(一)什么是哈希算法
哈希算法是属于密码学算发,主要是为了用来验证信息是否完整。
哈希算法也叫散列算法,哈希是 Hash 的直译,通过哈希算法计算得到的值叫哈希值,也叫散列值。
简单地说下哈希算法的作用:就是把任意大小的数据转换成固定长度的数据
哈希表的主要特征:
哈希值固定指的是:通过哈希算法运算得到的哈希值长度是固定的。
哈希算法存在哈希碰撞,这个无法避免,碰撞指的是不同的输入通过哈希算法计算得到相同的哈希值。
因为哈希算法的输入域是一个无限集合,而值域是一个有限集合,将无限集合映射到有限集合,肯定是会冲突、重叠的。就像某公司的马桶少,人多,这肯定就有冲突了(大家应该都知道吧?)。能做的就是加长哈希值长度,但是哈希值长了性能也是有损耗的。(忽略这个类比,我这是强行解释,就想说下这个事儿)类比某公司增加马桶数量,不论马桶成本还是员工成本(员工成本嘿嘿)可能就上来了,所以还是得权衡一下。
还有一种办法就是搞一个优秀的哈希算法,让哈希值分布均匀,这样碰撞就少了其实分布均匀从另一个角度来看就是雪崩效应。雪崩效应是密码学中的专业术语,指的是输入数据发生细微地改变,输出的结果也会天差地别。这样哈希值才分散。
然后单向计算指的是不可逆,简单地说就是经过哈希算法计算之后无法通过哈希值倒推出原始数据。比如一个 1000000 位的数字被哈希成 2 位数,这个原始数据能推出来?数据被抹掉太多了,推不出来的。根据这几个特征,哈希算法就很有用了,很适合判断数据的完整性,或者说作为消息摘要、签名。数据的完整性其实指的就是数据被传输之后没有被篡改,所以重点是判断数据是否被修改过。
比如下文件的时候会有校验和来校验文件。
我随便截了个 oracle 官网下 jdk8 的校验和截图,这个校验和就是通过哈希算法计算而来的哈希值。

作用就是下载完文件,将文件通过对应的哈希算法计算得到哈希值与官网的哈希值作对比,如果不一样那说明文件被人篡改了。因为从雪崩效应可以知道:哪怕文件只修改一点点产生的哈希值就天差地别。并且从无法逆推也可以得知文
了解哈希算法的思想:
1.先来了解一下Hash的基本思路: 设要存储对象的个数为num, 那么我们就用len个内存单元来存储它们(len>=num); 以每个对象ki的关键字为自变量,用一个函数h(ki)来映射出ki的内存地址,也就是ki的下标,将ki对象的元素内容全部存入这个地址中就行了。这个就是Hash的基本思路。 Hash为什么这么想呢?换言之,为什么要用一个函数来映射出它们的地址单元呢? This is a good question.明白了这个问题,Hash不再是问题。下面我就通俗易懂地向你来解答一下这个问题。 现在我要存储4个元素 13 7 14 11 显然,我们可以用数组来存。也就是:a[1] = 13; a[2] = 7; a[3] = 14; a[4] = 11;
当然,我们也可以用Hash来存。下面给出一个简单的Hash存储: 先来确定那个函数。我们就用h(ki) = ki%5;(这个函数不用纠结,我们现在的目的是了解为什么要有这么一个函数)。 对于第一个元素 h(13) = 13%5 = 3; 也就是说13的下标为3;即Hash[3] = 13; 对于第二个元素 h(7) = 7 % 5 = 2; 也就是说7的下标为2; 即Hash[2] = 7; 同理,Hash[4] = 14; Hash[1] = 11;
好了,存现在是存好了。但是,这并没有体现出Hash的妙处,也没有回答刚才的问题。下面就来揭开它神秘的面纱吧。 现在我要你查找11这个元素是否存在。你会怎么做呢?当然,对于数组来说,那是相当的简单,一个for循环就可以了。 也就是说我们要找4次。 下面我们来用Hash找一下。 首先,我们将要找的元素11代入刚才的函数中来映射出它所在的地址单元。也就是h(11) = 11%5 = 1 了。下面我们来比较一下Hash[1]?=11, 这个问题就很简单了。也就是说我们就找了1次。这个就是Hash的妙处了。至此,刚才的问题也就得到了解答。至此,你也就彻底的明白了Hash了。
二、哈希学习
①背景介绍
1、首先介绍一下最近邻搜索:最近邻搜索问题,也叫相似性搜索,近似搜索,是从给定数据库中找到里查询点最近的点集的问题。
给定一个点集,以及一个查询点q,需要找到离q最近的点的集合;在大规模高维度空间的情况下,这个问题就变得非常难,而且大多数算法计算量极大,复杂度很高; 而且一般用近似的最邻近搜索代替;哈希就是解决上述这类问题的主要方法;
哈希学习的目的:通过机器学习机制将数据映射成简洁的二进制串的形式, 同时使得哈希码尽可能地保持原空间中的近邻关系, 即保相似性.(这一点很重要,如果失去了原来的相似性,那么哈希学习也就变得没有意义了) 以下面这幅图为例,原始数据是三幅图像,其中后面这两幅相似度比较高,也就是说在原始空间中从语义层次的距离或者欧氏距离都比较近,映射为哈希码之后,距离也应该更近。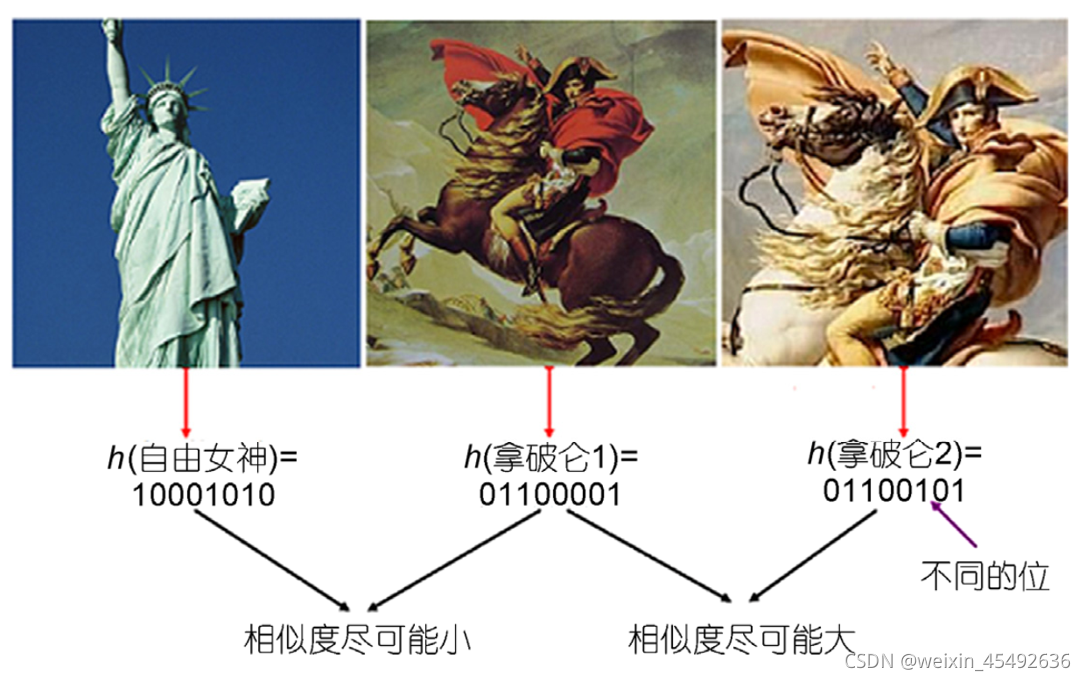
分类:关于哈希的方法主要分为两大类:
1、第一种的代表是局部敏感哈希,这种方法主要是人工设计或者随机生成哈希函数,是一种数据独立的方法;
2、第二种是哈希学习的方法,希望从数据中自动学习出哈希函数,是一种数据依赖的方法;也是现在主流的方法; 显然第二种具有数据依赖性,是一种更有适应性的方法。
②、哈希学习的一般步骤
第一步,:先对原空间的样本进行降维, 得到1个低维空间的实数向量表示; 第二步:对得到的实数向量进行量化(即离散化)得到二进制哈希码;
对于第一步如何降维,我们这里不再做介绍,下面主要介绍一下量化的方法。
四、量化方法
目的:对于一个低维向量把它映射为一个二进制哈希码,并且尽可能的保持原来的相似性。