利用语音信号的复数谱信息进行映射,然后就是直接映射语音波形,不做时频变换。
最后是损失函数 Loss Function。
最早出现的是最小均方误差 MSE,计算目标和预测值之间平方差的平均值,还有其变形如 LogMSE 等,计算目标和预测值之间在对数域下平方差的平均值。
被广泛使用的还有 SDR 或 SiSDR 等。
无论 MSE 还是 SDR 等都无法直接反映语音听觉质量。
语音通常用 PESQ、STOI 等来评估质量,所以利用 PESQ 和 STOI 两个指标来作为 Loss 计算,更能准确反映语音质量与可懂度等。因为 PESQ 不是连续可导的,实际中会使用 PMSQE 来进行计算。
基于不同训练目标的思路,AI 降噪主要有以下类型。
Mask 类
把含噪语音信号变换到时频域后,通过计算得到含噪语音的 Mask 值来与含噪语音时频谱相乘,从而在各频带上达到分别进行噪音抑制的效果,得到增强语音。
 (Mask 类方法)
(Mask 类方法)
训练过程如上图所示,将含噪语音经过 STFT 得到含噪语音的幅度谱 → 将幅度谱经过深度学习网络后得到一个 Mask 值 → 将此 Mask 值与理想 Mask 值输入到训练 Loss Function 模块得到 Loss 值 → 指导网络更新,不断迭代出训练好的模型。
推断流程是将含噪语音同样进行 STFT 变换,得到幅度谱与相位谱;同样将幅度谱信息经过训练好的网络处理后得到 Mask 值,并将 Mask 值与含噪语音的幅度谱相乘,从而得到去噪语音的幅度谱;再将其与相位信息结合通过 iSTFT 处理得到去噪语音的时域波形。
Mask 类是出现最早的方法,从其原理上看,与传统方法中用到的 Gain 值作用相似,只不过这个 Mask 是通过模型推断出的结果。类比于传统方法的 Gain 值,Mask 同样会做范围限制,以保证在一个合理范围,进而在有效降噪的同时,确保较小的语音失真度。
Mapping 类
Mapping 类方法,不用得到中间值 Mask 再去计算去噪语音谱,而是直接利用深度学习网络预测语音谱。
但这种方法也有两面性,虽然模型可以直接输出去噪语音谱,但其输出异常的情况会变多,尤其是面对模型未见过的场景。
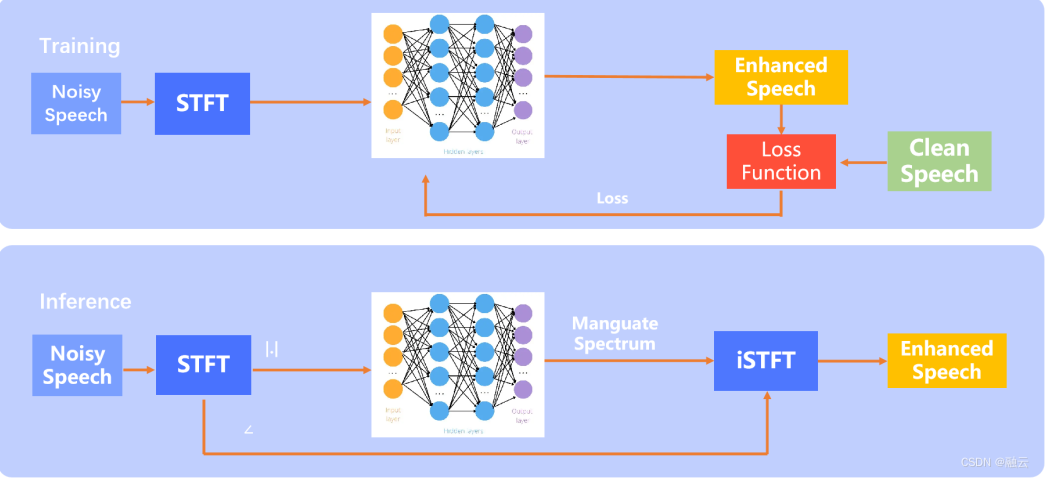 (Mapping 类方法)
(Mapping 类方法)
训练流程如上图,含噪语音经过 STFT 变换后 → 将其幅度谱经过深度学习网络,得到增强语音 → 将增强语音与干净语音输入到 Loss Function 模块,得到 Loss 来指导模型更新,直至收敛。
推断过程是将含噪语音经 STFT 变换后得到幅度谱与相位谱;将幅度谱经训好的模型处理得到去噪语音幅度谱再与含噪语音相位谱结合经 iSTFT 变换得到增强语音。
Mask 与 Mapping 融合
Mask 与 Mapping 融合方法,核心思想同样类似于前面所说的 Mask 的方法求出 Mask 值,但在求 Loss 的时候并不是对 Mask 求 Loss,而是利用 Mask 求出去噪语音,利用去噪语音与干净语音来计算 Loss。
这样做的原因是,Mask 不能完全反映语音与原始语音的拟合程度,同样的 Loss 情况下,Mask 有多种可能性,基于不同 Mask 得到的语音也不是唯一的,因此用语音作为 Loss 的计算会更加贴合真实目标。
 (Mask 与 Mapping 融合方法)
(Mask 与 Mapping 融合方法)
训练流程同样是先对含噪语音进行傅立叶变换,取幅度谱,输入到网络,得到 Mask 值,从而得到增强语音与干净语音一起经过目标计算模块,得到 Loss 值来指导模型更新。
推断流程与 Mask 类的计算流程一致。
复数 Mapping
由于利用幅度谱只是使用了含噪语音的幅度信息,而相位信息未被利用,使得算法有一定瓶颈,增加相位信息的使用,则能更有效地利用全部语音信息,对于噪声抑制更加有效。因此,引入复数谱来进行设计,这里以复数 Mapping 方法进行讲解。
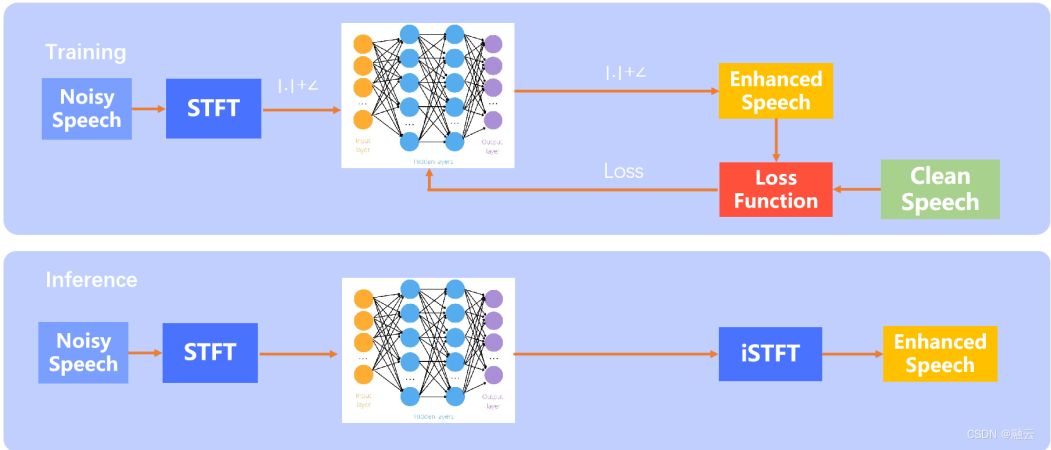 (复数 Mapping 方法)
(复数 Mapping 方法)
训练过程同样将含噪语音进行 STFT 处理,将其经过网络后得到增强语音的复数谱,然后将其与纯净语音输入到 Loss Function 模块,进行 Loss 计算,从而指导模型不断更新,最终收敛。
推断阶段则是含噪语音进行 STFT 处理后,输入到模型,从而得到幅度谱之后进行 iSTFT 处理,得到去噪语音。
Waveform 类
这类方法将几乎所有处理都放入模型,让模型有很大的灵活度来做学习。
之前的方法都是在时频域处理,而 Waveform 类方法则通过使用如 CNN 网络等对数据进行分解与合成,使得信号变化到模型收敛的域中;也正是因为这种灵活度,我们对其控制更少,也更容易碰到一些异常 case。
 (Waveform 类方法)
(Waveform 类方法)
其训练和推断的过程如上图所示。值得一提的是,在实际方法选择中,还是要根据场景与需求选择合适的方法来进行算法设计与调优。
传统降噪 VS AI 降噪
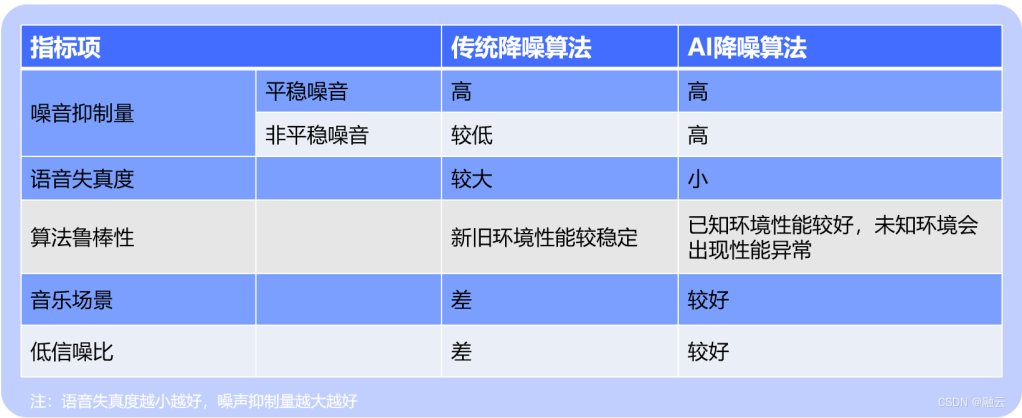 (传统降噪与 AI 降噪对比)
(传统降噪与 AI 降噪对比)
噪音抑制量
对于平稳噪声,传统降噪算法和 AI 降噪算法均能发挥出不错的性能效果。
但对于非平稳噪音,无论是连续非平稳还是瞬态非平稳噪音,传统方法的效果都不是很好,尤其在瞬态噪音的处理上,性能表现最差。因为非平稳噪音多种多样,规律很难总结,传统方法很难对非平稳噪音建模。
在这方面,AI 降噪的方法可以引入大量非平稳噪音来让模型学习其特征,从而达到不错的效果。
语音失真度
传统降噪方法很难准确估计噪音量,一旦过多估计就会造成语音失真。
而 AI 降噪算法,主要通过在训练集中引入各种各样的噪音,来使得模型相对准确地估计出语音与噪音,通常情况下其语音失真度相对较小。
算法鲁棒性
传统方法在新旧环境中性能相对稳定,且其算法复杂度不是很高,所以经典传统降噪方法至今都依然被一些场景采用。
AI 降噪算法在已知环境性能突出,这是传统方法无比匹敌的,而 AI 降噪在未知环境中会有一定概率发生不理想情况。但相信随着 AI 降噪技术的发展,其算法鲁棒性会越来越好。
音乐场景
直接使用传统降噪算法会对音乐信号造成严重损伤,因为它噪音跟踪的原理无法很好地区分音乐信号与背景噪音;而 AI 降噪技术则可以通过训练数据的扩展,让其在模型中处理过音乐噪音的数据,进而具备对音乐与噪音的区分能力,从而取得不错的效果。
低信噪比
传统降噪算法很难准确估计噪音等级,更容易造成较高的语音失真度与更多的残余噪音,而 AI 降噪可以通过引入包括低信噪比数据的多种信噪比数据来提升模型对低信噪比场景的效果。
 (含躁语音)
(含躁语音)
如上图所示,这是一个低信噪比+非平稳噪音的效果对比。
从含噪语音的语谱图可以看出,低频的语音谱很难被清晰观测,信噪比很低。其音质可以听到明显的噪音,语音有些听不太清楚。
 (传统降噪效果)
(传统降噪效果)
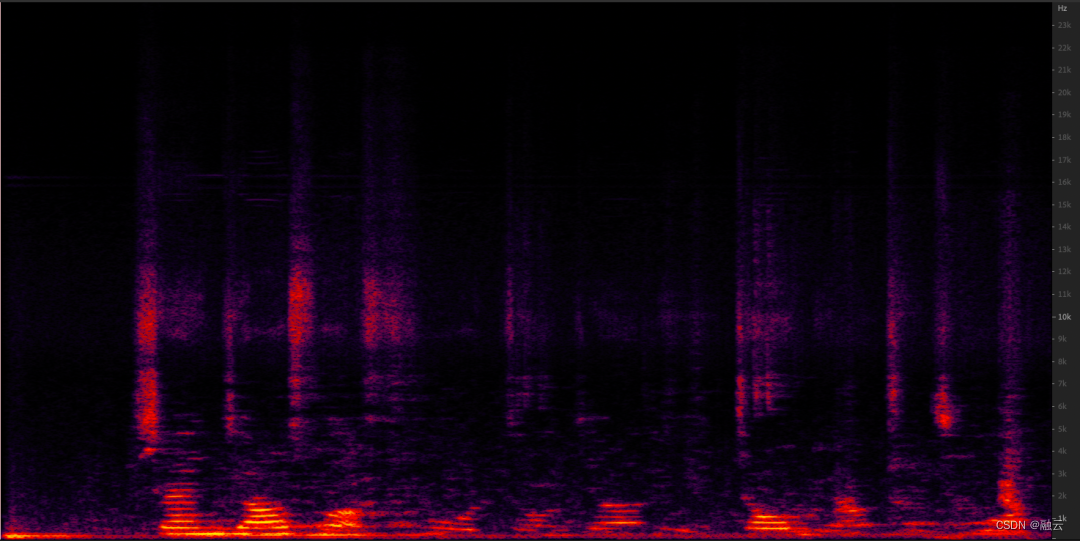 (AI 降噪的效果)
(AI 降噪的效果)
AI 降噪处理后的语谱图不会明显看到残余噪音,音质效果比传统降噪算法效果好。
那在直播音乐场景,传统降噪和 AI 降噪算法的效果如何呢?
下面是正常环境下语音+音乐的原始音频。
 (原始音频)
(原始音频)
从语谱图中可以看出连续存在能量较强的频谱,也是很难区分音乐与人声的。从音频中能感知到音乐与人声。
 (传统降噪效果)
(传统降噪效果)
传统降噪算法的效果,频域有明显损伤,也能够听出音频被损伤的感觉。
那么,AI 降噪算法的效果如何呢?我们看一下融云在这方面的实践。
融云 AI 降噪实践
主要讨论全频带音频直播场景下的 AI 降噪方案。
场景挑战
首先,全频带音频直播场景需要使用 48kHz 采样率最大程度保证人耳对音频的听感无明显下降。而这比学术界 AI 降噪经常使用的 16kHz 采样音频有效频带更宽,对于算法与模型的要求更高,更加复杂。
其次,音乐信号需要保留,音乐信号的特征比语音信号更加复杂,语音主要是以人发声为主,而音乐信号包含的乐器种类繁多,难度升级。
再次,针对音频直播场景可参考的开源 AI 降噪算法非常难找,几乎没有。
最后,由于采样率过高,可用的开源数据集也是相对较少。
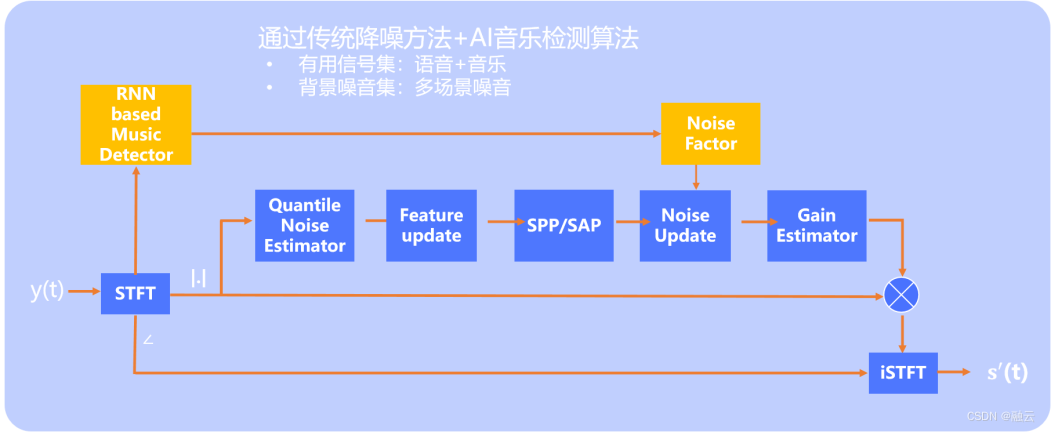 (解决方案一)
(解决方案一)
解决方案一
此方案的核心思想是将传统降噪方案与 AI 音乐检测算法结合,既保持传统降噪的优势,又引入了深度学习的优势,从而使得算法性能达到稳定效果,又在性能上有一个很大的提升。
图中蓝色框是传统降噪算法的原理框图,具体而言,就是含噪语音 y(t) 经过 STFT 处理得到幅度谱,经分位数噪音估计、特征更新、语音出现概率模块得到噪音的更新值,计算出 Gain 值,最后经 iSTFT 变换得到增强音频;
黄色模块对应 AI 音乐检测模块,其中输入语音经 STFT 处理输入到基于 RNN 的音乐检测模块,然后将其检测结果输入到 Noise Factor 模块计算得到指导噪音更新的因子,达到一个能够有效保留音乐信号的噪音估计值,从而有效地保护音乐信号。
在不增加过多计算复杂度的情况下,解决方案一可以有效提高音乐信号的保真度。其中训练网络的数据集,选用语音+音乐信号作为目标信号的数据集,而利用多场景的噪音信号作为背景噪音集。
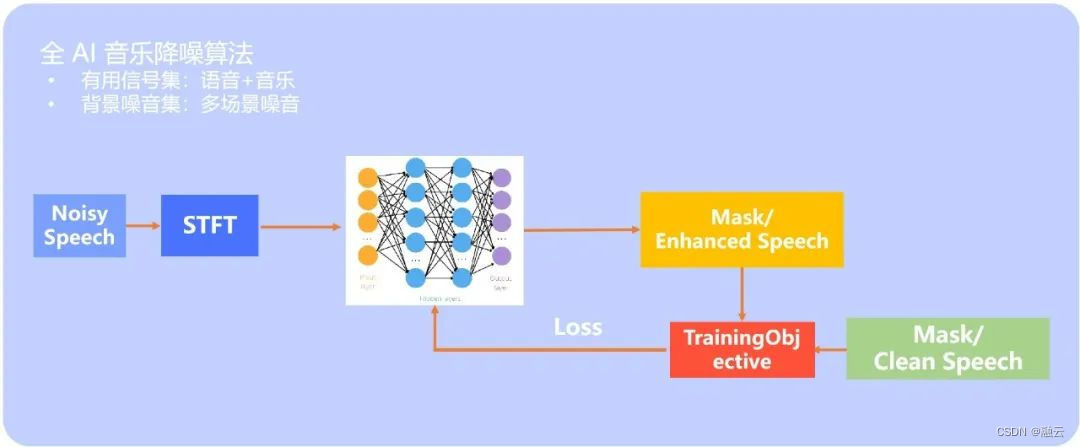 (解决方案二)
(解决方案二)
解决方案二
核心思想是直接利用全 AI 降噪算法来完成设计,大致的原理框图如下:含噪数据经过 STFT 变换后,经过深度学习网络,然后选用 Mask 或语音作为目标完成模型的训练迭代。
所使用的数据同样需要语音与音乐信号作为目标信号,多种场景的噪音为背景噪音集。
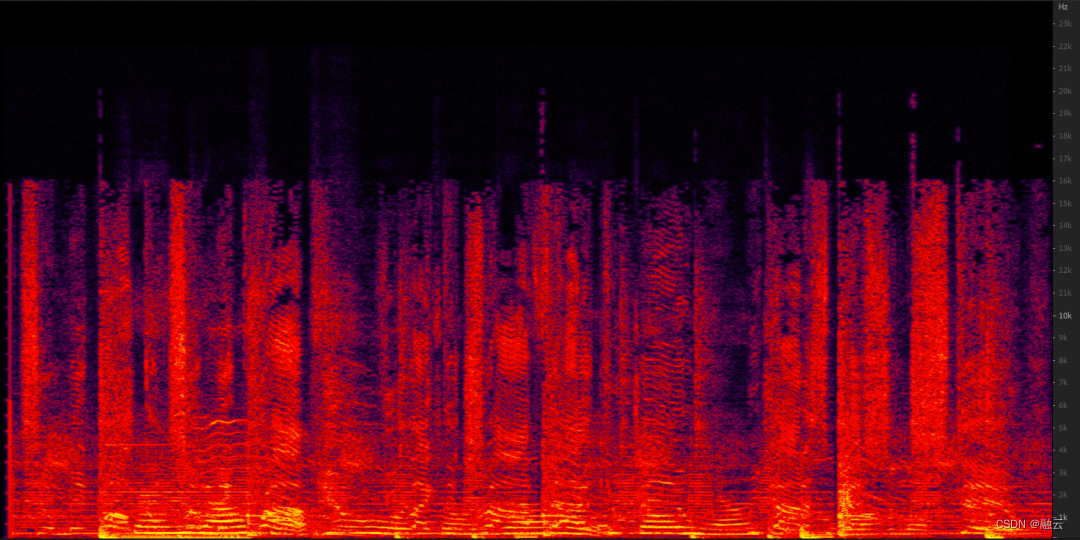 (原始音频)
(原始音频)
 (传统降噪)
(传统降噪)
 (AI 降噪)
(AI 降噪)
结果显示,AI 降噪算法的音乐频谱相比于传统方法在音乐保真度方面更强。
未来,在传统降噪算法与 AI 降噪融合的角度,融云将进一步探索引入深度学习噪音估计模块等方式,进一步发挥传统算法与 AI 算法的优势。
在全 AI 场景,核心网络部分继续针对 RNN、GAN、Transformer 等展开进一步研究,以及不同目标与 Loss 的影响等。
同时,深度学习技术还在持续发展,我们也会不断探索基于新模型的 AI 降噪技术。